
von Sebastian Saemann | Jun 24, 2022 | Datenbank, Tutorial
Im Jahr 2010 wurde eine Lösung entwickelt, um die massiven Skalierbarkeitsprobleme von MySQL bei YouTube zu lösen – und somit war Vitess geboren. Später – im Jahr 2018 – wurde das Projekt Teil der Cloud Native Computing Foundation und ist seit 2019 als eines der graduierten Projekte gelistet: Damit befindet es sich in guter Gesellschaft mit anderen prominenten CNCF-Projekten wie Kubernetes, Prometheus und einigen mehr.
Vitess ist ein Open-Source-MySQL-kompatibles Datenbank-Clustering-System für horizontale Skalierung – man könnte auch sagen, es ist eine Sharding Zwischenanwendung für MySQL. Es kombiniert und erweitert viele wichtige SQL-Features mit der Skalierbarkeit einer NoSQL-Datenbank und löst zahlreiche Herausforderungen beim Betrieb gewöhnlicher MySQL-Setups. Mit Vitess wird MySQL massiv skalierbar und hochverfügbar. Vitess ist von Natur aus Cloud-nativ, kann aber auch auf Bare-Metal-Umgebungen betrieben werden.
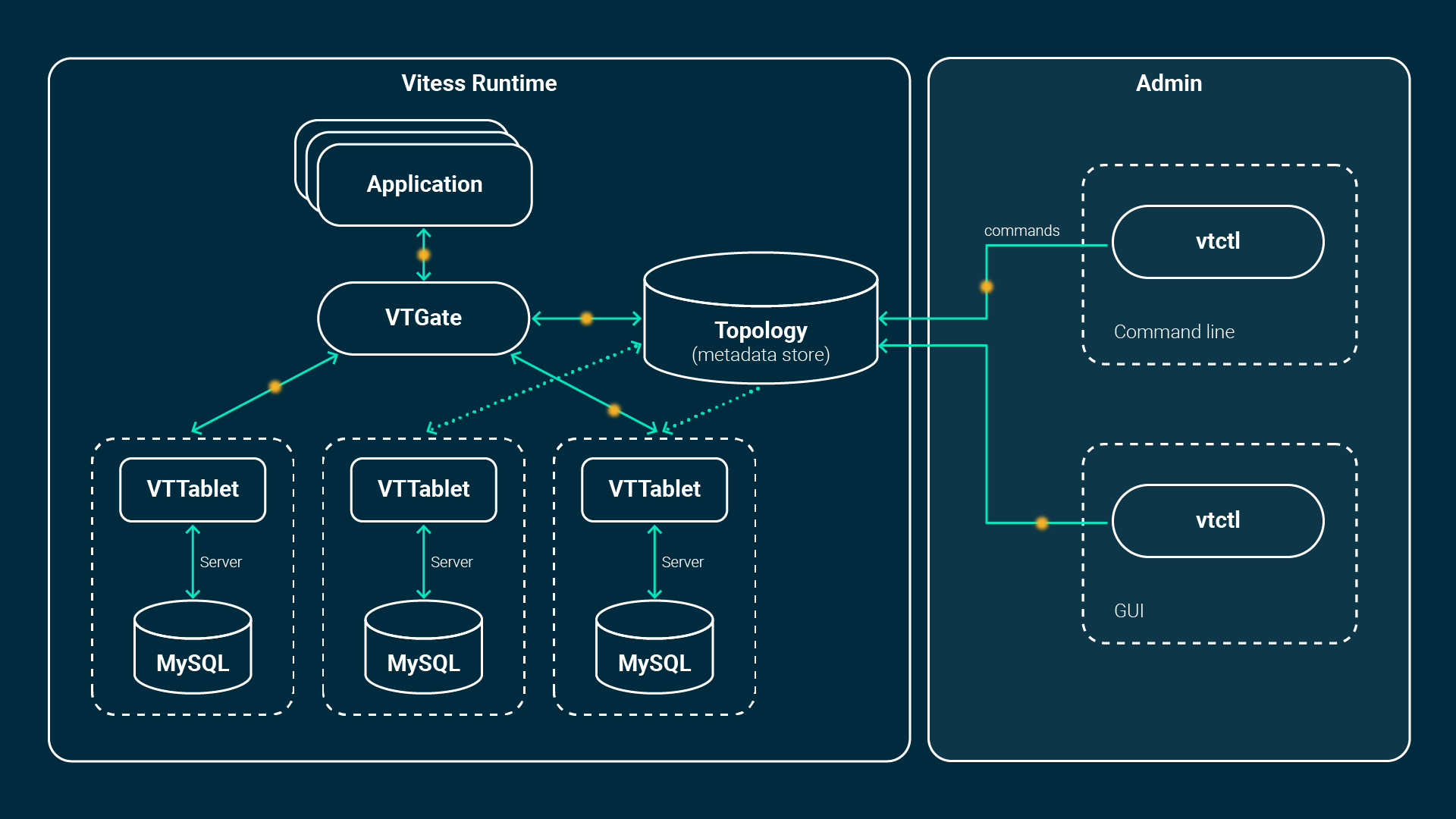
Architektur
Die Architektur besteht aus mehreren zusätzlichen Komponenten wie VTGate, VTTablet, VTctld und einem Topology Service, der von etcd oder zookeeper unterstützt wird. Die Anwendung verbindet sich entweder über die nativen Datenbanktreiber von Vitess oder über das MySQL-Protokoll: Das bedeutet, dass alle MySQL-Clients und Bibliotheken kompatibel sind.
Die Anwendung verbindet sich mit dem so genannten VTGate – einer Art leichtgewichtigem Proxy -, der den Zustand der MySQL-Instanzen (VTTablets) kennt und weiß, wo welche Daten im Falle von Sharded-Datenbanken gespeichert sind. Diese Informationen werden im Topology Service gespeichert. Das VTGate leitet die Abfragen entsprechend an die zugehörigen VTTablets weiter.
Ein Tablet wiederum ist die Kombination aus einem VTTablet-Prozess und der MySQL-Instanz selbst. Es läuft entweder im primären, im Replikations- oder im Nur-Lese-Modus, wenn es gesund ist. Es gibt eine Replikation zwischen einem primären und mehreren Replikas pro Datenbank. Wenn eine Primärinstanz ausfällt, wird eine Replika hochgestuft und Vitess hilft bei der Wiederherstellung. Dies alles kann vollständig automatisiert werden. Neue, zusätzliche oder ausgefallene Replikas werden von Grund auf neu instanziiert. Sie erhalten die Daten des letzten verfügbaren Backups und werden an die Replikation angeschlossen. Sobald die Daten verfügbar sind, sind sie Teil des Clusters und VTGate leitet Queries an sie weiter.
Philosophie der Skalierbarkeit
Vitess versucht, kleine Instanzen zu betreiben, die nicht mehr als 250 GB an Daten enthalten. Wenn Ihre Datenbank größer wird, muss sie in mehrere Instanzen aufgeteilt werden. Dieser Ansatz hat mehrere gute betriebliche Vorteile. Im Falle des Ausfalls einer Instanz, kann diese mit weniger Daten viel schneller wiederhergestellt werden. Die Wiederherstellungszeit wird durch die schnellere Übertragung von Sicherungskopien verkürzt. Auch die Replikation verläuft in der Regel reibungsloser und mit weniger Verzögerung. Das Verschieben von Instanzen und deren Platzierung auf verschiedenen Nodes für eine bessere Ressourcennutzung, ist ebenfalls ein Vorteil.
Durch die Replikation wird die Haltbarkeit der Daten gewährleistet. Ausfälle von bestimmten Fehlerdomains bzw. Ausfälle generell, sind ganz normal. In Cloud-nativen Umgebungen ist es noch normaler, dass Nodes und Pods entleert oder neu erstellt werden und man versucht, so flexibel wie möglich auf solche Ereignisse zu reagieren. Vitess ist genau dafür konzipiert und passt mit seinen vollautomatisierten Wiederherstellungs- und Reparenting-Fähigkeiten perfekt zu einer Cloud-nativen Umgebung wie Kubernetes.
Darüber hinaus ist Vitess dafür gedacht, über Rechenzentren, Regionen oder Verfügbarkeitszonen hinweg betrieben zu werden. Jede Domain hat ihr eigenes VTGate und einen eigenen Pool von Tablets. Dieses Konzept wird als „Cells in Vitess“ bezeichnet. Wir bei NETWAYS Web Services verteilen die Replikas gleichmäßig über unsere Verfügbarkeitszonen, um einen kompletten Ausfall einer Zone zu überstehen. Es wäre auch möglich, Replikas in geografischen Regionen zu betreiben, um die Latenzzeit und die Erfahrung für Kunden im Ausland zu verbessern.
Zusätzliche Features
Neben der Cloud-nativen Natur und den Möglichkeiten der endlosen Skalierbarkeit, gibt es noch weitere praktische und clevere Funktionen.
- Connection pooling und Deduplication
Normalerweise muss MySQL für jede Verbindung etwas (~ 256KB – 3MB) Speicher zuweisen. Dieser Speicher ist nur für die Verbindungen und nicht für die Beschleunigung von Queries gedacht. Vitess erstellt stattdessen sehr leichtgewichtige Verbindungen, indem es den Concurrency Support von Go nutzt. Diese Frontend-Verbindungen werden dann auf weniger Verbindungen zu den MySQL-Instanzen gepooled, so dass es möglich ist, Tausende von Verbindungen reibungslos und effizient zu verarbeiten. Außerdem werden identische Queries in-flight registriert und zurückgehalten, sodass nur eine Anfrage auf die Datenbank trifft.
- Query- und Transaction Protection
Hattest Du schon mal das Bedürfnis, lang laufende Queries zu beenden, die Deine Datenbank lahmgelegt haben? Vitess begrenzt die Anzahl der gleichzeitigen Transaktionen und setzt angemessene Timeouts für jede. Queries, die zu lange dauern, werden abgebrochen. Auch schlecht geschriebene Queries ohne LIMITS werden umgeschrieben und begrenzt, bevor sie dem System schaden können.
- Sharding
Die integrierten Sharding-Funktionen ermöglichen das Wachstum der Datenbank in Form von Sharding, ohne dass zusätzliche Application Logic hinzugefügt werden muss.
- Performance Monitoring
Mit den Tools zur Leistungsanalyse kannst Du die Leistung Deiner Datenbank überwachen, diagnostizieren und analysieren.
- VReplikation und Workflows
VReplikation ist ein Schlüsselmechanismus von Vitess. Bei der VReplikation werden Ereignisse des Binlogs vom Sender zu einem Empfänger gestreamt. Workflows sind – wie der Name schon sagt – Abläufe zur Erledigung bestimmter Queries: So kann zum Beispiel eine laufende Production Table nahezu ohne Ausfallzeit auf eine andere Datenbankinstanz verschoben werden („MoveTable„). Auch das Streaming einer Teilmenge von Daten in eine andere Instanz kann mit diesem Konzept durchgeführt werden. Eine „materialisierte Ansicht“ ist praktisch, wenn Du Daten zusammenführen musst, die Tabellen aber auf verschiedenen Instanzen verteilt sind.
Fazit
Vitess ist ein sehr leistungsfähiges und cleveres Stück Software! Um genau zu sagen, ist es eine Software, die von Hyperscalern verwendet wird, aber nun für die breite Masse zugänglich gemacht wurde und somit für alle verfügbar. Wenn Du mehr darüber erfahren möchtest, werden wir zukünftig regelmäßig weitere Tutorials veröffentlichen, die fortgeschrittene Themen abdecken werden. Die Dokumentation von vitess.io ist auch eine gute Quelle, um mehr zu erfahren. Wenn Du es selbst mal ausprobieren willst, gibt es mehrere Möglichkeiten: Der bequemste Weg ist, unser Managed Database Produkt zu verwenden und auf unsere Erfahrung zu vertrauen.

von Sebastian Saemann | Jul 8, 2020 | Kubernetes, Tutorial
Seit dieser Woche können unsere Kunden das „Nodegroup-Feature“ für ihre NWS Managed Kubernetes Cluster nutzen. Was sind Nodegroups und was kann ich damit bewerkstelligen? Das und mehr erklärt unser siebter Blogpost der Serie.
Was sind Nodegroups?
Mit Nodegroups ist es möglich, mehrere Kubernetes-Node-Gruppen zu erstellen und unabhängig voneinander zu verwalten. Eine Nodegroup beschreibt eine Anzahl von virtuellen Maschinen, die als Gruppe diverse Attribute besitzt. Im Wesentlichen wird bestimmt, welches Flavor – also welches VM-Modell – innerhalb dieser Gruppe verwendet werden soll. Es sind aber auch andere Attribute wählbar. Jede Nodegroup kann unabhängig von den anderen jederzeit vertikal skaliert werden.
Wieso Nodegroups?
Nodegroups eignen sich, um Pods gezielt auf bestimmten Nodes auszuführen. Es ist zum Beispiel möglich, eine Gruppe mit dem „Availability-Zone“-Attribut zu definieren. Neben der bereits bestehenden „default-nodegroup“, die die Nodes relativ willkürlich über alle Verfügbarkeitszonen verteilt, können weitere Nodegroups erstellt werden, die jeweils nur in einer Verfügbarkeitszone explizit gestartet werden. Innerhalb des Kubernetes Clusters kann man seine Pods in die entsprechenden Verfügbarkeitszonen bzw. Node-Gruppen aufteilen. Ein weiteres mögliches Szenario ist es, seine Nodegroups nach schnellen und langsameren VMs einzuteilen. Services und Anwendungen, die keine besonderen Ansprüche erheben, können der langsameren und somit meist auch günstigeren Nodegroup zugewiesen werden, während Pods mit mehr Anspruch ausschließlich auf schnellen Nodes betrieben werden. Der eigenen Fantasie und den eigenen Voraussetzungen wird durch die gewonnene Flexibilität Genüge getan. Neue Nodegroups lassen sich bequem über das NWS Web-Interface anlegen: Existierende Nodegroups anzeigen  Im ersten Bild sieht man unseren exemplarischen Kubernetes Cluster „k8s-ses“. Dieser verfügt aktuell über zwei Nodegroups: „default-master“ und „default-worker“. Neue Nodegroup erstellen
Im ersten Bild sieht man unseren exemplarischen Kubernetes Cluster „k8s-ses“. Dieser verfügt aktuell über zwei Nodegroups: „default-master“ und „default-worker“. Neue Nodegroup erstellen 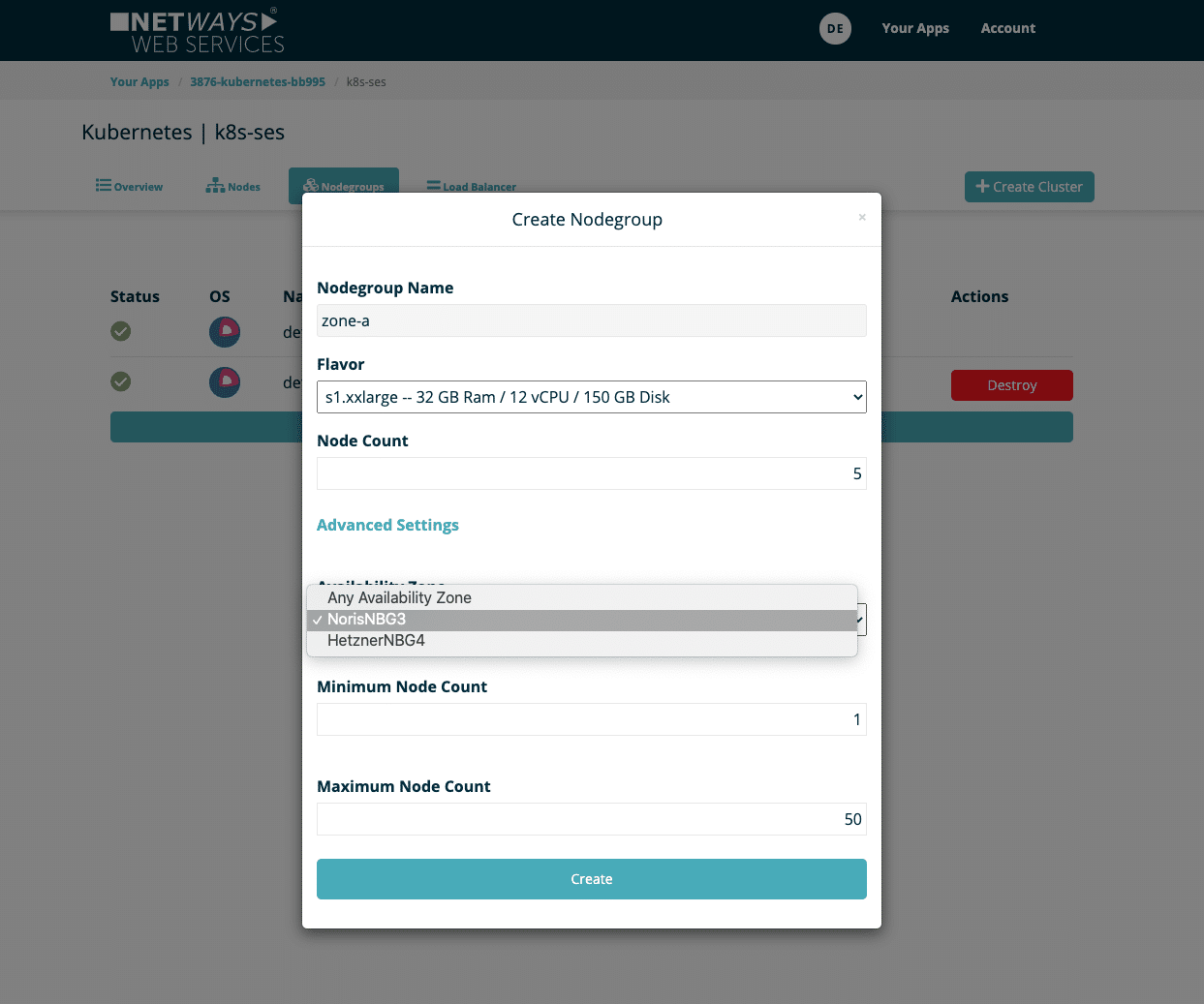 Eine neue Nodegroup lässt sich über den Dialog „Create Nodegroup“ mit folgenden Optionen erstellen:
Eine neue Nodegroup lässt sich über den Dialog „Create Nodegroup“ mit folgenden Optionen erstellen:
- Name: Name der Nodegroup, der später als Label für K8s genutzt werden kann
- Flavor: Größe der eingesetzten virtuellen Maschinen
- Node Count: Anzahl der initialen Nodes, kann später jederzeit vergrößert und verkleinert werden.
- Availability Zone: eine spezifische Verfügbarkeitszone
- Minimum Node Count: Die Nodegroup darf nicht weniger Nodes als den definierten Wert beinhalten.
- Maximium Node Count: Die Nodegroup kann auf nicht mehr als die angegebene Anzahl Nodes anwachsen.
Die zwei letzten Optionen sind insbesondere für AutoScaling ausschlaggebend und begrenzen somit den automatischen Mechanismus. 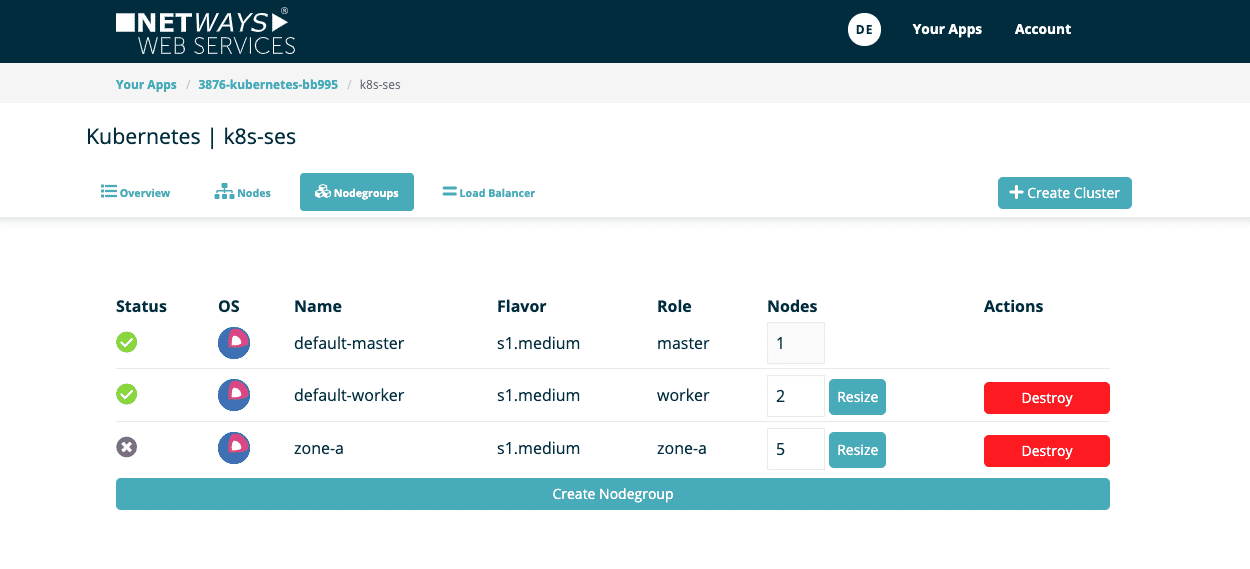 Anschließend sieht man die neue Nodegroup in der Übersicht. Die Provisionierung der Nodes dauert nur wenige Minuten. Jede Gruppe lässt sich zudem individuell in ihrer Anzahl jederzeit verändern oder auch wieder entfernen.
Anschließend sieht man die neue Nodegroup in der Übersicht. Die Provisionierung der Nodes dauert nur wenige Minuten. Jede Gruppe lässt sich zudem individuell in ihrer Anzahl jederzeit verändern oder auch wieder entfernen.
Nodegroups im Kubernetes Cluster verwenden
Innerhalb des Kubernetes Clusters kann man seine neuen Nodes, nachdem sie fertig provisioniert wurden und einsatzbereit sind, sehen.
kubectl get nodes -L magnum.openstack.org/role
NAME STATUS ROLES AGE VERSION ROLE
k8s-ses-6osreqalftvz-master-0 Ready master 23h v1.18.2 master
k8s-ses-6osreqalftvz-node-0 Ready <none> 23h v1.18.2 worker
k8s-ses-6osreqalftvz-node-1 Ready <none> 23h v1.18.2 worker
k8s-ses-zone-a-vrzkdalqjcud-node-0 Ready <none> 31s v1.18.2 zone-a
k8s-ses-zone-a-vrzkdalqjcud-node-1 Ready <none> 31s v1.18.2 zone-a
k8s-ses-zone-a-vrzkdalqjcud-node-2 Ready <none> 31s v1.18.2 zone-a
k8s-ses-zone-a-vrzkdalqjcud-node-3 Ready <none> 31s v1.18.2 zone-a
k8s-ses-zone-a-vrzkdalqjcud-node-4 Ready <none> 31s v1.18.2 zone-a
Die Node-Labels magnum.openstack.org/nodegroup und magnum.openstack.org/role tragen bei Nodes, die der Gruppe zugehörig sind, den Namen der Nodegroup. Zudem gibt es noch das Label topology.kubernetes.io/zone, das den Namen der Availability Zone trägt. Mit Hilfe des nodeSelectors können Deployments oder Pods den Nodes bzw. Gruppen zugeordnet werden:
nodeSelector:
magnum.openstack.org/role: zone-a
Du möchtest Dich selbst davon überzeugen, dass Managed Kubernetes bei NWS so einfach ist? Dann probiere es gleich aus auf: https://nws.netways.de/de/kubernetes/

von Sebastian Saemann | Mai 27, 2020 | Kubernetes, Tutorial
Monitoring – für viele eine gewisse Hass-Liebe. Die einen mögen es, die anderen verteufeln es. Ich gehöre zu denen, die es meist eher verteufeln, dann aber meckern, wenn man gewisse Metriken und Informationen nicht einsehen kann. Unabhängig der persönlichen Neigungen zu diesem Thema ist der Konsens aller jedoch sicher: Monitoring ist wichtig und ein Setup ist auch nur so gut wie sein dazugehöriges Monitoring. Wer seine Anwendungen auf Basis von Kubernetes entwickeln und betreiben will, stellt sich zwangsläufig früher oder später die Frage, wie man diese Anwendungen und den Kubernetes Cluster überwachen kann. Eine Variante ist der Einsatz der Monitoringlösung Prometheus; genauer gesagt durch die Verwendung des Kubernetes Prometheus Operators. Eine beispielhafte und funktionale Lösung wird in diesem Blogpost gezeigt.
Kubernetes Operator
Kubernetes Operators sind kurz erklärt Erweiterungen, mit denen sich eigene Ressourcentypen erstellen lassen. Neben den Standard-Kubernetes-Ressourcen wie Pods, DaemonSets, Services usw. kann man mit Hilfe eines Operators auch eigene Ressourcen nutzen. In unserem Beispiel kommen neu hinzu: Prometheus, ServiceMonitor und weitere. Operators sind dann von großem Nutzen, wenn man für seine Anwendung spezielle manuelle Tasks ausführen muss, um sie ordentlich betreiben zu können. Das könnten beispielsweise Datenbank-Schema-Updates bei Versionsupdates sein, spezielle Backupjobs oder das Steuern von Ereignissen in verteilten Systemen. In der Regel laufen Operators – wie gewöhnliche Anwendungen auch – als Container innerhalb des Clusters.
Wie funktioniert es?
Die Grundidee ist, dass mit dem Prometheus Operator ein oder viele Prometheus-Instanzen gestartet werden, die wiederum durch den ServiceMonitor dynamisch konfiguriert werden. Das heißt, es kann an einem gewöhnlichen Kubernetes Service mit einem ServiceMonitor angedockt werden, der wiederum ebenfalls die Endpoints auslesen kann und die zugehörige Prometheus-Instanz entsprechend konfiguriert. Verändern sich der Service respektive die Endpoints, zum Beispiel in der Anzahl oder die Endpoints haben neue IPs, erkennt das der ServiceMonitor und konfiguriert die Prometheus-Instanz jedes Mal neu. Zusätzlich kann über Configmaps auch eine manuelle Konfiguration vorgenommen werden.
Voraussetzungen
Voraussetzung ist ein funktionierendes Kubernetes Cluster. Für das folgende Beispiel verwende ich einen NWS Managed Kubernetes Cluster in der Version 1.16.2.
Installation Prometheus Operator
Zuerst wird der Prometheus-Operator bereitgestellt. Es werden ein Deployment, eine benötigte ClusterRole mit zugehörigem ClusterRoleBinding und einem ServiceAccount definiert.
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
app.kubernetes.io/component: controller
app.kubernetes.io/name: prometheus-operator
app.kubernetes.io/version: v0.38.0
name: prometheus-operator
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus-operator
subjects:
- kind: ServiceAccount
name: prometheus-operator
namespace: default
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
app.kubernetes.io/component: controller
app.kubernetes.io/name: prometheus-operator
app.kubernetes.io/version: v0.38.0
name: prometheus-operator
rules:
- apiGroups:
- apiextensions.k8s.io
resources:
- customresourcedefinitions
verbs:
- create
- apiGroups:
- apiextensions.k8s.io
resourceNames:
- alertmanagers.monitoring.coreos.com
- podmonitors.monitoring.coreos.com
- prometheuses.monitoring.coreos.com
- prometheusrules.monitoring.coreos.com
- servicemonitors.monitoring.coreos.com
- thanosrulers.monitoring.coreos.com
resources:
- customresourcedefinitions
verbs:
- get
- update
- apiGroups:
- monitoring.coreos.com
resources:
- alertmanagers
- alertmanagers/finalizers
- prometheuses
- prometheuses/finalizers
- thanosrulers
- thanosrulers/finalizers
- servicemonitors
- podmonitors
- prometheusrules
verbs:
- '*'
- apiGroups:
- apps
resources:
- statefulsets
verbs:
- '*'
- apiGroups:
- ""
resources:
- configmaps
- secrets
verbs:
- '*'
- apiGroups:
- ""
resources:
- pods
verbs:
- list
- delete
- apiGroups:
- ""
resources:
- services
- services/finalizers
- endpoints
verbs:
- get
- create
- update
- delete
- apiGroups:
- ""
resources:
- nodes
verbs:
- list
- watch
- apiGroups:
- ""
resources:
- namespaces
verbs:
- get
- list
- watch
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app.kubernetes.io/component: controller
app.kubernetes.io/name: prometheus-operator
app.kubernetes.io/version: v0.38.0
name: prometheus-operator
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/component: controller
app.kubernetes.io/name: prometheus-operator
template:
metadata:
labels:
app.kubernetes.io/component: controller
app.kubernetes.io/name: prometheus-operator
app.kubernetes.io/version: v0.38.0
spec:
containers:
- args:
- --kubelet-service=kube-system/kubelet
- --logtostderr=true
- --config-reloader-image=jimmidyson/configmap-reload:v0.3.0
- --prometheus-config-reloader=quay.io/coreos/prometheus-config-reloader:v0.38.0
image: quay.io/coreos/prometheus-operator:v0.38.0
name: prometheus-operator
ports:
- containerPort: 8080
name: http
resources:
limits:
cpu: 200m
memory: 200Mi
requests:
cpu: 100m
memory: 100Mi
securityContext:
allowPrivilegeEscalation: false
nodeSelector:
beta.kubernetes.io/os: linux
securityContext:
runAsNonRoot: true
runAsUser: 65534
serviceAccountName: prometheus-operator
---
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
app.kubernetes.io/component: controller
app.kubernetes.io/name: prometheus-operator
app.kubernetes.io/version: v0.38.0
name: prometheus-operator
namespace: default
---
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/component: controller
app.kubernetes.io/name: prometheus-operator
app.kubernetes.io/version: v0.38.0
name: prometheus-operator
namespace: default
spec:
clusterIP: None
ports:
- name: http
port: 8080
targetPort: http
selector:
app.kubernetes.io/component: controller
app.kubernetes.io/name: prometheus-operator
kubectl apply -f 00-prometheus-operator.yaml
clusterrolebinding.rbac.authorization.k8s.io/prometheus-operator created
clusterrole.rbac.authorization.k8s.io/prometheus-operator created
deployment.apps/prometheus-operator created
serviceaccount/prometheus-operator created
service/prometheus-operator created
Role Based Access Control
Zusätzlich werden entsprechende Role Based Access Control (RBAC) Policies benötigt. Die Prometheus-Instanzen (StatefulSets), gestartet durch den Prometheus-Operator, starten Container unter dem gleichnamigen ServiceAccount „Prometheus“. Dieser Account benötigt lesenden Zugriff auf die Kubernetes API, um später die Informationen über Services und Endpoints auslesen zu können.
Clusterrole
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRole
metadata:
name: prometheus
rules:
- apiGroups: [""]
resources:
- nodes
- services
- endpoints
- pods
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources:
- configmaps
verbs: ["get"]
- nonResourceURLs: ["/metrics"]
verbs: ["get"]
kubectl apply -f 01-clusterrole.yaml
clusterrole.rbac.authorization.k8s.io/prometheus created
ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
subjects:
- kind: ServiceAccount
name: prometheus
namespace: default
kubectl apply -f 01-clusterrolebinding.yaml
clusterrolebinding.rbac.authorization.k8s.io/prometheus created
ServiceAccount
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus
kubectl apply -f 01-serviceaccount.yaml
serviceaccount/prometheus created
Monitoring von Kubernetes Cluster Nodes
Es gibt diverse Metriken, die aus einem Kubernetes Cluster ausgelesen werden können. In diesem Beispiel wird zunächst nur auf die Systemwerte der Kubernetes Nodes eingegangen. Für die Überwachung der Kubernetes Cluster Nodes bietet sich die ebenfalls vom Prometheus-Projekt bereitgestellte Software „Node Exporter“ an. Diese liest sämtliche Metriken über CPU, Memory sowie I/O aus und stellt diese Werte unter /metrics zum Abruf bereit. Prometheus selbst „crawlet“ diese Metriken später in regelmäßigen Abständen. Ein DaemonSet steuert, dass jeweils ein Container/Pod auf einem Kubernetes Node gestartet wird. Mit Hilfe des Services werden alle Endpoints unter einer Cluster IP zusammengefasst.
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-exporter
spec:
selector:
matchLabels:
app: node-exporter
template:
metadata:
labels:
app: node-exporter
name: node-exporter
spec:
hostNetwork: true
hostPID: true
containers:
- image: quay.io/prometheus/node-exporter:v0.18.1
name: node-exporter
ports:
- containerPort: 9100
hostPort: 9100
name: scrape
resources:
requests:
memory: 30Mi
cpu: 100m
limits:
memory: 50Mi
cpu: 200m
volumeMounts:
- name: proc
readOnly: true
mountPath: /host/proc
- name: sys
readOnly: true
mountPath: /host/sys
volumes:
- name: proc
hostPath:
path: /proc
- name: sys
hostPath:
path: /sys
---
apiVersion: v1
kind: Service
metadata:
labels:
app: node-exporter
annotations:
prometheus.io/scrape: 'true'
name: node-exporter
spec:
ports:
- name: metrics
port: 9100
protocol: TCP
selector:
app: node-exporter
kubectl apply -f 02-exporters.yaml
daemonset.apps/node-exporter created
service/node-exporter created
Service Monitor
Mit der sogenannten Third Party Ressource „ServiceMonitor“, bereitgestellt durch den Prometheus Operator, ist es möglich, den zuvor gestarteten Service, in unserem Fall node-exporter, für die zukünftige Überwachung aufzunehmen. Die TPR selbst erhält ein Label team: frontend, das wiederum später als Selector für die Prometheus-Instanz genutzt wird.
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: node-exporter
labels:
team: frontend
spec:
selector:
matchLabels:
app: node-exporter
endpoints:
- port: metrics
kubectl apply -f 03-service-monitor-node-exporter.yaml
servicemonitor.monitoring.coreos.com/node-exporter created
Prometheus-Instanz
Es wird eine Prometheus-Instanz definiert, die nun alle Services anhand der Labels sammelt und von deren Endpoints die Metriken bezieht.
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
name: prometheus
spec:
serviceAccountName: prometheus
serviceMonitorSelector:
matchLabels:
team: frontend
resources:
requests:
memory: 400Mi
enableAdminAPI: false
kubectl apply -f 04-prometheus-service-monitor-selector.yaml
prometheus.monitoring.coreos.com/prometheus created
Prometheus Service
Die gestartete Prometheus-Instanz wird mit einem Service-Objekt exponiert. Nach einer kurzen Wartezeit ist ein Cloud-Loadbalancer gestartet, der aus dem Internet erreichbar ist und Anfragen zu unserer Prometheus-Instanz durchreicht.
apiVersion: v1
kind: Service
metadata:
name: prometheus
spec:
type: LoadBalancer
ports:
- name: web
port: 9090
protocol: TCP
targetPort: web
selector:
prometheus: prometheus
kubectl apply -f 05-prometheus-service.yaml
service/prometheus created
kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
prometheus LoadBalancer 10.254.146.112 pending 9090:30214/TCP 58s
Sobald die externe IP-Adresse verfügbar ist, kann diese über http://x.x.x.x:9090/targets aufgerufen werden und man sieht alle seine Kubernetes Nodes, deren Metriken ab sofort regelmäßig abgerufen werden. Kommen später weitere Nodes hinzu, so werden diese automatisch mit aufgenommen bzw. wieder entfernt. 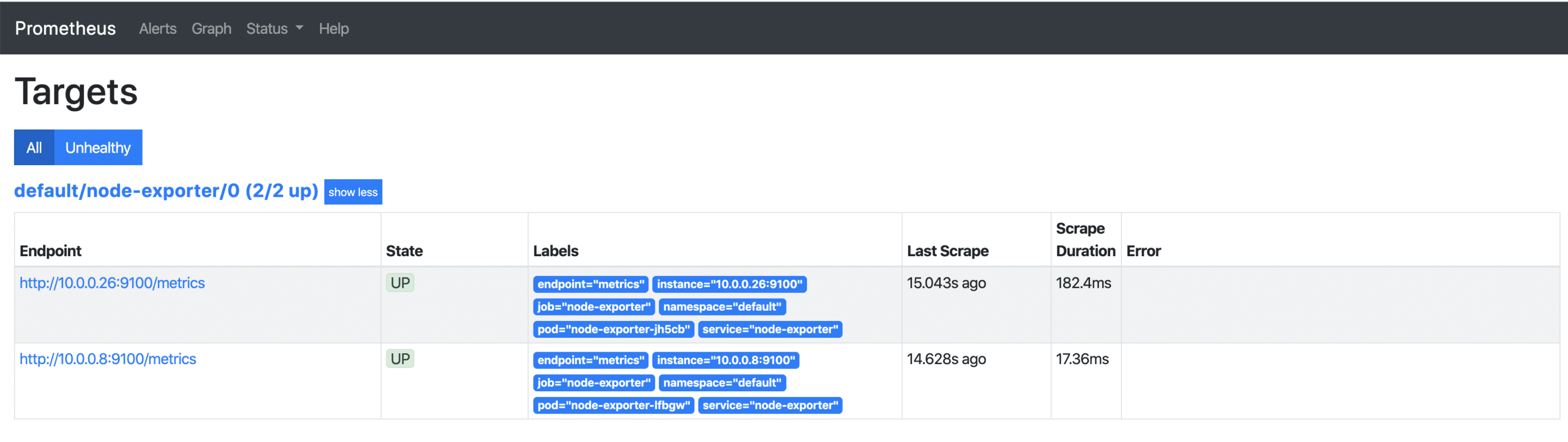
Visualisierung mit Grafana
Die gesammelten Metriken, lassen sich leicht und ansprechend mit Grafana visualisieren. Grafana ist ein Analyse-Tool, das diverse Datenbackends unterstützt.
apiVersion: v1
kind: Service
metadata:
name: grafana
spec:
# type: LoadBalancer
ports:
- port: 3000
targetPort: 3000
selector:
app: grafana
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: grafana
name: grafana
spec:
selector:
matchLabels:
app: grafana
replicas: 1
revisionHistoryLimit: 2
template:
metadata:
labels:
app: grafana
spec:
containers:
- image: grafana/grafana:latest
name: grafana
imagePullPolicy: Always
ports:
- containerPort: 3000
env:
- name: GF_AUTH_BASIC_ENABLED
value: "false"
- name: GF_AUTH_ANONYMOUS_ENABLED
value: "true"
- name: GF_AUTH_ANONYMOUS_ORG_ROLE
value: Admin
- name: GF_SERVER_ROOT_URL
value: /api/v1/namespaces/default/services/grafana/proxy/
kubectl apply -f grafana.yaml
service/grafana created
deployment.apps/grafana created
kubectl proxy
Starting to serve on 127.0.0.1:8001
Sobald die Proxy-Verbindung durch kubectl verfügbar ist, kann die gestartete Grafana-Instanz via http://localhost:8001/api/v1/namespaces/default/services/grafana/proxy/ im Browser aufgerufen werden. Damit die in Prometheus vorliegenden Metriken jetzt auch visuell ansprechend dargestellt werden können, sind nur noch wenige weitere Schritte notwendig. Zuerst wird eine neue Data-Source vom Typ Prometheus angelegt. Dank des kuberneteseigenen und -internen DNS lautet die URL http://prometheus.default.svc:9090. Das Schema ist servicename.namespace.svc. Alternativ kann natürlich auch die Cluster-IP verwendet werden. 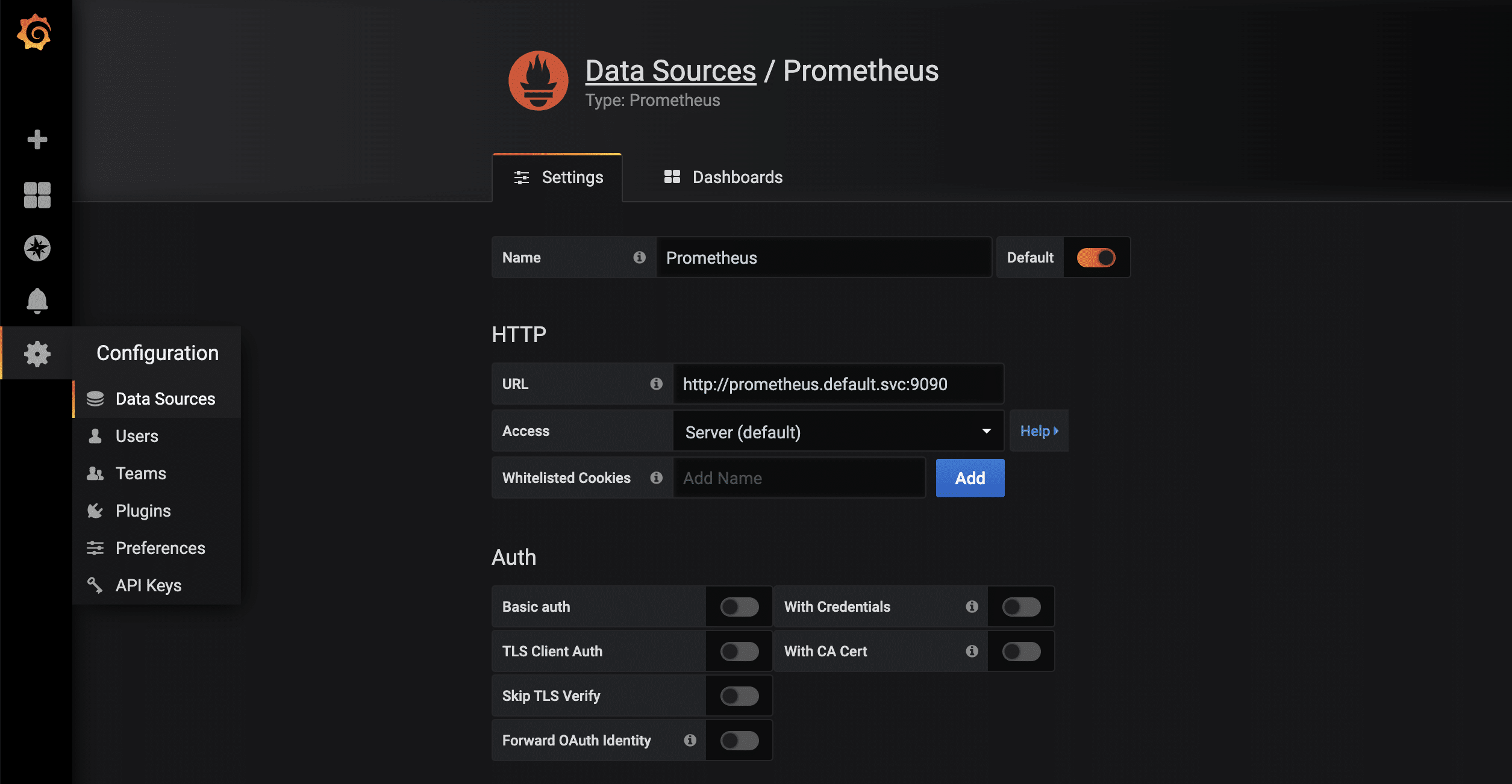 Für die gesammelten Metriken des node-exporters gibt es bereits ein sehr vollständiges Grafana-Dashboard, das sich über die Import-Funktion importieren lässt. Die ID des Dashboards ist 1860.
Für die gesammelten Metriken des node-exporters gibt es bereits ein sehr vollständiges Grafana-Dashboard, das sich über die Import-Funktion importieren lässt. Die ID des Dashboards ist 1860. 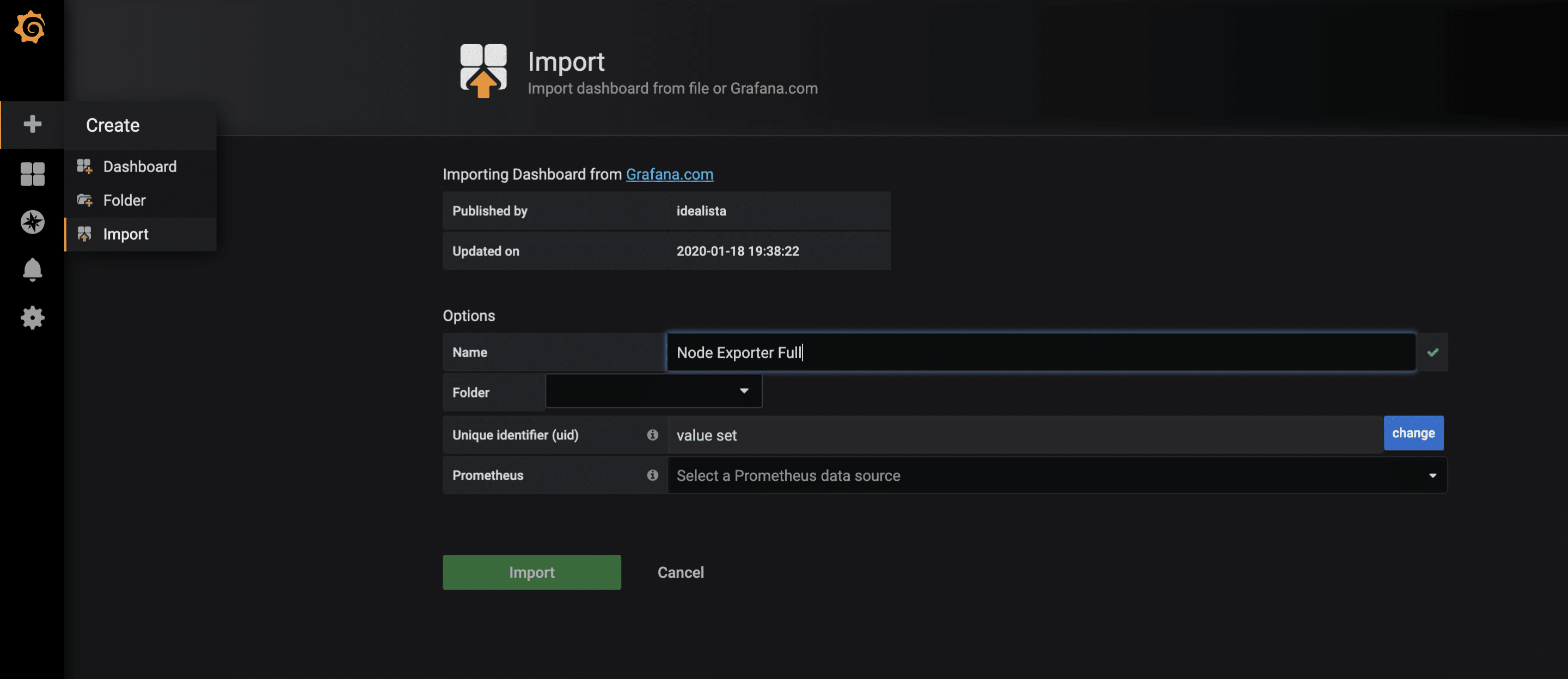 Nach dem erfolgreichem Import des Dashboards können jetzt die Metriken begutachtet werden.
Nach dem erfolgreichem Import des Dashboards können jetzt die Metriken begutachtet werden. 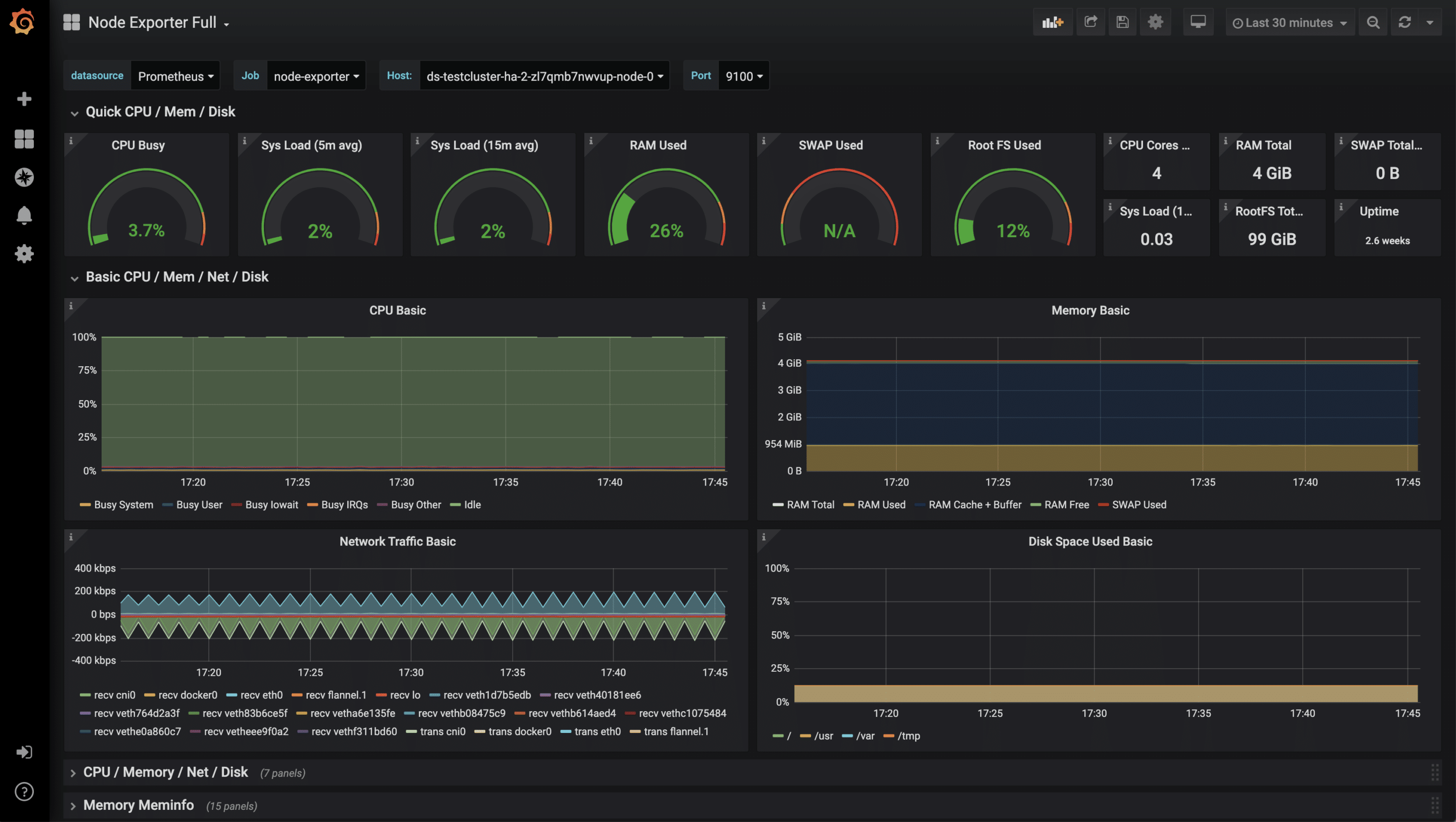
Monitoring weiterer Anwendungen
Neben diesen eher technischen Statistiken sind auch weitere Metriken der eigenen Anwendungen möglich, beispielsweise HTTP Requests, SQL Queries, Business-Logik und vieles mehr. Hier werden einem durch das sehr flexible Datenformat kaum Grenzen gesetzt. Um seine eigenen Metriken zu sammeln, gibt es wie immer mehrere Lösungsansätze. Einer davon ist, seine Anwendung mit einem /metrics Endpunkt auszustatten. Manche Frameworks wie z.B. Ruby on Rails haben bereits brauchbare Erweiterungen. Ein weiterer Ansatz sind sogenannte Sidecars. Ein Sidecar ist ein zusätzlicher Container, der neben dem eigentlichen Anwendungscontainer mitläuft. Beide zusammen ergeben einen Pod, der sich Namespace, Netzwerk etc. teilt. In dem Sidecar läuft dann Code, der die Anwendung prüft und die Ergebnisse als parsebare Werte für Prometheus zur Verfügung stellt. Im Wesentlichen können beide Ansätze, wie im oben gezeigten Beispiel, mit dem Prometheus Operator verknüpft werden.

von Sebastian Saemann | Apr 29, 2020 | Kubernetes, Tutorial
Managed Kubernetes vs. Kubernetes On-Premises – setze ich auf ein Managed Kubernetes-Angebot oder betreibe ich Kubernetes besser selbst? Für manche stellt sich diese Frage natürlich erst gar nicht, da es vom Konzern oder dem eigenen Betrieb strategisch vorgegeben wird. Für alle anderen sollen die folgenden Zeilen helfen, einen Überblick über die Vor- und Nachteile von Managed Kubernetes und On-Premises zu erhalten und auf technische Herausforderungen hinzuweisen.
Wieso Kubernetes?
Um auch Leser abzuholen, die noch nicht ganz soweit sind, möchte ich einleitend nicht unerwähnt lassen, wieso es eigentlich so einen Hype um Kubernetes gibt und warum man sich unbedingt damit befassen sollte. Kubernetes ist klarer Sieger im Kampf um die Container-Orchestrierung. Dabei geht es um viel mehr, als nur Container auf einer Vielzahl von Nodes zu starten. Es ist die Art und Weise, wie die Anwendung von der Infrastruktur entkoppelt und abstrahiert wird. Textbasierte und versionierbare Konfigurationsdateien, ein ziemlich komplettes Featureset, das Ökosystem der Cloud Native Computing Foundation und andere Third-Party-Integrationen sind aktuell ein Garant für den Erfolg des Frameworks. Kein Wunder, dass es derzeit – trotz relativ steiler Lernkurve – „Developer’s Darling“ ist. Kubernetes versteht sich selbst als „First-Class-Citizen“ der Cloud. Mit Cloud sind hier die Infrastructure as a Service-Angebote der Hyperscaler wie AWS, Azure und Google, aber natürlich auch anderer Hoster wie beispielsweise NETWAYS gemeint. Auf Basis dieser bereits bestehenden IaaS-Infrastruktur fühlt sich Kubernetes besonders wohl, denn es werden zum Beispiel Infrastrukturdienste für Storage und Netzwerk wiederverwendet. Das besondere an Kubernetes ist zudem, dass es „cloud-agnostic“ ist. Das bedeutet, die eingesetzte Cloud wird abstrahiert und man ist vom Cloud-Dienstleister unabhängig. Ebenfalls sind Multi-Cloud-Strategien möglich. In unserem Webinar und unserer Kubernetes-Blogserie wird der Einstieg in Kubernetes und dessen Möglichkeiten gezeigt und erklärt.
Managed Kubernetes
Der einfachste Weg zu einem funktionalen Kubernetes Cluster ist sicherlich, die Verwendung eines Managed Kubernetes-Angebots. Managed Kubernetes-Angebote sind nach nur wenigen Klicks und somit in nur wenigen Minuten einsatzbereit und beinhalten in der Regel eine betreute Kubernetes Control-Plane und zugehörige Nodes. Als Kunde konsumiert man eine wahlweise hochverfügbare Kubernetes API, über die letztendlich das Kubernetes Cluster bedient wird. Der Anbieter kümmert sich anschließend um Updates, Verfügbarkeit und Betrieb des K8s-Clusters. Bezahlt wird nach eingesetzten und verwendeten Cloud-Ressourcen. Im Abrechnungsmodell gibt es nur marginale Unterschiede. Manche Anbieter werben mit einer kostenfreien Control-Plane, dafür kosten dann die eingesetzten VMs wiederum mehr. Die technischen Features sind umfassend, die Unterschiede zwischen den Angeboten aber eher minimal. Es gibt Unterschiede in der eingesetzten Kubernetes-Version, der Anzahl von Verfügbarkeitszonen und Regionen, der Möglichkeit für High-Availability-Cluster und Auto-Scaling oder ob zum Beispiel eine aktivierte Kubernetes RBAC-Implementation zum Einsatz kommt. Der echte Vorteil eines Managed Kubernetes-Angebots ist, dass man sofort starten kann, kein operatives Datacenter- und Kubernetes-Fachwissen benötigt und sich auf die Expertise des jeweiligen Anbieters stützen kann.
Kubernetes On-Premises
Im totalen Kontrast steht dazu die Variante, sein Kubernetes bei sich im Rechenzentrum selbst zu betreiben. Um im eigenen Rechenzentrum eine cloudähnliche Funktionalität zu erreichen, müssten die Managed Kubernetes-Lösungen weitestgehend nachgebaut werden. Das hat es durchaus in sich – soviel sei vorab verraten. Wer Glück hat, betreibt bereits einige notwendige Komponenten. Technisch gibt es nämlich einige Herausforderungen:
Für das Deployment eines oder mehrerer Kubernetes Cluster und zur Gewährleistung der Konsistenz, ist es ratsam – wenn nicht sogar zwingend notwendig – einen automatischen Deployment-Prozess einzurichten, sprich Configuration Management mit z.B. Ansible oder Puppet in Kombination mit dem Bootstrapping-Tool kubeadm. Alternativ gibt es Projekte wie kubespray, die mit Ansible Playbooks Kubernetes Cluster bereitstellen können.
Neben dem eigentlichen Netzwerk, in dem sich die Nodes befinden, bildet Kubernetes innerhalb des Clusters ein zusätzliches Netzwerk. Eine Herausforderung ist die Wahl des passenden Container Network Interfaces. Das Verständnis für Lösungen, die Technologien wie VXLAN oder BGP einsetzen, ist ebenfalls zwingend erforderlich und hilfreich. Zusätzlich gibt es eine Besonderheit für Ingress-Traffic, der in das Cluster-Netzwerk geleitet wird. Für diese Art Traffic erstellt man für gewöhnlich ein Kubernetes-Service-Objekt mit dem Typ „Loadbalancer“. Kubernetes verwaltet dann diesen externen Loadbalancer. In einer IaaS Cloud mit LBaaS-Funktionalität kein Problem, aber in einem Rechenzentrum gestaltet sich das unter Umständen jedoch schwerer. Proprietäre Loadbalancer oder das Open Source-Projekt MetalLB können hilfreich sein.
Ähnlich wie mit der Auswahl des passenden CNIs gestaltet es sich teilweise schwer mit der richtigen Auswahl des Storage Volume Plugins. Zudem muss natürlich auch das passende Storage betrieben werden. Beliebt und geeignet ist zum Beispiel Ceph. Ob man sich diesen technischen Herausforderungen stellen will, kann man als Leser vermutlich schnell selbst beantworten. Sie sollten jedoch keinesfalls unterschätzt werden. Als Gegenwert für den harten und eher steinigen Weg erhält man dafür mit dem eigenen Setup definitiv Unabhängigkeit gegenüber Dritten und stets die volle Kontrolle über seine IT. Ebenso wertvoll kann das erlernte Know-how sein. Finanziell hängt es stark von bereits existierenden Strukturen und Komponenten ab, ob es einen tatsächlichen Vorteil gibt. Vergleicht man nur die Kosten für Compute-Ressourcen, mag es durchaus günstiger sein. Nicht zu unterschätzen sind jedoch die enormen initialen Zeitaufwände für Evaluierung, Proof of Concept, Setup und der anschließende ständige Aufwand für den Betrieb. Fazit Wie immer gibt es für die beiden vorgestellten Varianten Managed Kubernetes und Kubernetes On-Premises Vor- und Nachteile. Je nach Unternehmen, Struktur und Personal gibt es sicher gute Gründe, sich für die eine oder die andere Variante zu entscheiden. Klar gibt es auch Hersteller, die den Spagat zwischen beiden Welten versuchen. Welche Art für ein Unternehmen die effizienteste und sinnvollste ist, muss also ganz individuell beantwortet werden. Tendiert man zu einer Managed Lösung, gibt es gute Gründe, sich für NETWAYS Managed Kubernetes zu entscheiden. Da wäre zum Beispiel unser engagiertes Team mit unseren kompetenten MyEngineers, die unsere Kunden erfolgreich auf dem Weg in die Welt der Container begleiten. Ein weiterer Grund ist der direkte und persönliche Kontakt zu uns. Andere gute Gründe und Vorteile erklären meine Kolleginnen und Kollegen oder ich auch gerne persönlich.
Recent Comments