
Wie Du Deine NETWAYS Managed Database startest
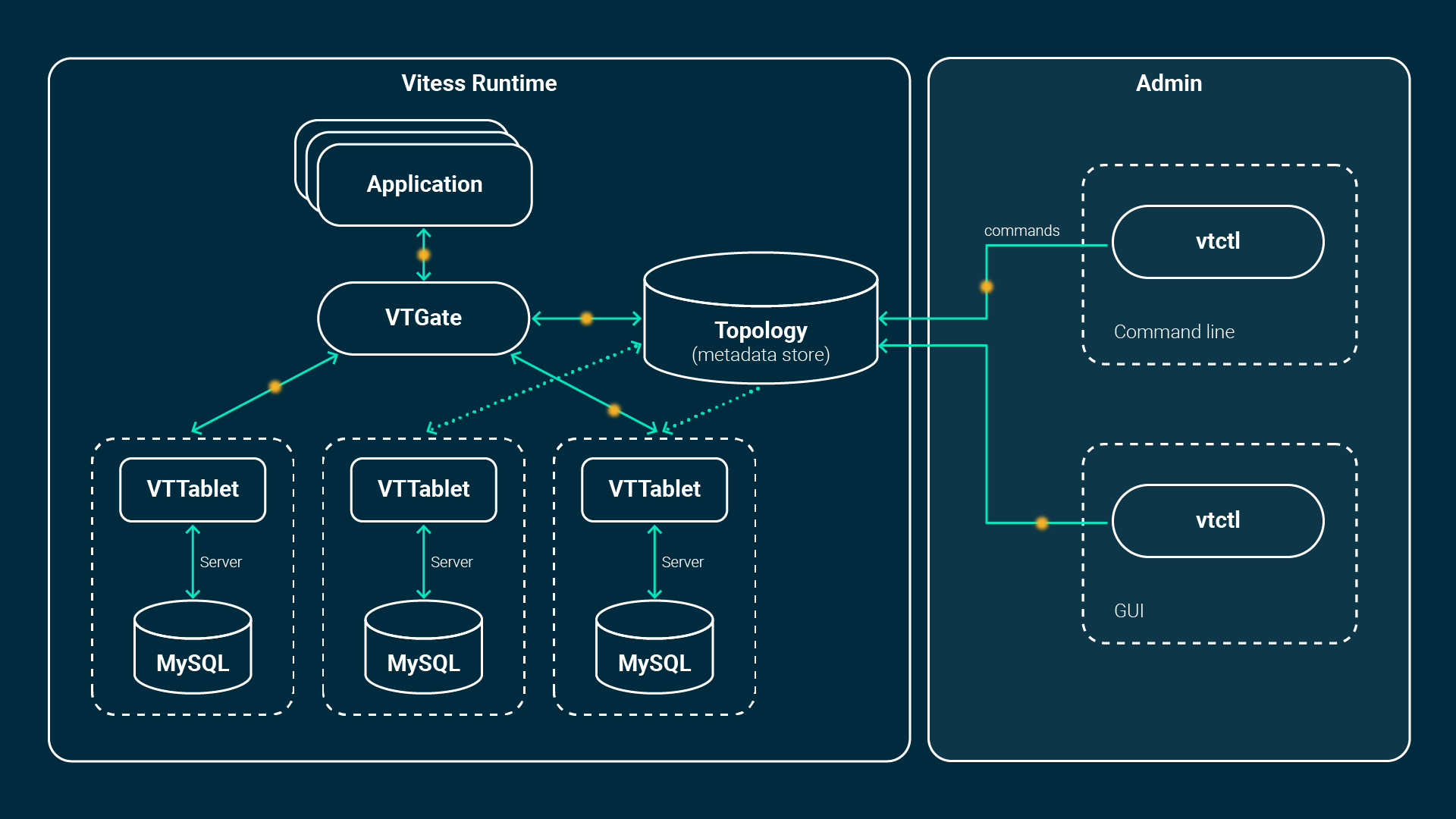
Im ersten Tutorial hat Sebastian bereits erklärt, was es mit Vitess auf sich hat und welche Möglichkeiten es Dir beim Betrieb Deiner Anwendung, im Vergleich zu einer gewöhnlichen Datenbank, bietet.
Im folgenden Text möchte ich nun darauf eingehen, wie Du Dir in unserem Vitess Cluster ganz einfach Deine Datenbank(en) innerhalb von wenigen Minuten starten kannst.
Was Deine Datenbank Besonders Macht
Grundsätzlich gilt es vorab zu erwähnen, dass Dein Setup immer hochverfügbar aufgebaut ist. Wir betreiben Vitess in einem Kubernetes Cluster, welcher zu gleichen Teilen auf unsere beiden Rechenzentren verteilt ist.
Dabei replizieren wir die Daten immer von links nach rechts. Eine Managed Database besteht also mindestens aus zwei Replicas – ein Primary und mindestens ein Replica. Liegt der Primary in dem einen Rechenzentrum (links), so kommt das Replika automatisch in das andere (rechts). Fällt also ein Rechenzentrum aus, schwenkt Vitess über und betreibt die Datenbank ohne Beeinträchtigung Deiner Anwendung auf dem zweiten Datencenter weiter.
Weiterhin ist auch ein Disaster Recovery von Haus aus mit dabei. Sobald die Datenbank erstellt wird, wird auch ein initiales Backup angefertigt und in der Folge wird täglich ein Backup (MySQL Dump) erzeugt. Die Daten werden im Xtrabackup-Format in S3 kopiert und aus diesem Storage werden die Daten im Notfall wieder hergestellt.
Wie Du Deine Erste Datenbank Startest
Genug zur Theorie – wie läuft denn nun der Start einer Managed DB in der Praxis ab? Zunächst einmal musst Du Dich auf unserer NETWAYS Web Services (NWS) – Plattform registrieren.
Sobald Du Deinen Account angelegt und Deine Zahlungsart hinterlegt hast, kann es auch schon losgehen!
Als erstes startest Du Dir nun Deinen Vitess Cluster, wie oben im Video zu sehen. Innerhalb eines Vitess Clusters kannst Du dann beliebig viele Datenbanken starten. Unter „Managed Contract“ kannst Du Deinen Cluster auch umbenennen.
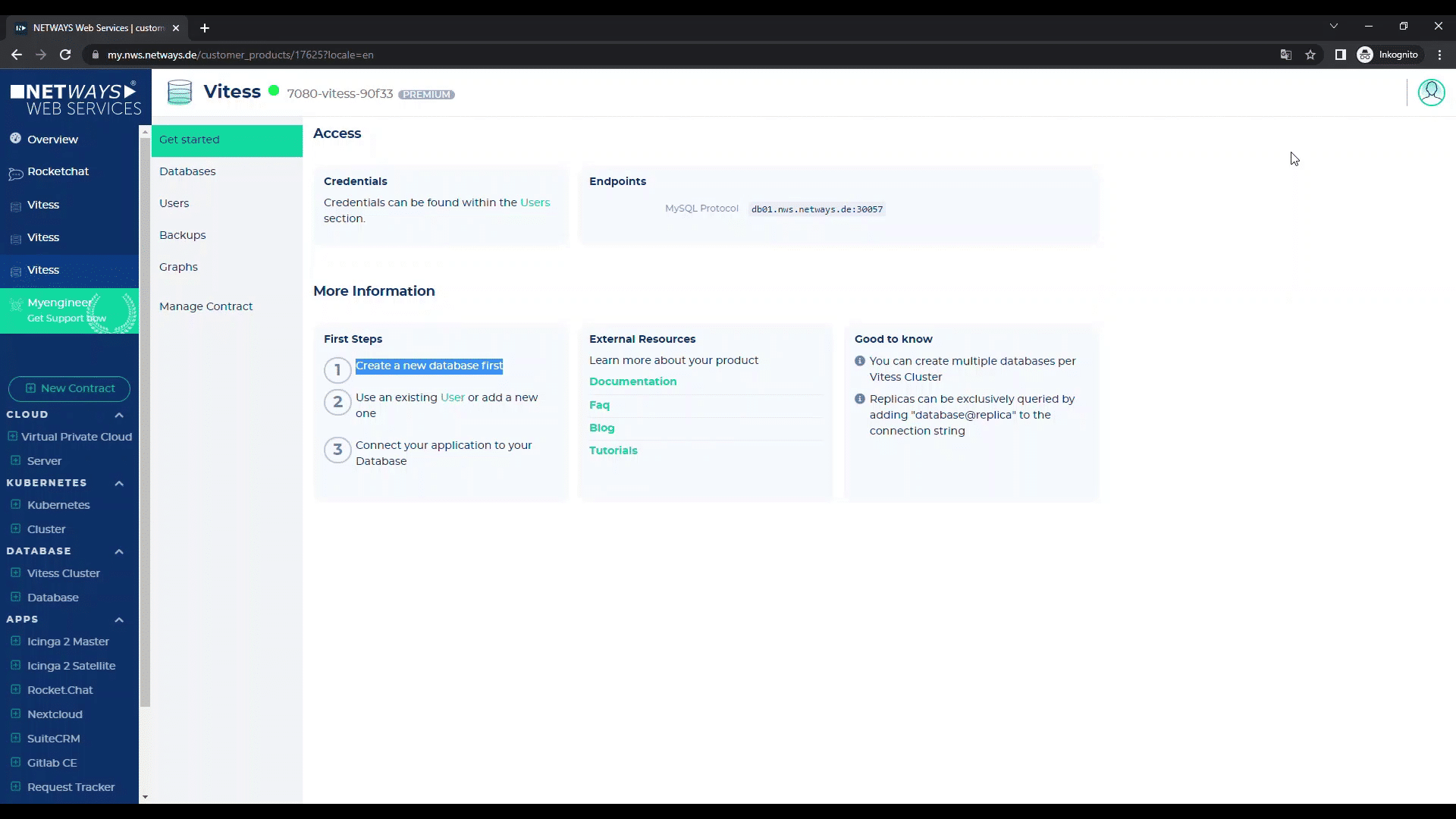
Nun gilt es, die erste Datenbank zu starten. Klicke hierfür einfach auf „1. Create a new database“.
Im Folgenden kannst Du Deine DB benennen und aussuchen, in welchem Vitess-Cluster die Datenbank gestartet werden soll (sofern Du denn mehrere Cluster hast).
Nun musst Du Dich für einen unserer vier Pläne entscheiden. Diese unterscheiden sich in der Replika-Größe, der inkludierten Backup-Größe und dem inkludiertem Traffic. Zusätzlich werden jedem nächst höheren Plan mehr Ressourcen (in Form von CPU u. Arbeitsspeicher) zugeordnet. Wenn Du also viel Load hast, empfiehlt es sich, einen höheren Plan zu wählen, da dieser mehr Queries/Sekunde verarbeiten kann.
Danach kannst Du entscheiden, wie viele Replicas angelegt werden sollen. Der kleinste Wert ist hier immer zwei (bestehend aus einem Primary und einem Replica). Sollte Deine Anwendung sehr leseintensiv sein, kannst du die Zahl der Replicas beliebig erhöhen und somit die Last effizient verteilen.
Auch die Vorhaltedauer der täglichen Backups kann frei bestimmt werden. Das Backup des letzten Tages liefern wir standardmäßig. Sollen die Backups über mehrere Tage aufgehoben werden, kannst Du das aber einfach einstellen, indem Du die Tage auf die gewünschte Dauer erhöhst.
Zu guter Letzt kannst Du auch noch den Replication Mode auswählen. Hier wird eingestellt, wie Deine Daten repliziert werden sollen.
Beim Asyn-Verfahren wird der Primary mit Transaktionen „befeuert“ und die Replicas versuchen einfach, so gut es geht ohne Zeitverzögerung an der Primary dranzubleiben – diese Zeitverzögerungen (Seconds behind Master) können /dürfen aber auftreten. Im Falle eines Failovers kann es hier passieren, dass auf ein Replica umgeschwenkt wird, welches nicht die neuesten Transaktionen mitbekommen hat, da es zeitlich ein paar Sekunden hinterher war.
Dies kann im Semi-Sync-Modus nicht passieren. Im Semi-Sync Modus erwartet MySQL immer mindestens von einem Replica, dass er die letzte Transaktion auch mit erfüllt hat. So wird gewährleistet, dass mindestens ein Replica immer auf dem exakt gleichen Stand wie Dein Primary ist. Geht der Primary kaputt, schwenkt Vitess automatisch auf das aktuellste Replica um und ernennt dieses zum neuen Primary – es geht also ohne Datenverlust weiter.
Hier ein kleiner Tipp: Idealerweise besteht ein Datenbank-Setup im Semi-Sync Modus aus drei Replicas – einem Primary und zwei Replicas. Einer der beiden Replicas ist dabei immer up to date mit dem Primary. Kommt es dann zu einem Failover, kann das zum Primary ernannte Replica weiterhin arbeiten, da es ja noch ein zusätzliches Replica hat, welches neue Transaktionen bestätigt.
Wäre das nicht der Fall (und Du hättest nur ein Replica), dann würde dem zum Primary ernannten Replica nun eine Gegenstelle für das Commitment neuer Transaktionen fehlen. Er müsste also warten, bis ein neues Replica hochgefahren ist, um die Transaktionen zu bestätigen (das betrifft nur writes oder deletes; Lesequeries sind hiervon nicht betroffen).
Nun klickst du auf „Create“ und schon wird Deine Datenbank gestartet! Et voilà – nach einem kurzen Moment sind Deine Daten verfügbar und Du kannst loslegen. Bei Deiner Datenbank hast Du nun die Optionen „Connect“, „Edit“ und „Destroy“.
Über „Connect“ wird Dir angezeigt, wie Du Dich auf die Datenbank verbindest – ganz wie gewohnt mit mySQL mit Host, User, Passwort und SSL-Optionen (Nicht-SSL-Verbindungen lehnen wir ab).
Es gibt hier noch eine Besonderheit: bei Deiner SQL-Verbindung wird der Datenbank-Name mit angegeben!
Wenn man den DB-Namen um @replica ergänzt, dann verbindest Du Dich auf das Replica (welches nur Read-only ist).
Wenn es Deine Anwendung also unterstützt (z.B. Ruby on Rails), kannst Du Deine Primary-Datenbank- und Deine Replica-Datenbankverbindung angeben und in der Folge gehen alle Select-Statements auf Replicas und alle Data-Manipulation-Statements auf den Primary. So lässt sich Dein Setup super skalieren, da Deine Anwendung die Load der lesenden Queries auf die Replicas leiten kann.
Über „Edit“ kannst Du Deine Datenbank konfigurieren.
Wenn Dir also der Storage ausgeht, kannst Du hier einfach in den nächstgrößeren Plan wechseln. Oder Du erhöhst die Anzahl der Replica und Backups oder passt den Replication-Modus noch einmal an.
Reicht der größte Plan nicht mehr aus, greift unsere Skalierung über das Sharding. Hierzu folgt aber noch ein ausführliches Tutorial.
Wie oben zu sehen, löschst Du über „Destroy“ Deine Datenbank wieder.
Unter dem Punkt „User“ findest Du alle Credentials zum automatisch angelegten User. Darüber hinaus kannst Du hier auch weitere User erstellen (u. wieder löschen) und Passwörter frei vergeben.
Unter dem Punkt „Backups“ findest Du immer die von Haus aus einmal täglich automatisch erstellte Sicherung.
Du kannst jederzeit auch selbst manuell ein Backup erstellen (für den Fall, dass Du z.B. an Deiner Datenbank arbeitest und vorher noch mal eine letzte Datenbank-Sicherung machen möchtest), indem Du auf „Create Backup“ klickst und hier die zu sichernde Datenbank (sofern Du mehrere in Deinem Cluster gestartet hast) auswählst.
Je nachdem, welchen Rentention-Zyklus Du bei deiner Datenbank eingestellt hast, werden Deine Zwischenspeicherungen dann am Abend wieder weggelöscht.
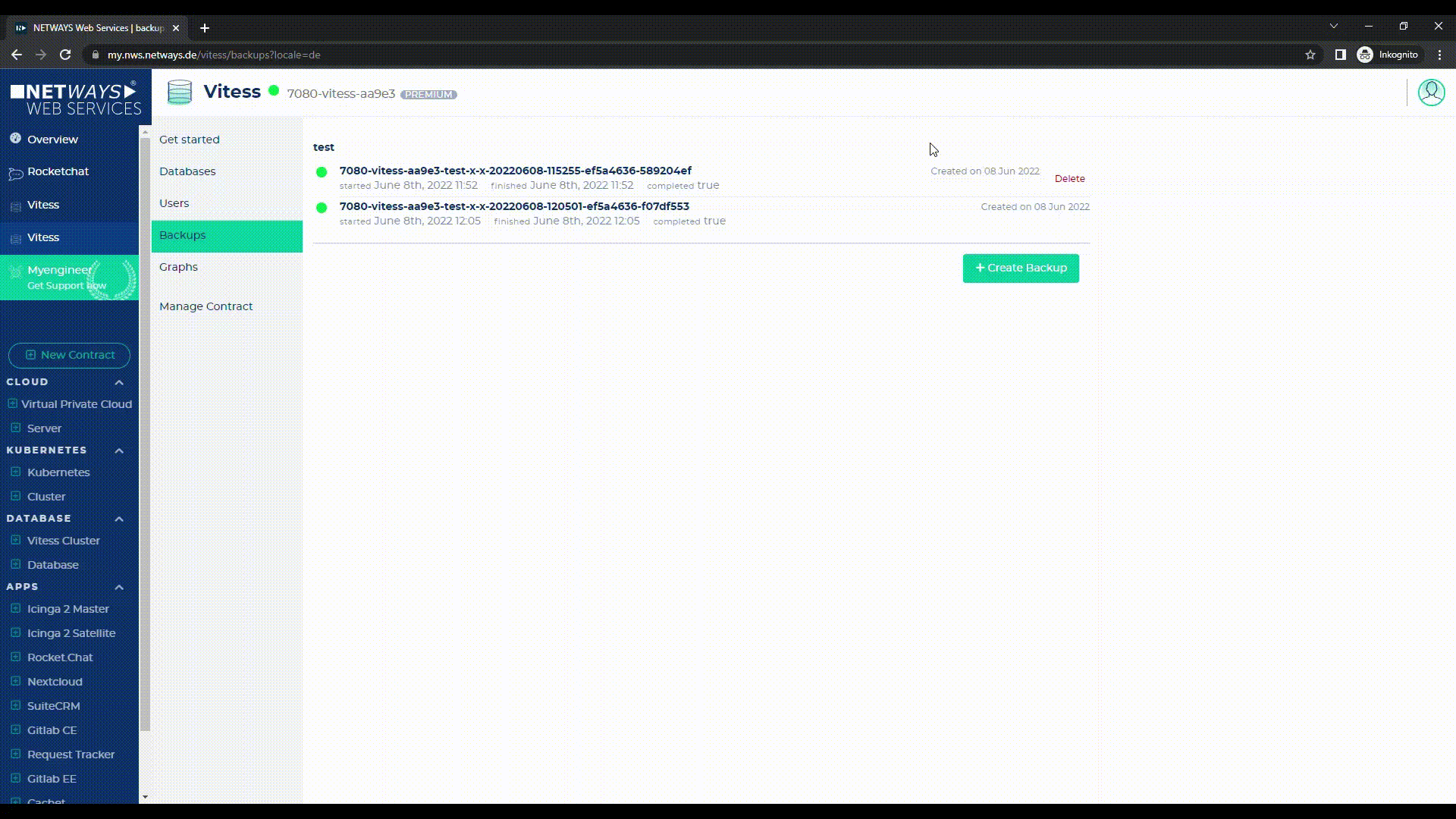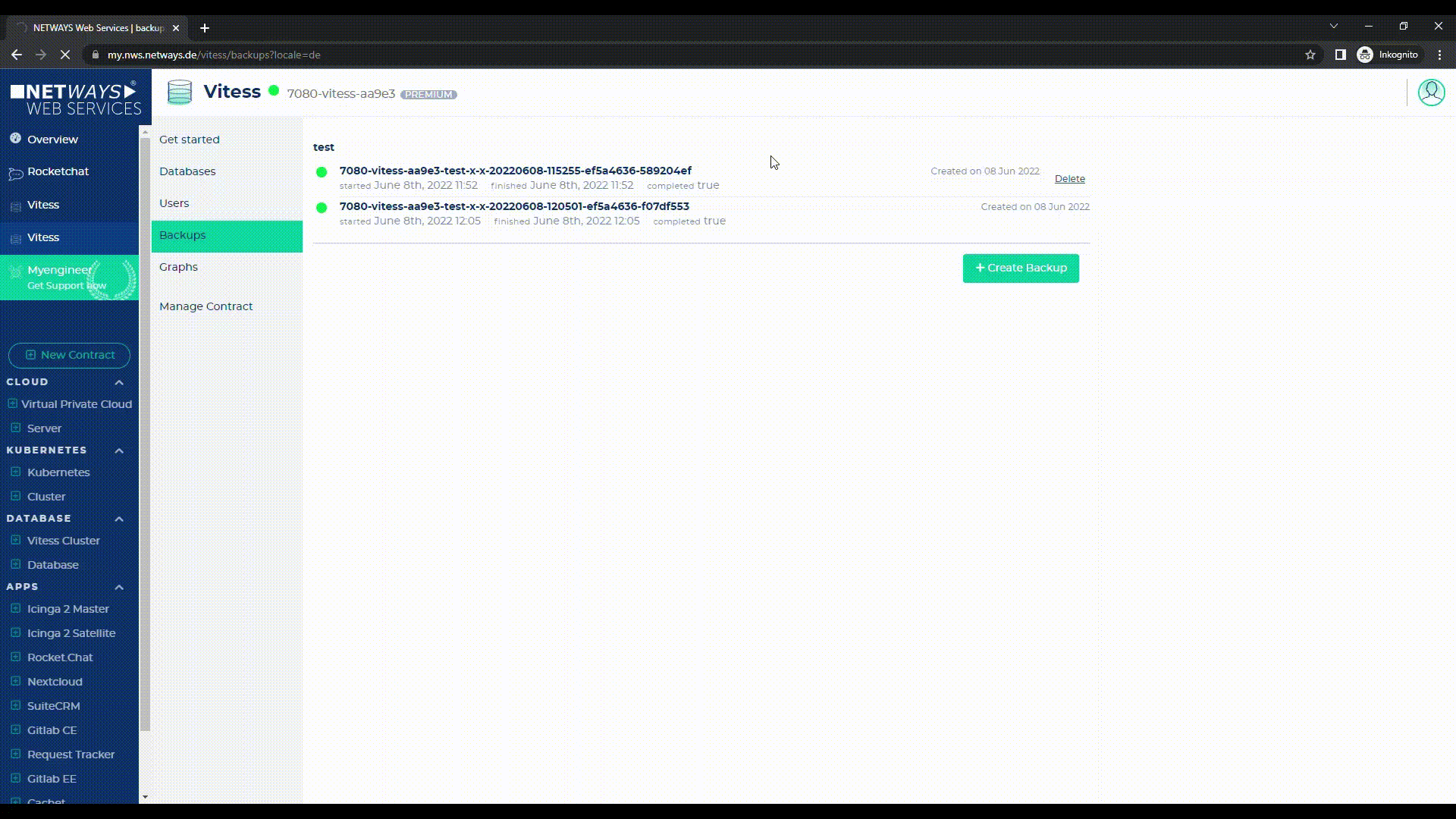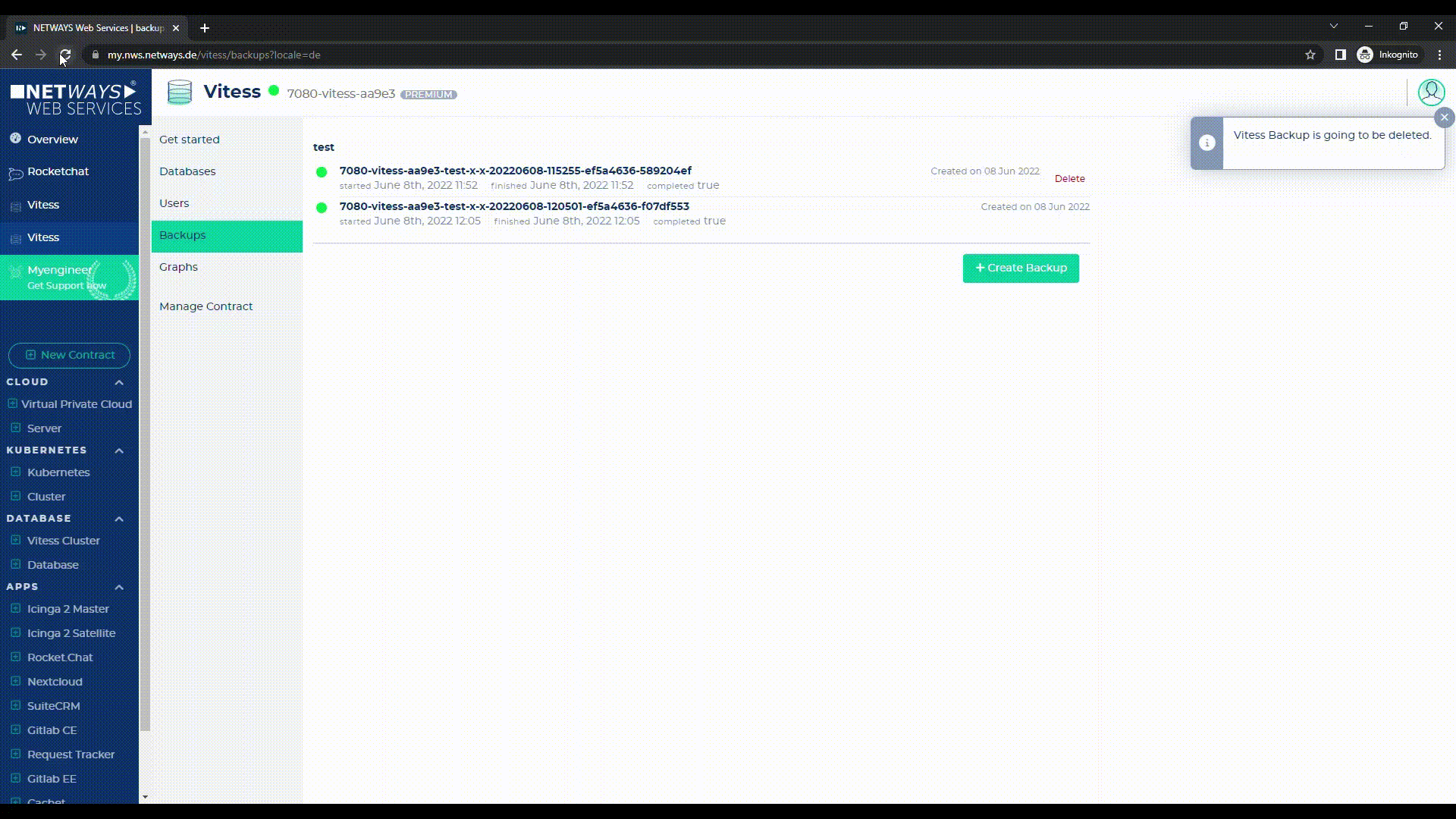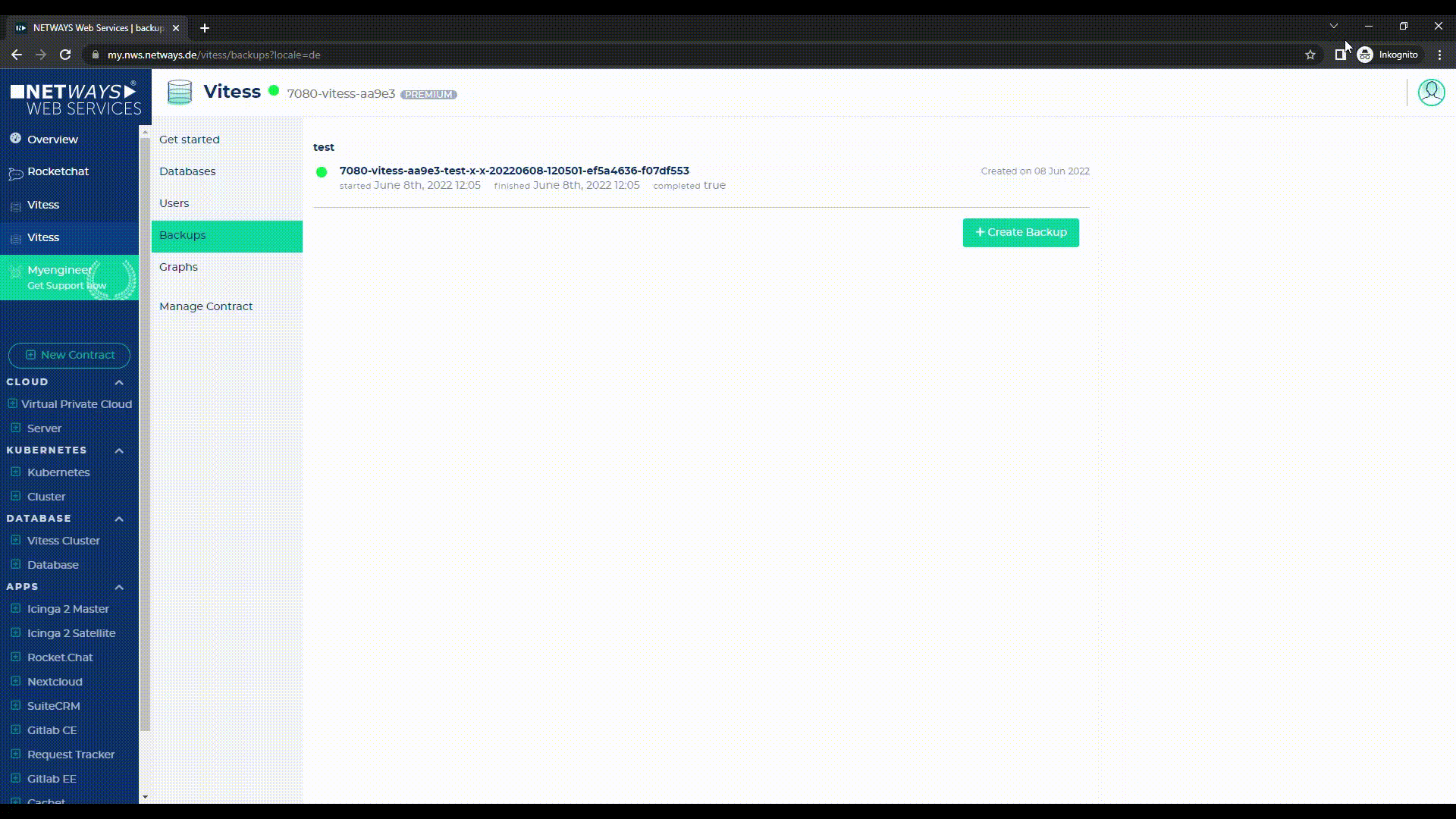
Sofern hier mehrere Backups liegen, können diese auch wieder gelöscht werden – lediglich das letzte (höchste) Backup ist nicht löschbar, da mit diesem im Bedarfsfall die Replicas wieder hergestellt werden.
Unter dem Punkt „Graphs“ visualisieren wir die Auslastung Deines Setups (Queries/Sekunde), die Storage-Belegung und das Slave-Lag für alle Replicas.
Unter dem Punkt „Manage contract“ kannst Du Deinen Vitess Cluster umbenennen oder kündigen.
Das ist die ganze Magie, die hinter dem Start Deiner ersten NETWAYS Managed Database mit Vitess steckt!

Recent Comments