
von Sebastian Saemann | Mai 27, 2020 | Kubernetes, Tutorial
Monitoring – für viele eine gewisse Hass-Liebe. Die einen mögen es, die anderen verteufeln es. Ich gehöre zu denen, die es meist eher verteufeln, dann aber meckern, wenn man gewisse Metriken und Informationen nicht einsehen kann. Unabhängig der persönlichen Neigungen zu diesem Thema ist der Konsens aller jedoch sicher: Monitoring ist wichtig und ein Setup ist auch nur so gut wie sein dazugehöriges Monitoring. Wer seine Anwendungen auf Basis von Kubernetes entwickeln und betreiben will, stellt sich zwangsläufig früher oder später die Frage, wie man diese Anwendungen und den Kubernetes Cluster überwachen kann. Eine Variante ist der Einsatz der Monitoringlösung Prometheus; genauer gesagt durch die Verwendung des Kubernetes Prometheus Operators. Eine beispielhafte und funktionale Lösung wird in diesem Blogpost gezeigt.
Kubernetes Operator
Kubernetes Operators sind kurz erklärt Erweiterungen, mit denen sich eigene Ressourcentypen erstellen lassen. Neben den Standard-Kubernetes-Ressourcen wie Pods, DaemonSets, Services usw. kann man mit Hilfe eines Operators auch eigene Ressourcen nutzen. In unserem Beispiel kommen neu hinzu: Prometheus, ServiceMonitor und weitere. Operators sind dann von großem Nutzen, wenn man für seine Anwendung spezielle manuelle Tasks ausführen muss, um sie ordentlich betreiben zu können. Das könnten beispielsweise Datenbank-Schema-Updates bei Versionsupdates sein, spezielle Backupjobs oder das Steuern von Ereignissen in verteilten Systemen. In der Regel laufen Operators – wie gewöhnliche Anwendungen auch – als Container innerhalb des Clusters.
Wie funktioniert es?
Die Grundidee ist, dass mit dem Prometheus Operator ein oder viele Prometheus-Instanzen gestartet werden, die wiederum durch den ServiceMonitor dynamisch konfiguriert werden. Das heißt, es kann an einem gewöhnlichen Kubernetes Service mit einem ServiceMonitor angedockt werden, der wiederum ebenfalls die Endpoints auslesen kann und die zugehörige Prometheus-Instanz entsprechend konfiguriert. Verändern sich der Service respektive die Endpoints, zum Beispiel in der Anzahl oder die Endpoints haben neue IPs, erkennt das der ServiceMonitor und konfiguriert die Prometheus-Instanz jedes Mal neu. Zusätzlich kann über Configmaps auch eine manuelle Konfiguration vorgenommen werden.
Voraussetzungen
Voraussetzung ist ein funktionierendes Kubernetes Cluster. Für das folgende Beispiel verwende ich einen NWS Managed Kubernetes Cluster in der Version 1.16.2.
Installation Prometheus Operator
Zuerst wird der Prometheus-Operator bereitgestellt. Es werden ein Deployment, eine benötigte ClusterRole mit zugehörigem ClusterRoleBinding und einem ServiceAccount definiert.
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
app.kubernetes.io/component: controller
app.kubernetes.io/name: prometheus-operator
app.kubernetes.io/version: v0.38.0
name: prometheus-operator
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus-operator
subjects:
- kind: ServiceAccount
name: prometheus-operator
namespace: default
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
app.kubernetes.io/component: controller
app.kubernetes.io/name: prometheus-operator
app.kubernetes.io/version: v0.38.0
name: prometheus-operator
rules:
- apiGroups:
- apiextensions.k8s.io
resources:
- customresourcedefinitions
verbs:
- create
- apiGroups:
- apiextensions.k8s.io
resourceNames:
- alertmanagers.monitoring.coreos.com
- podmonitors.monitoring.coreos.com
- prometheuses.monitoring.coreos.com
- prometheusrules.monitoring.coreos.com
- servicemonitors.monitoring.coreos.com
- thanosrulers.monitoring.coreos.com
resources:
- customresourcedefinitions
verbs:
- get
- update
- apiGroups:
- monitoring.coreos.com
resources:
- alertmanagers
- alertmanagers/finalizers
- prometheuses
- prometheuses/finalizers
- thanosrulers
- thanosrulers/finalizers
- servicemonitors
- podmonitors
- prometheusrules
verbs:
- '*'
- apiGroups:
- apps
resources:
- statefulsets
verbs:
- '*'
- apiGroups:
- ""
resources:
- configmaps
- secrets
verbs:
- '*'
- apiGroups:
- ""
resources:
- pods
verbs:
- list
- delete
- apiGroups:
- ""
resources:
- services
- services/finalizers
- endpoints
verbs:
- get
- create
- update
- delete
- apiGroups:
- ""
resources:
- nodes
verbs:
- list
- watch
- apiGroups:
- ""
resources:
- namespaces
verbs:
- get
- list
- watch
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app.kubernetes.io/component: controller
app.kubernetes.io/name: prometheus-operator
app.kubernetes.io/version: v0.38.0
name: prometheus-operator
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/component: controller
app.kubernetes.io/name: prometheus-operator
template:
metadata:
labels:
app.kubernetes.io/component: controller
app.kubernetes.io/name: prometheus-operator
app.kubernetes.io/version: v0.38.0
spec:
containers:
- args:
- --kubelet-service=kube-system/kubelet
- --logtostderr=true
- --config-reloader-image=jimmidyson/configmap-reload:v0.3.0
- --prometheus-config-reloader=quay.io/coreos/prometheus-config-reloader:v0.38.0
image: quay.io/coreos/prometheus-operator:v0.38.0
name: prometheus-operator
ports:
- containerPort: 8080
name: http
resources:
limits:
cpu: 200m
memory: 200Mi
requests:
cpu: 100m
memory: 100Mi
securityContext:
allowPrivilegeEscalation: false
nodeSelector:
beta.kubernetes.io/os: linux
securityContext:
runAsNonRoot: true
runAsUser: 65534
serviceAccountName: prometheus-operator
---
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
app.kubernetes.io/component: controller
app.kubernetes.io/name: prometheus-operator
app.kubernetes.io/version: v0.38.0
name: prometheus-operator
namespace: default
---
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/component: controller
app.kubernetes.io/name: prometheus-operator
app.kubernetes.io/version: v0.38.0
name: prometheus-operator
namespace: default
spec:
clusterIP: None
ports:
- name: http
port: 8080
targetPort: http
selector:
app.kubernetes.io/component: controller
app.kubernetes.io/name: prometheus-operator
kubectl apply -f 00-prometheus-operator.yaml
clusterrolebinding.rbac.authorization.k8s.io/prometheus-operator created
clusterrole.rbac.authorization.k8s.io/prometheus-operator created
deployment.apps/prometheus-operator created
serviceaccount/prometheus-operator created
service/prometheus-operator created
Role Based Access Control
Zusätzlich werden entsprechende Role Based Access Control (RBAC) Policies benötigt. Die Prometheus-Instanzen (StatefulSets), gestartet durch den Prometheus-Operator, starten Container unter dem gleichnamigen ServiceAccount „Prometheus“. Dieser Account benötigt lesenden Zugriff auf die Kubernetes API, um später die Informationen über Services und Endpoints auslesen zu können.
Clusterrole
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRole
metadata:
name: prometheus
rules:
- apiGroups: [""]
resources:
- nodes
- services
- endpoints
- pods
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources:
- configmaps
verbs: ["get"]
- nonResourceURLs: ["/metrics"]
verbs: ["get"]
kubectl apply -f 01-clusterrole.yaml
clusterrole.rbac.authorization.k8s.io/prometheus created
ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
subjects:
- kind: ServiceAccount
name: prometheus
namespace: default
kubectl apply -f 01-clusterrolebinding.yaml
clusterrolebinding.rbac.authorization.k8s.io/prometheus created
ServiceAccount
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus
kubectl apply -f 01-serviceaccount.yaml
serviceaccount/prometheus created
Monitoring von Kubernetes Cluster Nodes
Es gibt diverse Metriken, die aus einem Kubernetes Cluster ausgelesen werden können. In diesem Beispiel wird zunächst nur auf die Systemwerte der Kubernetes Nodes eingegangen. Für die Überwachung der Kubernetes Cluster Nodes bietet sich die ebenfalls vom Prometheus-Projekt bereitgestellte Software „Node Exporter“ an. Diese liest sämtliche Metriken über CPU, Memory sowie I/O aus und stellt diese Werte unter /metrics zum Abruf bereit. Prometheus selbst „crawlet“ diese Metriken später in regelmäßigen Abständen. Ein DaemonSet steuert, dass jeweils ein Container/Pod auf einem Kubernetes Node gestartet wird. Mit Hilfe des Services werden alle Endpoints unter einer Cluster IP zusammengefasst.
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-exporter
spec:
selector:
matchLabels:
app: node-exporter
template:
metadata:
labels:
app: node-exporter
name: node-exporter
spec:
hostNetwork: true
hostPID: true
containers:
- image: quay.io/prometheus/node-exporter:v0.18.1
name: node-exporter
ports:
- containerPort: 9100
hostPort: 9100
name: scrape
resources:
requests:
memory: 30Mi
cpu: 100m
limits:
memory: 50Mi
cpu: 200m
volumeMounts:
- name: proc
readOnly: true
mountPath: /host/proc
- name: sys
readOnly: true
mountPath: /host/sys
volumes:
- name: proc
hostPath:
path: /proc
- name: sys
hostPath:
path: /sys
---
apiVersion: v1
kind: Service
metadata:
labels:
app: node-exporter
annotations:
prometheus.io/scrape: 'true'
name: node-exporter
spec:
ports:
- name: metrics
port: 9100
protocol: TCP
selector:
app: node-exporter
kubectl apply -f 02-exporters.yaml
daemonset.apps/node-exporter created
service/node-exporter created
Service Monitor
Mit der sogenannten Third Party Ressource „ServiceMonitor“, bereitgestellt durch den Prometheus Operator, ist es möglich, den zuvor gestarteten Service, in unserem Fall node-exporter, für die zukünftige Überwachung aufzunehmen. Die TPR selbst erhält ein Label team: frontend, das wiederum später als Selector für die Prometheus-Instanz genutzt wird.
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: node-exporter
labels:
team: frontend
spec:
selector:
matchLabels:
app: node-exporter
endpoints:
- port: metrics
kubectl apply -f 03-service-monitor-node-exporter.yaml
servicemonitor.monitoring.coreos.com/node-exporter created
Prometheus-Instanz
Es wird eine Prometheus-Instanz definiert, die nun alle Services anhand der Labels sammelt und von deren Endpoints die Metriken bezieht.
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
name: prometheus
spec:
serviceAccountName: prometheus
serviceMonitorSelector:
matchLabels:
team: frontend
resources:
requests:
memory: 400Mi
enableAdminAPI: false
kubectl apply -f 04-prometheus-service-monitor-selector.yaml
prometheus.monitoring.coreos.com/prometheus created
Prometheus Service
Die gestartete Prometheus-Instanz wird mit einem Service-Objekt exponiert. Nach einer kurzen Wartezeit ist ein Cloud-Loadbalancer gestartet, der aus dem Internet erreichbar ist und Anfragen zu unserer Prometheus-Instanz durchreicht.
apiVersion: v1
kind: Service
metadata:
name: prometheus
spec:
type: LoadBalancer
ports:
- name: web
port: 9090
protocol: TCP
targetPort: web
selector:
prometheus: prometheus
kubectl apply -f 05-prometheus-service.yaml
service/prometheus created
kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
prometheus LoadBalancer 10.254.146.112 pending 9090:30214/TCP 58s
Sobald die externe IP-Adresse verfügbar ist, kann diese über http://x.x.x.x:9090/targets aufgerufen werden und man sieht alle seine Kubernetes Nodes, deren Metriken ab sofort regelmäßig abgerufen werden. Kommen später weitere Nodes hinzu, so werden diese automatisch mit aufgenommen bzw. wieder entfernt. 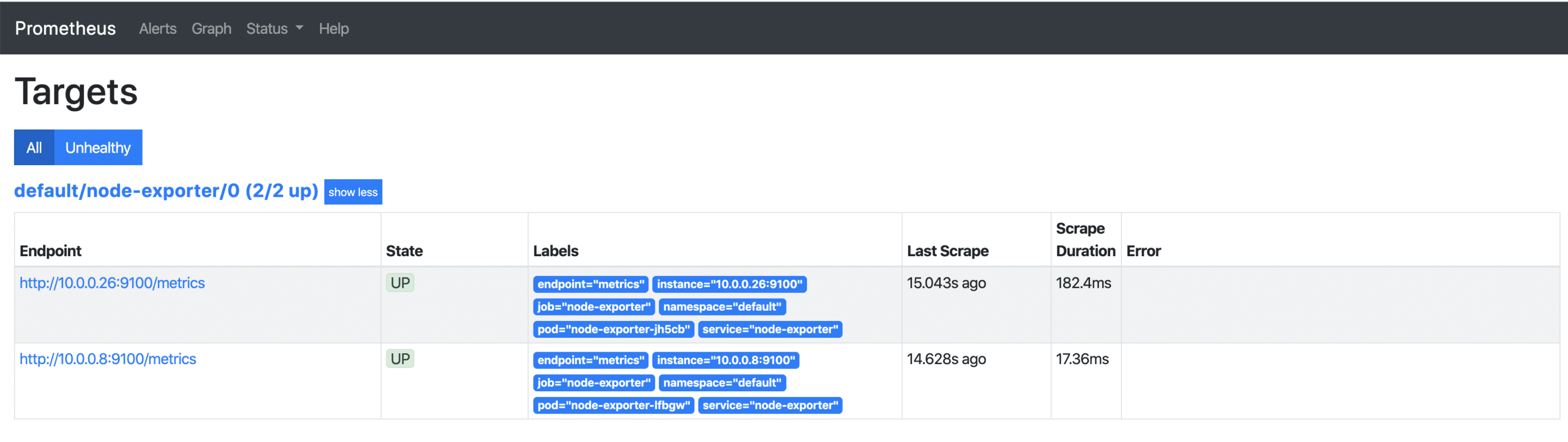
Visualisierung mit Grafana
Die gesammelten Metriken, lassen sich leicht und ansprechend mit Grafana visualisieren. Grafana ist ein Analyse-Tool, das diverse Datenbackends unterstützt.
apiVersion: v1
kind: Service
metadata:
name: grafana
spec:
# type: LoadBalancer
ports:
- port: 3000
targetPort: 3000
selector:
app: grafana
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: grafana
name: grafana
spec:
selector:
matchLabels:
app: grafana
replicas: 1
revisionHistoryLimit: 2
template:
metadata:
labels:
app: grafana
spec:
containers:
- image: grafana/grafana:latest
name: grafana
imagePullPolicy: Always
ports:
- containerPort: 3000
env:
- name: GF_AUTH_BASIC_ENABLED
value: "false"
- name: GF_AUTH_ANONYMOUS_ENABLED
value: "true"
- name: GF_AUTH_ANONYMOUS_ORG_ROLE
value: Admin
- name: GF_SERVER_ROOT_URL
value: /api/v1/namespaces/default/services/grafana/proxy/
kubectl apply -f grafana.yaml
service/grafana created
deployment.apps/grafana created
kubectl proxy
Starting to serve on 127.0.0.1:8001
Sobald die Proxy-Verbindung durch kubectl verfügbar ist, kann die gestartete Grafana-Instanz via http://localhost:8001/api/v1/namespaces/default/services/grafana/proxy/ im Browser aufgerufen werden. Damit die in Prometheus vorliegenden Metriken jetzt auch visuell ansprechend dargestellt werden können, sind nur noch wenige weitere Schritte notwendig. Zuerst wird eine neue Data-Source vom Typ Prometheus angelegt. Dank des kuberneteseigenen und -internen DNS lautet die URL http://prometheus.default.svc:9090. Das Schema ist servicename.namespace.svc. Alternativ kann natürlich auch die Cluster-IP verwendet werden. 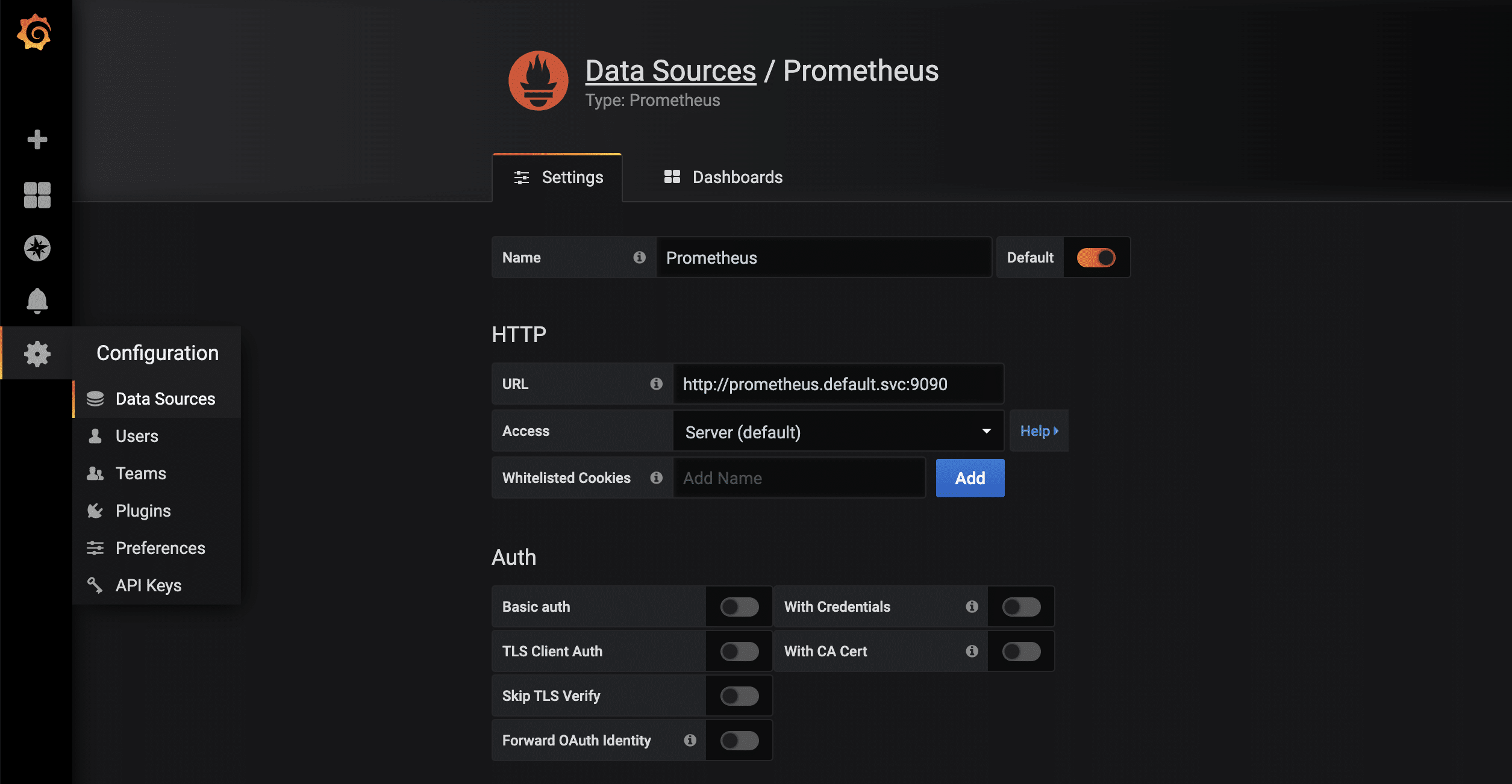 Für die gesammelten Metriken des node-exporters gibt es bereits ein sehr vollständiges Grafana-Dashboard, das sich über die Import-Funktion importieren lässt. Die ID des Dashboards ist 1860.
Für die gesammelten Metriken des node-exporters gibt es bereits ein sehr vollständiges Grafana-Dashboard, das sich über die Import-Funktion importieren lässt. Die ID des Dashboards ist 1860. 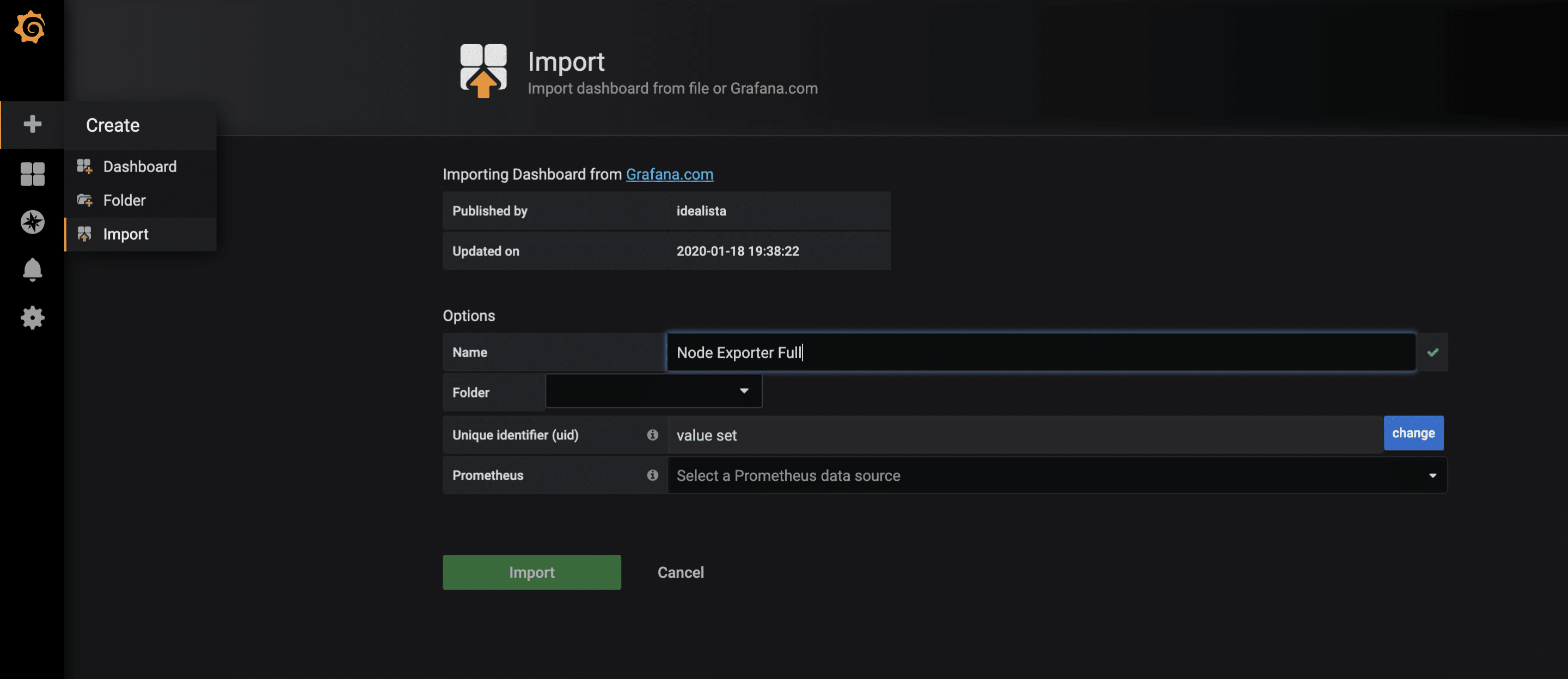 Nach dem erfolgreichem Import des Dashboards können jetzt die Metriken begutachtet werden.
Nach dem erfolgreichem Import des Dashboards können jetzt die Metriken begutachtet werden. 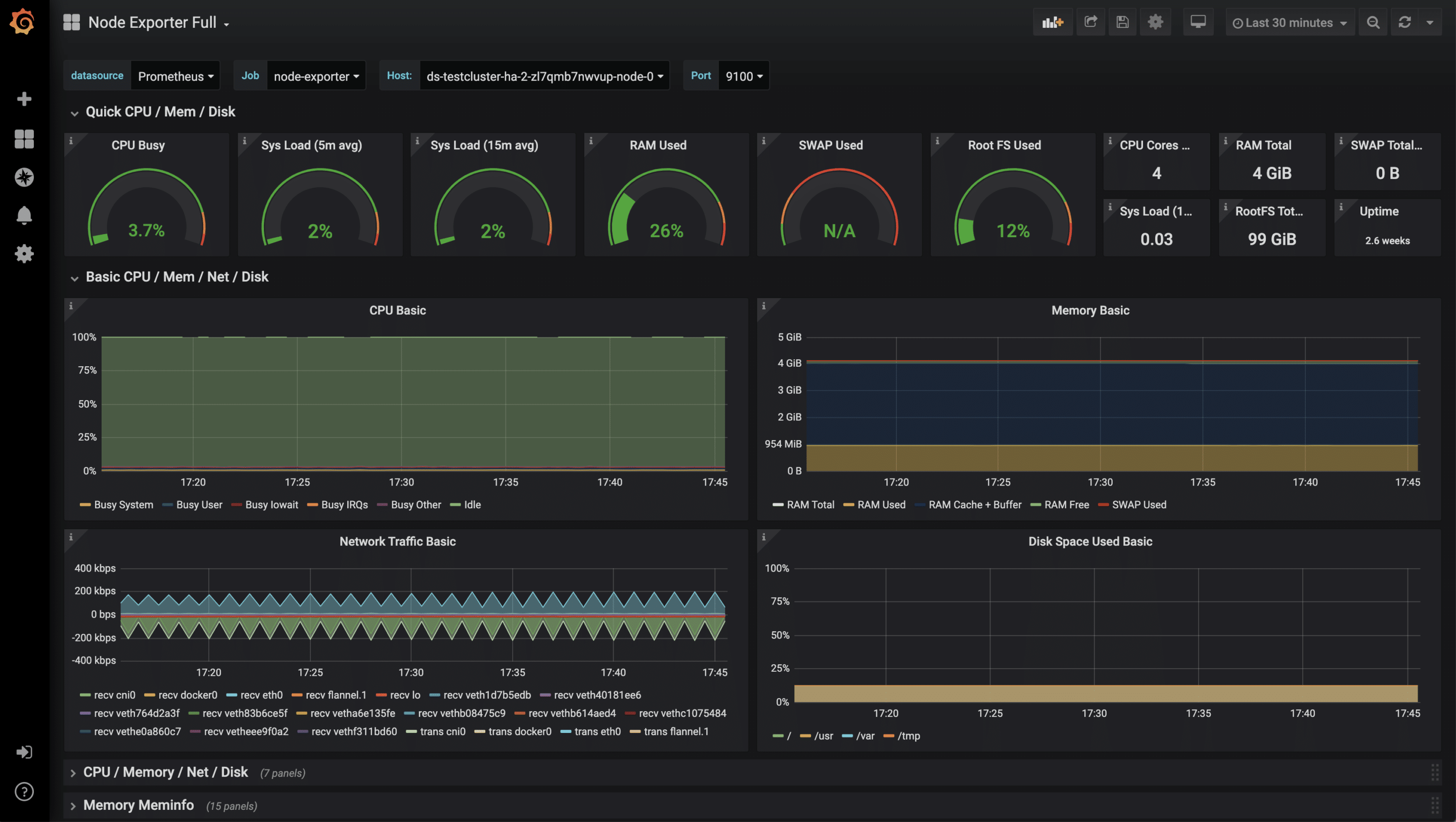
Monitoring weiterer Anwendungen
Neben diesen eher technischen Statistiken sind auch weitere Metriken der eigenen Anwendungen möglich, beispielsweise HTTP Requests, SQL Queries, Business-Logik und vieles mehr. Hier werden einem durch das sehr flexible Datenformat kaum Grenzen gesetzt. Um seine eigenen Metriken zu sammeln, gibt es wie immer mehrere Lösungsansätze. Einer davon ist, seine Anwendung mit einem /metrics Endpunkt auszustatten. Manche Frameworks wie z.B. Ruby on Rails haben bereits brauchbare Erweiterungen. Ein weiterer Ansatz sind sogenannte Sidecars. Ein Sidecar ist ein zusätzlicher Container, der neben dem eigentlichen Anwendungscontainer mitläuft. Beide zusammen ergeben einen Pod, der sich Namespace, Netzwerk etc. teilt. In dem Sidecar läuft dann Code, der die Anwendung prüft und die Ergebnisse als parsebare Werte für Prometheus zur Verfügung stellt. Im Wesentlichen können beide Ansätze, wie im oben gezeigten Beispiel, mit dem Prometheus Operator verknüpft werden.

von Achim Ledermüller | Mai 20, 2020 | Kubernetes, Tutorial
Mit den ersten Schritten mit Kubernetes weißt Du bereits, wie Du Anwendungen in Deinem Kubernetes Cluster startest. Nun exponieren wir Deine Anwendung online. Wie das Ganze funktioniert und wie Du mit einem Kubernetes Nginx Ingress Controller am besten selbst direkt loslegen kannst, erläutere ich Dir im Folgenden an einem Beispiel. Um in einem Kubernetes Cluster Anwendungen von außen erreichbar zu machen, kann man einen Service vom Typ Loadbalancer verwenden. In der NETWAYS Cloud starten wir hier im Hintergrund ein Openstack Octavia LB mit öffentlicher IP und leiten den eingehenden Traffic an die Pods weiter (Bingo). Somit benötigen wir für jede Anwendung einen eigenen Loadbalancer mit öffentlicher IP. Um in einem Fall wie diesem etwas ressourcen- und somit kosteneffizienter arbeiten zu können, hat man vor Langem named-based virtual hosts und server name indication (sni) erfunden. Der altbekannte NGINX-Webserver unterstützt beides und als Kubernetes Ingress Controller kann dieser, mit nur einer öffentlichen IP-Adresse, all unsere http/s-Anwendungen schnell und einfach erreichbar machen. Die Installation und die Aktualisierung des Ningx Ingress Controllers ist dank eines Helm Charts sehr vereinfacht. Mit K8s Ingress Objekten konfiguriert man die Zuordnung von vHosts, URI-Pfaden und TLS-Zertifikaten zu K8s Services und somit zu unseren Anwendungen. Damit die Buzzwords Dir nicht den Blick aufs Wesentliche verhindern, hier ein kleiner Überblick, wie die HTTP-Anfragen an unsere Anwendungen weitergeleitet werden: 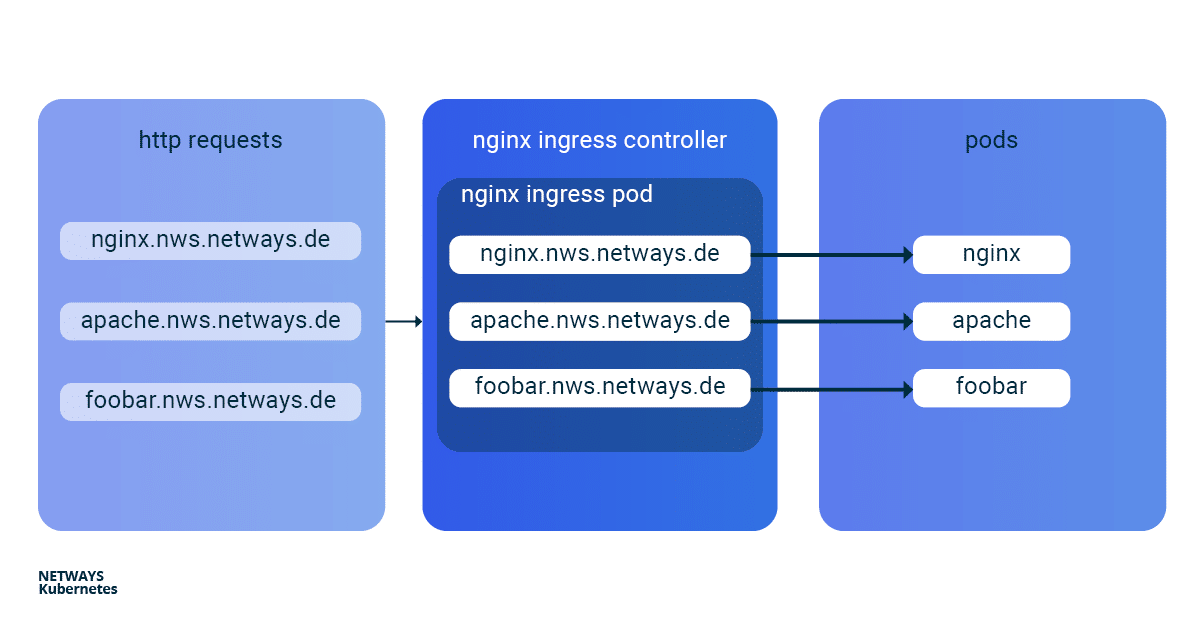
Installation Kubernetes Nginx Ingress Controller

Zur einfachen Installation des Kubernetes Nginx Ingress Controllers solltest Du Helm verwenden. Helm bezeichnet sich selbst als Paketmanager für Kubernetes-Anwendungen. Neben der Installation bietet Helm auch einfache Updates seiner Anwendungen. Wie auch bei kubectl brauchst Du nur die K8s-Config, um direkt loszulegen:
helm install my-ingress stable/nginx-ingress
Mit diesen Befehlen startet Helm alle nötigen Komponenten im default Namespace und gibt diesen das Label my-ingress. Für den Nginx Ingress Controller wird ein deployment, ein replicaset und ein pod erstellt. Alle http/s-Anfragen müssen an diesen pod weitergeleitet werden, damit dieser anhand von vHosts und URI-Pfaden die Anfragen sortieren kann. Dafür wurde ein service vom Typ loadbalancer erstellt, welcher auf eine öffentliche IP lauscht und den ankommenden Traffic auf den Ports 443 und 80 an unseren pod weiterleitet. Ein ähnliches Konstrukt wird auch für das default-backend angelegt, auf welche ich hier aber nicht näher eingehe. Damit Du den Überblick nicht verlierst, kannst Du Dir alle beteiligten Komponenten mit kubectl anzeigen lassen:
kubectl get all -l release=my-ingress #with default-backend
kubectl get all -l release=my-ingress -l component=controller #without default-backend
NAME READY STATUS RESTARTS
pod/my-ingress-nginx-ingress-controller-5b649cbcd8-6hgz6 1/1 Running 0
NAME READY UP-TO-DATE AVAILABLE
deployment.apps/my-ingress-nginx-ingress-controller 1/1 1 1
NAME DESIRED CURRENT READY
replicaset.apps/my-ingress-nginx-ingress-controller-5b649cbcd8 1 1 1
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S)
service/my-ingress-nginx-ingress-controller LoadBalancer 10.254.252.54 185.233.188.56 80:32110/TCP,443:31428/TCP
Beispielanwendungen: Apache und Nginx
Als nächstes starten wir zwei einfache Beispielanwendungen. Im Beispiel verwende ich Apache und Nginx. Ziel ist es, beide Anwendungen unter eigenen name-based virtual hosts verfügbar zu machen: nginx.nws.netways.de und apache.nws.netways.de. Damit die beiden Deployments innerhalb des K8s Clusters erreichbar sind, müssen wir diese noch jeweils mit einem Service verbinden.
K8s Deployments
Nginx Deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
Apache Deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: apache-deployment
labels:
app: apache
spec:
replicas: 3
selector:
matchLabels:
app: apache
template:
metadata:
labels:
app: apache
spec:
containers:
- name: apache
image: httpd:2.4
ports:
- containerPort: 80
K8s Service
Nginx Service
apiVersion: v1
kind: Service
metadata:
name: nginx-svc
spec:
ports:
- port: 80
targetPort: 80
protocol: TCP
name: http
selector:
app: nginx
Apache Service
apiVersion: v1
kind: Service
metadata:
name: apache-svc
spec:
ports:
- port: 80
targetPort: 80
protocol: TCP
name: http
selector:
app: apache
Virtual Hosts ohne TLS
Um nun die Anfragen vom Nginx Controller zu unseren Anwendungen weiterzureichen, müssen wir ein passendes Kubernetes Ingress Objekt ausrollen. Im spec Bereich des Ingress Objekts können wir unterschiedliche Pfade und virtuell Hosts definieren. Im Beispiel sehen wir vHosts für nginx.nws.netways.de und apache.nws.netways.de. Für jeden der beiden vHosts ist im Bereich backend natürlich der entsprechende service eingetragen. Die öffentliche IP findet man im service des Nginx Ingress Controllers und kubectl describe zeigt alle wichtigen Details zum Service (siehe unten). Zum Testen manipulierst Du am besten seine /etc/hosts Datei und trägst dort die IP von LoadBalancer Ingress ein.
K8s Ingress
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
name: my-ingress
spec:
rules:
- host: apache.nws.netways.de
http:
paths:
- backend:
serviceName: apache-svc
servicePort: 80
- host: nginx.nws.netways.de
http:
paths:
- backend:
serviceName: nginx-svc
servicePort: 80
kubectl describe service/my-ingress-nginx-ingress-controller
kubectl get service/my-ingress-nginx-ingress-controller -o jsonpath='{.status.loadBalancer.ingress[].ip}’
Virtual Hosts mit TLS
Natürlich bietet man selten Anwendungen ohne Verschlüsselung öffentlich erreichbar an. Speziell für TLS-Zertifikate hat Kubernetes einen eigenen Typ
tls innerhalb des
secret Objekts. Alles was man benötigt ist ein TLS-Zertifikat und den dazugehörigen Schlüssel. Mit
kubectl kannst Du das Pärchen in Kubernetes speichern:
kubectl create secret tls my-secret –key cert.key –cert cert.crt
Das angelegte secret kann dann durch den angegebenen Namen my-secret in spec des Ingress Objekts referenziert werden. Dazu gibst Du im Array hosts innerhalb von tls unser virtual host und das dazugehörige TLS-Zertifikat an. Ein automatischer Redirect von http auf https ist von Anfang an aktiviert.
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
name: my-ingress
spec:
tls:
- hosts:
- apache.nws.netways.de
- nginx.nws.netways.de
secretName: my-secret
rules:
- host: apache.nws.netways.de
http:
paths:
- backend:
serviceName: apache-svc
servicePort: 80
- host: nginx.nws.netways.de
http:
paths:
- backend:
serviceName: nginx-svc
servicePort: 80
Fazit
Mit dem Nginx Ingress Controller ist es eine Leichtigkeit, Deine webbasierten Anwendungen öffentlich erreichbar zu machen. Die angebotenen Features und Konfigurationsmöglichkeiten sollten die Anforderungen aller Anwendungen abdecken und sind im offiziellen User Guide zu finden. Neben der eigenen Anwendung benötigst Du nur ein Helm Chart und ein K8s Ingress-Objekt. Kubernetes schafft es auch hier, mit nur wenigen abstrakten Objekten wie deployment und ingress viele komplexe Ebenen und Technologien zu verstecken. Mit einer NETWAYS Managed Kubernetes Lösung kannst Du die Vorteile dieser Abstraktion voll ausnutzen und Dich auf die eigene Anwendung konzentrieren. Na also: Leg los!

von Achim Ledermüller | Mai 13, 2020 | Kubernetes, Tutorial
Du hast ein brand neues Kubernetes Cluster und willst jetzt loslegen? Aber egal, ob bei Dir ein lokales minikube läuft oder ob Du ein Managed Kubernetes mit allen Schikanen hast, die ersten Kubernetes-Objekte im super einfachem YAML-Format lassen fast jeden erstmal die Stirn runzeln. Was sind eigentlich deployments, services und Co? Und wozu die ganzen Labels? Versuchen wir Licht ins Dunkle zu bekommen.
Die wichtigsten Kubernetes-Objekte
 Zum Verwalten und Steuern eins Kubernetes Clusters verwendet man Kubernetes-API-Objekte, in welchen man den gewünschten Zustand des Clusters beschreibt. Diese werden im einfachen YAML-Format mit Hilfe von kubectl an das Cluster gesendet. Neben einer API-Version, Metadaten und der Objektart gibt es meistens noch den Abschnitt spec. In diesem beschreibt man den gewünschten Zustand seiner Anwendung. spec kann für jedes Objekt unterschiedlich definiert sein und ist in vielen Fällen verschachtelt. Zum Beispiel enthält ein Objekt deployment Attribute für ein Objekt replicaSet, welches wiederum im eigenen spec Abschnitt Attribute für ein pod Objekt hat. Aber bevor es zu kompliziert wird, erstmal eine kurze Erklärung dieser drei wichtigen Objekte:
Zum Verwalten und Steuern eins Kubernetes Clusters verwendet man Kubernetes-API-Objekte, in welchen man den gewünschten Zustand des Clusters beschreibt. Diese werden im einfachen YAML-Format mit Hilfe von kubectl an das Cluster gesendet. Neben einer API-Version, Metadaten und der Objektart gibt es meistens noch den Abschnitt spec. In diesem beschreibt man den gewünschten Zustand seiner Anwendung. spec kann für jedes Objekt unterschiedlich definiert sein und ist in vielen Fällen verschachtelt. Zum Beispiel enthält ein Objekt deployment Attribute für ein Objekt replicaSet, welches wiederum im eigenen spec Abschnitt Attribute für ein pod Objekt hat. Aber bevor es zu kompliziert wird, erstmal eine kurze Erklärung dieser drei wichtigen Objekte:
deployment
Ein deployment beschreibt einen gewünschten Zustand einer Anwendung und versucht, beständig diesen herzustellen. Mit deployments lassen sich Anwendungen starten, skalieren, aktualisieren, zurückrollen und löschen. In der Regel verwendet man deployment Objekte, um Anwendungen zu verwalten.
replicaSet
Ein replicaSet gewährleistet die Verfügbarkeit einer definierten Anzahl identischer Pods. Gegebenenfalls werden neue Pods gestartet und auch gestoppt. replicaSet verwendet man im Normalfall nur indirekt durch ein deployment.
pod
Ein pod definiert eine Gruppe von Containern (oftmals nur einer), die sich einen gemeinsamen Namespace auf einen Host teilen. Durch die gemeinsamen Namespaces (z.B. gemeinsames Dateisystem oder Netzwerk) ist eine einfache Kommunikation der Container erleichtert. Ein Pod ist immer durch eine eindeutige IP im Cluster erreichbar. Im Normalfall verwendet man Pods nur indirekt durch ein deployment.
Mit diesen drei Objekten können wir unser erstes MariaDB Deployment starten und eine erste Verbindung damit herstellen.
Das erste K8s-Deployment
Als erste einfache Anwendung starten wir eine nicht replizierte MariaDB als deployment. Bevor wir aber einen genauen Blick auf die Definition werfen, sende doch das Objekt mit kubectl apply an Dein Cluster:
Speichere einfach die mariadb.yaml auf Deinem Rechner und sende diese mit apply an Dein Cluster:
kubectl apply -f mariadb.yaml deployment.apps/mariadb-deploy created
Für Änderungen an Deinem deployment kannst Du die Yaml-Datei einfach anpassen und mit dem gleichen Befehl an Dein Cluster senden. Willst Du Dein deployment wieder löschen, ersetzt Du das apply einfach durch ein delete.
mariadb.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: mariadb-deploy
labels:
app: mariadb
spec:
replicas: 1
selector:
matchLabels:
app: mariadb
template:
metadata:
labels:
app: mariadb
spec:
containers:
- name: mariadb
image: mariadb
ports:
- containerPort: 3306
name: db-port
env:
- name: MYSQL_ROOT_PASSWORD
value: "123456"
Erklärung: Bei einem genaueren Blick finden wir im Beispiel Parameter für alle drei Kubernetes-Objekte. Zeile 1-6: Wir definieren API-Version, kind, Name und ein frei wählbares Label für unser deployment Objekt. Zeile 8-11: Sind Teil des replicaset (RS). Hier wird neben der Anzahl der replicas auch matchLabels definiert und es werden pods mit dem Label mariadb in das RS mit aufgenommen. Zeile 13-25: Definieren Deinen Pod. Neben einem Label werden Parameter für den MariaDB Container übergeben. Wir verwenden das offizielle MariaDB Image, definieren den Port 3306 und setzen über eine Environment-Variable das root-Passwort für die Datenbank.
Besserer Überblick mit describe und get
Mit describe und get kannst Du Dir einen schnellen Überblick verschaffen und alle nötigen Details Deiner Anwendungen bekommen. Ein einfaches kubectl describe deployment/mariadb-deploy liefert alle Details zum MariaDB Deployment aus dem Beispiel. get all hingegen listet alle Objekte auf, aber die Ausgabe kann auch schon mit wenigen Anwendungen im Cluster schnell unübersichtlich werden. Deshalb gibt es verschiedene Möglichkeiten zum Filtern der Ausgabe, z.B. anhand des Labels app. Mit folgenden Beispielen hast Du die Ausgabe aber schnell im Griff.
Beispiel für get mit verschiedenen Filtern
kubectl get pods
kubectl get deployment
kubectl get replicaset -l app=mariadb -o json
kubectl get po –field-selector=status.phase=Running
Die Komponenten Deiner MariaDB kannst Du am schnellsten mit dem Label Filter anzeigen:
kubectl get all -l app=mariadb
NAME READY STATUS RESTARTS AGE
pod/mariadb-deploy-64bfc599f7-j9twt 1/1 Running 0 64s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/mariadb-deploy 1/1 1 1 64s
NAME DESIRED CURRENT READY AGE
replicaset.apps/mariadb-deploy-64bfc599f7 1 1 1 64s
Nachdem Du jetzt weißt, wie Du den aktuellen und gewünschten Zustand Deiner Anwendung überprüfst, werfen wir nun einen genaueren Blick auf Pods und Container.
Mit Pods interagieren
Ohne weitere Konfiguration sind Anwendungen nur innerhalb des Kubernetes-Clusters erreichbar. Zudem will man selten eine Datenbank über eine öffentliche IP erreichbar machen. kubectl bietet deswegen mit proxy und port-forward zwei Möglichkeiten, um Zugriffe auf interne Pods und Services zu gewährleisten. Für MariaDB benutzen wir port-forward und senden sämtlichen Traffic der lokal auf Port 3306 ankommt durch kubectl an unseren MariaDB Pod. Du kannst übrigens direkt den Namen des deployments verwenden. Die Namen von pod und replicaSet führen aber zum selben Ergebnis. Mit telnet oder einem MySQL Client prüfst Du am schnellsten, ob die Verbindung funktioniert:
kubectl port-forward deployment.apps/mariadb-deploy 3306:3306
mysql -h 127.0.0.1 -P 3306 -u root -p123456
telnet 127.0.0.1 3306
Weitere Möglichkeiten, um mit seinem Container zu interagieren, bietet kubectl mit log und exec. Ersteres zeigt Dir natürlich stdout Deines Pods. exec hingegen wird wohl meistens zum Starten einer interaktiven Shell genutzt. Ähnlich wie bei docker benötigt man die Parameter interactive und tty (-ti), um eine funktionsfähige Bash zu erhalten:
kubectl exec -it mariadb-deploy-64bfc599f7-j9twt — /bin/bash
Mit diesen wenigen Befehlen kannst Du Deine im K8s-Cluster abgeschirmten Pods erreichen und debuggen. Anwendungen, die nur innerhalb des Clusters erreichbar sind, machen natürlich nicht immer Sinn. Damit auch andere darauf zugreifen können, benötigst du einen Kubernetes service mit öffentlicher IP. Hinter einem service steckt aber noch viel mehr.
Verbinde deine Pods mit einem service
Ein service bindet eine feste interne IP-Adresse (ClusterIP) an eine Menge von Pods, welche durch Labels identifiziert werden. Im Vergleich zu einem service sind pods sehr kurzlebig. Sobald wir im Beispiel ein Upgrade der MariaDB anstoßen, verwirft unser deployment den vorhanden Pod und startet einen neuen. Da jeder Pod seine eigenen IP-Adresse hat, ändert sich auch die IP-Adresse, unter welcher deine MariaDB erreichbar ist. Dank der Labels findet der service den neuen Pod und der Traffic wird richtig weitergeleitet. Ein service gewährleistet somit durch die ClusterIP die interne Erreichbarkeit deiner deployments. Zusätzlich kann ein service auch den Typ Loadbalancer haben. Dadurch wird eine öffentliche IP gebunden und sämtlicher Traffic an die ClusterIP weitergegeben. Im folgenden Beispiel siehst siehst Du einen service für deine MariaDB.
Neben API-Version, kind und metadata gibt es wieder den Abschnitt spec. Protocol, port und targetPort definieren, welcher Traffic weitergereicht wird. Im selector wird anhand der Labels festgelegt, welche Pods bedient werden sollen. Mit der optionalen Zeile type: LoadBalancer wird neben einer internen ClusterIP auch eine öffentliche IP gebunden.
apiVersion: v1
kind: Service
metadata:
name: mariadb-service
spec:
ports:
- port: 3306
targetPort: 3306
protocol: TCP
name: mariadb
selector:
app: mariadb
type: LoadBalancer
Im Beispiel ist für einen Pod genau ein Container definiert und unser selector im Server greift auch nur für einen Pod. Was passiert aber, wenn replicas in der Deployment erhöht wird? Zuerst werden natürlich mehrere Pods gestartet und somit auch mehrere MariaDB-Container. Der selector im MariaDB Service findet diese natürlich anhand des Labels und die Verbindungen werden im round-robin Verfahren an die Pods weitergeleitet. Technisch funktioniert dies im Beispiel auch ohne Probleme, solang MariaDB selbst aber nicht als replizierendes Cluster installiert ist, macht dies aber wenig Sinn.
Was kommt als nächstes?
Mit den hier gezeigten Beispielen kann man seine ersten Anwendungen ausrollen und debuggen. Aber Du ahnst bereits, dass wir nur etwas am Lack von Kubernetes gekratzt haben und es stellen sich natürlich noch viele Fragen! Was passiert mit meinen Daten in MariaDB und wie kann ich die kurzlebigen Pods mit einem persistentem Volume verbinden? Brauche ich für jede Anwendung eine eigene öffentliche IP? Wie komme ich an Metriken und Logs meines Clusters und meiner Anwendungen? Diese und weitere Fragen werden wir natürlich in den folgenden Blogposts beantworten. Also dann, bis nächste Woche!

von Achim Ledermüller | Mai 6, 2020 | Kubernetes, Tutorial
Dich interessiert, wie Du ein Managed Kubernetes bei NWS startest? Hier erfährst Du, wie du loslegen kannst! Zuerst benötigst Du einen Account für unsere NETWAYS Web Services Plattform. Nach der Registrierung kannst Du unsere Open Source-Apps wie RocketChat und GitLab starten und auch Zugänge zu Openstack und Kubernetes anlegen.
tl;dr – Schau dir unsere Demo an!
Christian zeigt Dir unser Managed Kubernetes übrigens im aufgezeichneten Webinar. Bilder sagen mehr als Tausend Worte?
Du entscheidest Dich natürlich für einen Kubernetes-Zugang und kommst nach wenigen Klicks zur Ansicht zum Verwalten und Starten deiner Kubernetes Cluster.
Starte Dein Kubernetes Cluster
Das schwierigste beim Starten Deines Clusters ist wohl die Wahl des Namens. Das können wir Dir leider nicht abnehmen. Wie wäre es mit foobar? Aber bevor virtuelle Maschinen im Hintergrund starten, musst Du Dich jetzt noch für eine Control Plane entscheiden und die Anzahl deiner Worker Nodes festlegen.
Control Plane
Als Control Plane werden alle nötigen Dienste und Ressourcen zur Verwaltung und Steuerung deines Kubernetes Clusters bezeichnet. Diese Dienste können auf einem oder auf drei Master Nodes (VMs) gestartet werden. Letzteres hat den Vorteil, dass in einem Fehlerfall oder bei einem Update die Kubernetes-Dienste und -API trotzdem verfügbar sind. Zudem muss je nach Größe des geplanten Clusters ein Flavor für diese Master Nodes gewählt werden. Bitte beachte, dass Du die Anzahl der Master Nodes und den Flavor später nicht mehr ändern kannst.
Worker Nodes
Auf den Worker Nodes werden Deine Anwendungen gestartet, welche durch die Control Plane verwaltet und betrieben werden. Für eine hochverfügbare Anwendung benötigst Du davon mindestens zwei. Wie auch bei den Master Nodes musst Du ein Flavor auswählen. Aufgrund der auf Ressourcen basierenden Abrechnung fallen zum Beispiel für 16GB Ram immer die selben Kosten an, egal ob diese auf zwei oder vier VMs verteilt werden. Die Anzahl der Worker Nodes kannst Du jederzeit im NWS Webinterface an Deinen aktuellen Bedarf anpassen. Das Starten des Clusters kann je nach Anzahl der Master- und Worker Nodes fünf bis 15 Minuten dauern. Es ist also genug Zeit für einen Kaffee. Im Hintergrund werden VMs, Floating IPs, Loadbalancer, Security Groups und vieles mehr Stück für Stück gestartet, konfiguriert und geprüft, bis Dein Kubernetes einsatzfähig ist. Und jetzt?
Verschaffe Dir einen Überblick im NWS Webinterface
Nachdem dein Cluster gestartet ist, gibt Dir das NWS Webinterface einen guten ersten Überblick. Dort findest Du wichtige Informationen und andere Möglichkeiten, um Dein Cluster zu steuern:
Zustand und Worker Nodes
Den Status Deiner Master- und Worker Nodes sowie die Erreichbarkeit der API kannst Du jederzeit im NWS Webinterface überprüfen. Solltest Du mehr Ressourcen benötigen, kannst Du die Anzahl Deiner Worker Nodes mit einigen wenigen Klicks anpassen und im Problemfall auch einen harten Neustart einzelner VMs durchführen.
Kubernetes Dashboard
Für einen einfacheren Einstieg haben wir bereits das Kubernetes Dashboard für Dich ausgerollt und vorbereitet. Ein einfacher Einblick gelingt in drei kleinen Schritten.
Object Store
Mit dem Start des Clusters bekommst Du auch einen Zugang zu unserem Object Store. Dieser basiert auf Ceph und ist mit der S3- und Swift-API kompatibel. Deine Daten werden über unsere ISO-27001 zertifizierten Rechenzentren repliziert und bleiben in Deutschland.
Cluster Update
Um Kubernetes Cluster-Updates für Dich so einfach wie möglich zu gestalten, werden diese von uns gründlich getestet. Aber damit Du die Kontrolle behältst, entscheidest Du per Knopfdruck, wann die Updates eingespielt werden. Neben den Kubernetes-Diensten wird auch das Betriebssystem der VMs aktualisiert. Im Falle einer hochverfügbaren Control Plane werden die Komponenten Stück für Stück aktualisiert, so dass kein Serviceausfall entsteht. Auch auf Deinen Worker Nodes werden die Anwendungen verschoben, so dass nach und nach einzelne VMs aktualisiert und neu gestartet werden können.
kubeconfig
Als kubeconfig bezeichnet man eine Datei, die alle Informationen enthält, um über das Kommando kubectl auf die Kubernetes-API zuzugreifen. Technisch enthält diese YAML-Datei den HTTP-Endpunkt der API, einen Benutzernamen und ein TLS-Client-Zertifikat mit CA. Im Webinterface kannst Du die Datei natürlich herunterladen und gleich unter $HOME/.kube/config speichern. Somit kannst Du ohne weitere Parameter Dein Cluster mit kubectl erkunden. Wie Du dies am schnellsten für Dein Betriebssystem installierst, erfährst du am besten aus der offiziellen Dokumentation.
Starte mit kubectl auf der Kommandozeile
Beim täglichen Arbeiten mit Kubernetes benötigst Du unser Webinterface leider nicht sehr oft. Die meiste Zeit wirst du auf der Kommandozeile verbringen. kubectl ist hier das zentrale Tool, um Deine Anwendungen im Cluster zu steuern. Zunächst solltest Du ein paar einfache Kommandos ausführen, um mit Deinem Cluster vertraut zu werden:
kubectl get nodes
Zeigt eine Liste deiner Nodes mit Status und Version.
kubectl describe node <Name>
Neben Labels, Pods und Metriken bekommst Du viele detaillierte Information zu Deinen Nodes.
kubectl explain <Ressourcentyp>
Mit explain kannst Du Dir schnell weitere Informationen zu einzelnen Ressourcentypen holen.
kubectl get all
Zeigt Dir eine Übersicht aller laufenden Ressourcen im default Namespace.
Mit –all-namespaces siehst Du nicht nur Deine Anwendungen, sondern auch die Ressourcen des Kubernetes Clusters selbst. Mit der kubeconfig und kubectl hast Du nun alles an der Hand, um zu starten. Mit was? Mit Teil 3 unserer Serie und deinen ersten Schritten in Kubernetes. Dort erfährst Du mehr über deployments, pods und services und wie Du Deine erste Anwendung ausrollst.
Recent Comments