
Im Jahr 2010 wurde eine Lösung entwickelt, um die massiven Skalierbarkeitsprobleme von MySQL bei YouTube zu lösen – und somit war Vitess geboren. Später – im Jahr 2018 – wurde das Projekt Teil der Cloud Native Computing Foundation und ist seit 2019 als eines der graduierten Projekte gelistet: Damit befindet es sich in guter Gesellschaft mit anderen prominenten CNCF-Projekten wie Kubernetes, Prometheus und einigen mehr.
Vitess ist ein Open-Source-MySQL-kompatibles Datenbank-Clustering-System für horizontale Skalierung – man könnte auch sagen, es ist eine Sharding Zwischenanwendung für MySQL. Es kombiniert und erweitert viele wichtige SQL-Features mit der Skalierbarkeit einer NoSQL-Datenbank und löst zahlreiche Herausforderungen beim Betrieb gewöhnlicher MySQL-Setups. Mit Vitess wird MySQL massiv skalierbar und hochverfügbar. Vitess ist von Natur aus Cloud-nativ, kann aber auch auf Bare-Metal-Umgebungen betrieben werden.
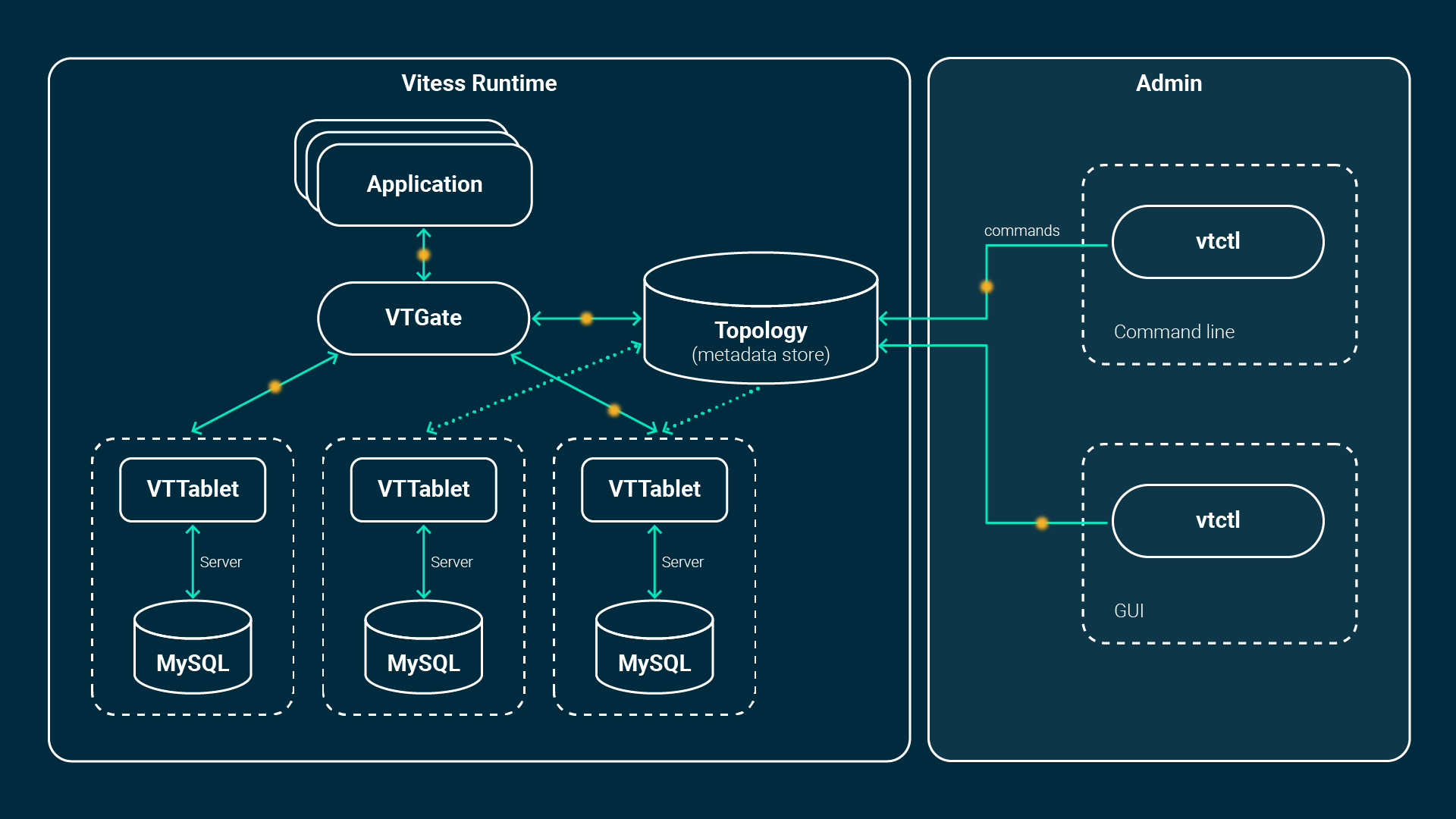
Architektur
Die Architektur besteht aus mehreren zusätzlichen Komponenten wie VTGate, VTTablet, VTctld und einem Topology Service, der von etcd oder zookeeper unterstützt wird. Die Anwendung verbindet sich entweder über die nativen Datenbanktreiber von Vitess oder über das MySQL-Protokoll: Das bedeutet, dass alle MySQL-Clients und Bibliotheken kompatibel sind.
Die Anwendung verbindet sich mit dem so genannten VTGate – einer Art leichtgewichtigem Proxy -, der den Zustand der MySQL-Instanzen (VTTablets) kennt und weiß, wo welche Daten im Falle von Sharded-Datenbanken gespeichert sind. Diese Informationen werden im Topology Service gespeichert. Das VTGate leitet die Abfragen entsprechend an die zugehörigen VTTablets weiter.
Ein Tablet wiederum ist die Kombination aus einem VTTablet-Prozess und der MySQL-Instanz selbst. Es läuft entweder im primären, im Replikations- oder im Nur-Lese-Modus, wenn es gesund ist. Es gibt eine Replikation zwischen einem primären und mehreren Replikas pro Datenbank. Wenn eine Primärinstanz ausfällt, wird eine Replika hochgestuft und Vitess hilft bei der Wiederherstellung. Dies alles kann vollständig automatisiert werden. Neue, zusätzliche oder ausgefallene Replikas werden von Grund auf neu instanziiert. Sie erhalten die Daten des letzten verfügbaren Backups und werden an die Replikation angeschlossen. Sobald die Daten verfügbar sind, sind sie Teil des Clusters und VTGate leitet Queries an sie weiter.
Philosophie der Skalierbarkeit
Vitess versucht, kleine Instanzen zu betreiben, die nicht mehr als 250 GB an Daten enthalten. Wenn Ihre Datenbank größer wird, muss sie in mehrere Instanzen aufgeteilt werden. Dieser Ansatz hat mehrere gute betriebliche Vorteile. Im Falle des Ausfalls einer Instanz, kann diese mit weniger Daten viel schneller wiederhergestellt werden. Die Wiederherstellungszeit wird durch die schnellere Übertragung von Sicherungskopien verkürzt. Auch die Replikation verläuft in der Regel reibungsloser und mit weniger Verzögerung. Das Verschieben von Instanzen und deren Platzierung auf verschiedenen Nodes für eine bessere Ressourcennutzung, ist ebenfalls ein Vorteil.
Durch die Replikation wird die Haltbarkeit der Daten gewährleistet. Ausfälle von bestimmten Fehlerdomains bzw. Ausfälle generell, sind ganz normal. In Cloud-nativen Umgebungen ist es noch normaler, dass Nodes und Pods entleert oder neu erstellt werden und man versucht, so flexibel wie möglich auf solche Ereignisse zu reagieren. Vitess ist genau dafür konzipiert und passt mit seinen vollautomatisierten Wiederherstellungs- und Reparenting-Fähigkeiten perfekt zu einer Cloud-nativen Umgebung wie Kubernetes.
Darüber hinaus ist Vitess dafür gedacht, über Rechenzentren, Regionen oder Verfügbarkeitszonen hinweg betrieben zu werden. Jede Domain hat ihr eigenes VTGate und einen eigenen Pool von Tablets. Dieses Konzept wird als „Cells in Vitess“ bezeichnet. Wir bei NETWAYS Web Services verteilen die Replikas gleichmäßig über unsere Verfügbarkeitszonen, um einen kompletten Ausfall einer Zone zu überstehen. Es wäre auch möglich, Replikas in geografischen Regionen zu betreiben, um die Latenzzeit und die Erfahrung für Kunden im Ausland zu verbessern.
Zusätzliche Features
Neben der Cloud-nativen Natur und den Möglichkeiten der endlosen Skalierbarkeit, gibt es noch weitere praktische und clevere Funktionen.
- Connection pooling und Deduplication
Normalerweise muss MySQL für jede Verbindung etwas (~ 256KB – 3MB) Speicher zuweisen. Dieser Speicher ist nur für die Verbindungen und nicht für die Beschleunigung von Queries gedacht. Vitess erstellt stattdessen sehr leichtgewichtige Verbindungen, indem es den Concurrency Support von Go nutzt. Diese Frontend-Verbindungen werden dann auf weniger Verbindungen zu den MySQL-Instanzen gepooled, so dass es möglich ist, Tausende von Verbindungen reibungslos und effizient zu verarbeiten. Außerdem werden identische Queries in-flight registriert und zurückgehalten, sodass nur eine Anfrage auf die Datenbank trifft. - Query- und Transaction Protection
Hattest Du schon mal das Bedürfnis, lang laufende Queries zu beenden, die Deine Datenbank lahmgelegt haben? Vitess begrenzt die Anzahl der gleichzeitigen Transaktionen und setzt angemessene Timeouts für jede. Queries, die zu lange dauern, werden abgebrochen. Auch schlecht geschriebene Queries ohne LIMITS werden umgeschrieben und begrenzt, bevor sie dem System schaden können. - Sharding
Die integrierten Sharding-Funktionen ermöglichen das Wachstum der Datenbank in Form von Sharding, ohne dass zusätzliche Application Logic hinzugefügt werden muss. - Performance Monitoring
Mit den Tools zur Leistungsanalyse kannst Du die Leistung Deiner Datenbank überwachen, diagnostizieren und analysieren. - VReplikation und Workflows
VReplikation ist ein Schlüsselmechanismus von Vitess. Bei der VReplikation werden Ereignisse des Binlogs vom Sender zu einem Empfänger gestreamt. Workflows sind – wie der Name schon sagt – Abläufe zur Erledigung bestimmter Queries: So kann zum Beispiel eine laufende Production Table nahezu ohne Ausfallzeit auf eine andere Datenbankinstanz verschoben werden („MoveTable„). Auch das Streaming einer Teilmenge von Daten in eine andere Instanz kann mit diesem Konzept durchgeführt werden. Eine „materialisierte Ansicht“ ist praktisch, wenn Du Daten zusammenführen musst, die Tabellen aber auf verschiedenen Instanzen verteilt sind.
Fazit
Vitess ist ein sehr leistungsfähiges und cleveres Stück Software! Um genau zu sagen, ist es eine Software, die von Hyperscalern verwendet wird, aber nun für die breite Masse zugänglich gemacht wurde und somit für alle verfügbar. Wenn Du mehr darüber erfahren möchtest, werden wir zukünftig regelmäßig weitere Tutorials veröffentlichen, die fortgeschrittene Themen abdecken werden. Die Dokumentation von vitess.io ist auch eine gute Quelle, um mehr zu erfahren. Wenn Du es selbst mal ausprobieren willst, gibt es mehrere Möglichkeiten: Der bequemste Weg ist, unser Managed Database Produkt zu verwenden und auf unsere Erfahrung zu vertrauen.









