
von Daniel Bodky | Jul 25, 2024 | Kubernetes, Tutorial
Heutzutage finden immer mehr zustandsbehaftete Anwendungen ihren Weg in produktive Kubernetes-Cluster. Daher ist es wahrscheinlich, dass Du bereits persistente Volumes oder persistente Volume-Claims (PVs/PVCs) für die von Dir oder deiner Organisation bereitgestellten Workloads verwendest. Wenn Du diese Anwendungen gründlich absichern willst, musst Du dich auch um Deine Daten kümmern. Ein guter erster Schritt ist die Verwendung von verschlüsseltem Speicher in Kubernetes. In diesem Tutorial zeigen wir Dir, wie Du verschlüsselten Speicher in MyNWS Managed Kubernetes Clustern einrichtest.
Wusstest Du schon?
Du kannst dieses Tutorial entweder in deinem eigenen MyNWS Managed Cluster nachverfolgen, oder aber Du nutzt unseren interaktiven Playground – er ist komplett kostenlos!
Voraussetzungen
Um den verschlüsselten Speicher in Kubernetes Clustern auf MyNWS auszuprobieren, musst Du zunächst ein Cluster erstellen. Das kannst Du über das Kubernetes-Menü auf dem MyNWS-Dashboard. Für dieses Tutorial ist die kleinstmögliche Konfiguration, bestehend aus einem Control-Plane-Node der Größe s1.medium und einem Worker-Node der Größe s1.medium, ausreichend. Stelle sicher, dass Dein Cluster öffentlich zugänglich ist, damit Du es über das Internet erreichen kannst, und klicke auf Create.
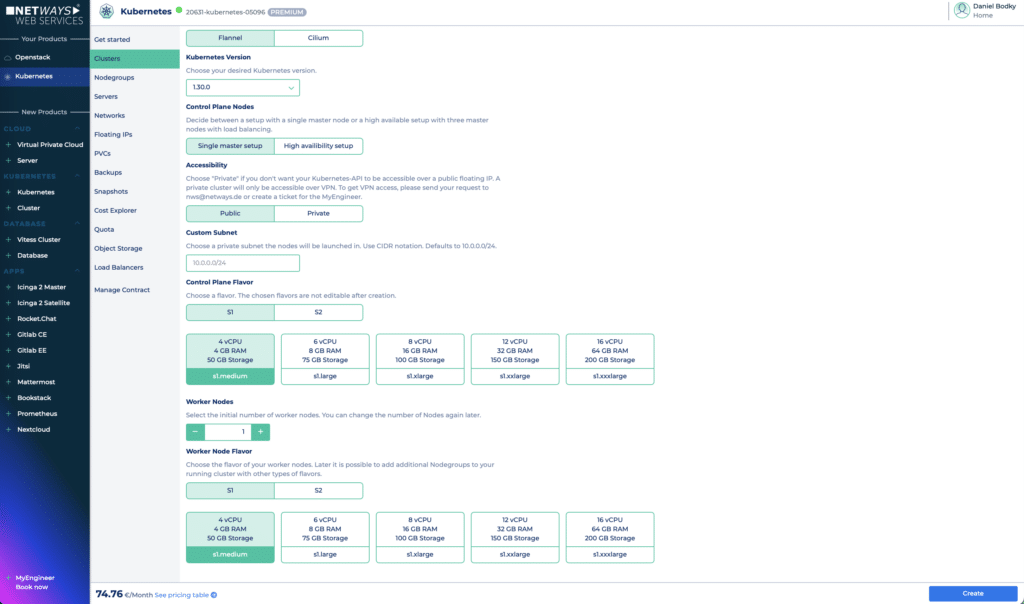
Um verschlüsselten Speicher in Kubernetes zu nutzen, stelle sicher, dass Deine Clustereinstellungen ähnlich wie auf dem Screenshot aussehen.
Nach ein paar Minuten ist Dein Cluster bereit. Lade Deine kubeconfig wie unten gezeigt herunter (Du kannst zwischen einer OIDC-basierten Konfiguration oder einer Admin-Konfiguration wählen), und wir können mit der Erkundung unserer Speicheroptionen beginnen.
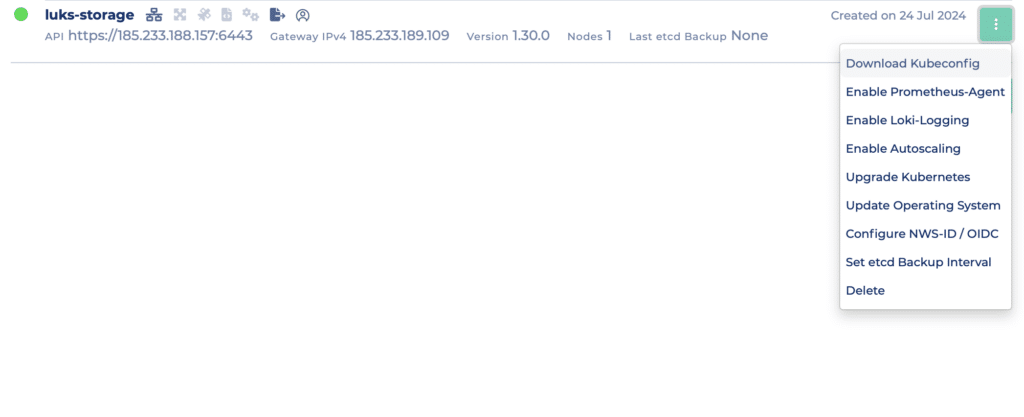
Downloade die kubeconfig deines Clusters über das Cluster-Kontextmenü.
Prüfen der verfügbaren Speicheroptionen
Sobald wir unsere kubeconfig-Datei haben und uns mit unserem Cluster verbinden können, können wir mit dem folgenden Befehl alle StorageClasses anzeigen, die in unserem Cluster verfügbar sind:
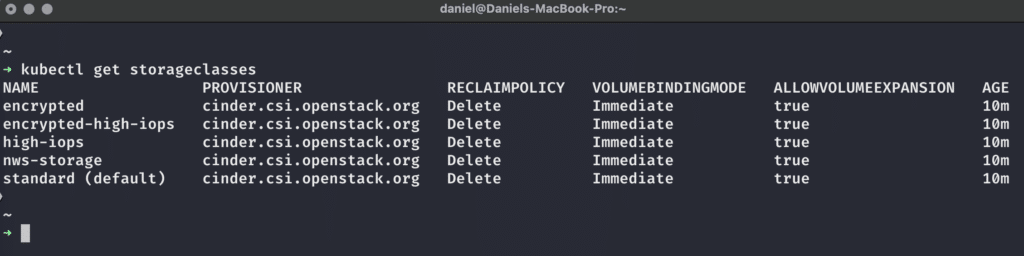
Bei MyNWS Managed Kubernetes-Clustern sind fünf verschiedene StorageClasses standardmäßig verfügbar.
Wie wir sehen können, sind alle verfügbaren StorageClasses in Bezug auf Provisioner, ReclaimPolicy, VolumeBindingMode und AllowVolumeExpansion auf die gleiche Weise konfiguriert – für weitere Informationen zu diesen Themen schaue bitte in die offizielle Kubernetes-Dokumentation. Der interessanteste Teil für uns ist im Moment der Provisioner – es ist cinder.csi.openstack.org für alle StorageClasses. Das bedeutet, dass OpenStack hinter den Kulissen die Erstellung, Verwaltung und Löschung der PersistentVolumes in unseren Kubernetes-Clustern für uns übernimmt. Aber was bedeuten diese StorageClass-Namen?
- standard ist als default eingestellt und stellt ein ext4-formatiertes OpenStack-Volume mit einem IOPS-Limit von 1000 IOPS und Bursts von bis zu 2000 IOPS bereit.
- nws-storage ist ähnlich wie standard, aber formatiert das OpenStack-Volume als xfs statt ext4.
- high-iops ist eine schnellere Variante von nws-storage, mit einem IOPS-Limit von 2000 IOPS und Bursts von bis zu 4000IOPS.
- encrypted nutzt ein OpenStack-Volume, das transparent LUKS-verschlüsselten Speicher bietet, mit den IOPS-Grenzen von nws-storage.
- encrypted-high-iops kombiniert die Konfigurationen von high-iops und encrypted
Weitere Informationen zu den verfügbaren StorageClasses in MyNWS Managed Kubernetes und wie Du eigene definieren kannst, findest Du in unserer Dokumentation. Dieses Standard-Setup ist für eine Vielzahl von Anwendungsanforderungen geeignet: Anwendungen, die viel langsamen und/oder schnellen Speicher benötigen, der keine sensiblen Daten enthält, können die default-, nws-storage- oder high-iops-StorageClasses verwenden, während sensible Daten mit den encrypted(-high-iops)-StorageClasses LUKS-verschlüsselten Speicher in Kubernetes nutzen können. Aber wie verwendet man sie, und wie funktionieren sie?
Anfragen von verschlüsseltem Speicher in Kubernetes
Kubernetes bietet uns eine nützliche API für die programmatische Anforderung von Speicher jeder Art von StorageClass – einen PersistentVolumeClaim (PVC). Man definiert ihn als Objekt für die API von Kubernetes, z. B. über ein YAML-Manifest, und Kubernetes und die externen Provisioner übernehmen die tatsächliche Arbeit. In unserem Fall bedeutet das, dass der cinder.csi.openstack.org-Provisioner sich um die folgenden Dinge kümmert, wenn wir verschlüsselten Speicher auf MyNWS Managed Kubernetes anfordern:
- Erstellung des Verschlüsselungsschlüssel im OpenStack-Schlüsselverwaltungssystem (KMS) Barbican.
- Erstellung eines LUKS-verschlüsseltes Volumes in OpenStack.
- Bereitstellung des Volumes für unsere Workloads in Kubernetes, bereits entschlüsselt und einsatzbereit!
Schauen wir uns das in Aktion an: Unten ist ein Beispiel für ein PVC-Manifest, das wir mit kubectl apply -f <Datei> auf unser Cluster anwenden können:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: encrypted-claim
namespace: default
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 8Gi
storageClassName: encrypted
Wir können den PVC mit kubectl get pvc -n default überprüfen und sehen, dass ein PVC erstellt und an ein PersistentVolume gebunden wurde, das dem eigentlichen, verschlüsselten Speicher entspricht, der uns von OpenStack zur Verfügung gestellt wird:

Dieser PVC ist an ein verschlüsseltes PV von 8GB Größe gebunden.
Schauen wir uns als nächstes an, ob wir das Volume innerhalb unserer Workloads verwenden können!
Zugriff auf verschlüsselten Speicher in Kubernetes
Als Nutzer eines Managed-Kubernetes-Angebots wollen wir uns wahrscheinlich nicht mit den Feinheiten von Key-Management-Systemen (KMS), Volume-Provisionern und der ständigen Ver- und Entschlüsselung unserer Volumes auseinandersetzen. Wir wollen einfach nur Storage in unseren Anwendungen nutzen, die auf Kubernetes laufen. Sehen wir uns also an, ob OpenStack und MyNWS Managed Kubernetes uns genau das ermöglichen, indem wir die folgende Demo–Anwendung auf unser Cluster anwenden:
apiVersion: apps/v1
kind: Deployment
metadata:
name: test-deployment
namespace: default
spec:
selector:
matchLabels:
app: nginx
replicas: 1
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
volumeMounts:
- name: encrypted-storage
mountPath: /data-encrypted
volumes:
- name: encrypted-storage
persistentVolumeClaim:
claimName: encrypted-claim
Nachdem wir dieses Manifest mit kubectl apply -f <Datei> auf unser Cluster angewendet haben, können wir den Status des Deployments überprüfen, um zu sehen, ob der Pod den referenzierten, verschlüsselten PersistentVolumeClaim erfolgreich mounten konnte:

Das Deployment und der darin enthaltene Pod sind betriebsbereit – das Mounten des verschlüsselten Volumes hat funktioniert!
Der letzte Test besteht nun darin, zu prüfen, ob wir von unserem NGINX-Pod aus von dem vermeintlich verschlüsselten Volume lesen und darauf schreiben können. Das können wir mit dieser Befehlsfolge tun:
kubectl exec -n default deployment/test-deployment -- \
/bin/sh -c 'touch /data-encrypted/test.txt && \
echo "Hello World!" > /data-encrypted/test.txt'
kubectl rollout restart -n default deployment/test-deployment
kubectl rollout status -n default --watch deployment/test-deployment
kubectl exec -n default deployment/test-deployment -- \
/bin/cat /data-encrypted/test.txt
Diese Sequenz wird…
- Eine Datei test.txt in unserem gemounteten verschlüsselten Volume innerhalb des Pods erstellen und Hello World! in diese Datei schreiben.
- Das Deployment restarten, damit wir sicherstellen können, dass die Daten tatsächlich persistiert wurden.
- Auf den erfolgreich durchgeführten Restart warten.
- Den Inhalt der Datei auslesen, die wir zuvor angelegt hatten
Und so wie es aussieht, hat es funktioniert! Wir können tatsächlich verschlüsselten Speicher in Kubernetes mit den LUKS-verschlüsselten Volumes von OpenStack nutzen, was uns die Mühe erspart, die Verschlüsselung selbst einzurichten.
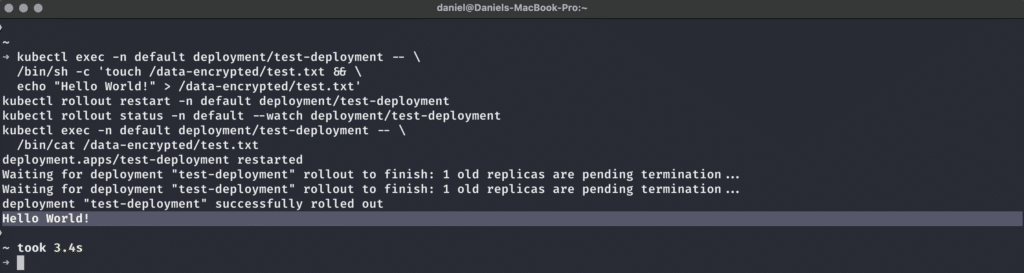
Unsere Daten bleiben dank PVC auch nach einem Neustart des Workloads erhalten, und die verschlüsselte Speicherung im Ruhezustand sorgt für erhöhte Sicherheit der Daten.
Für mehr Sicherheit!
Obwohl verschlüsselter Speicher in Kubernetes, unterstützt durch die OpenStack-Funktion für verschlüsselte Volumes, nur eine Verschlüsselung im Ruhezustand bietet, ist es dennoch ein weiterer (oder erster) Schritt in Richtung sicherer Workloads. Das Beste daran ist, dass wir nichts manuell tun müssen: Erstelle einfach einen PVC, der auf eine verschlüsselte Speicherklasse verweist, und OpenStack übernimmt die gesamte Arbeit, um Dir verschlüsselten Speicher in Kubernetes zur Verfügung zu stellen. Wenn Du weitere Fragen zu den technischen Details dieses Prozesses hast, zögere nicht, Dich mit unseren mit unseren MyEngineers in Verbindung zu setzen! Natürlich gehört zu Cloud-Native Sicherheit mehr als nur verschlüsselte Daten. Deshalb solltest Du unbedingt unseren Newsletter abonnieren und die Augen offen halten nach Inhaltne zu Service Meshes, Policy Engines und anderen Sicherheitsmaßnahmen, die wir in Zukunft gerne mit und für Dich erkunden möchten.

von Daniel Bodky | Jul 16, 2024 | Kubernetes
Stelle Dir vor, Dein Unternehmen hat sich für eine Microservice-Architektur entschieden. Während Du immer mehr Microservices entwickelst und bereitstellst, beschließt Du, diese mithilfe von Kubernetes zu orchestrieren. Du beginnst mit dem Schreiben von YAML-Manifesten und zusätzlichen Konfigurationen und stellst die erforderlichen Tools in Deinem Cluster bereit. Irgendwann wechselst Du aus Gründen der Konfigurierbarkeit zu Kustomize oder Helm.
Vielleicht verwendest Du schließlich ArgoCD oder Flux für einen GitOps-Ansatz. Irgendwann reichen Kustomize und Helm nicht mehr aus – zu viel YAML, zu wenig Überblick über das, was man eigentlich tut. Du ertappst dich dabei, wie Du Kubernetes Deployment Tools recherchierst und vergleichst.
Unabhängig davon, ob Du Dir dieses Szenario in Deinem Kopf ausmalen musstest oder es selbst erlebt hast (oder es gerade erlebst) – es ist kein schöner Zustand. Helm und Kustomize sind zuverlässige, gut etablierte Tools, die tief in das Kubernetes-Ökosystem integriert sind. Dennoch mangelt es ihnen an Benutzerfreundlichkeit und Ergonomie, und sie bieten keine wirklich tolle Entwicklererfahrung – es ist Zeit für einen Nachfolger!
Da Du und ich nicht die Einzigen sind, denen es so geht, gibt es heute eine Handvoll Tools, die alle versuchen, verschiedene Probleme bei der Anwendungsbereitstellung unter Kubernetes zu lösen, und ich werde diese Kubernetes Deployment Tools für Dich vergleichen.
Schauen wir sie uns an: Timoni, kapp und Glasskube.
Timoni – Distribution und Lifecycle-Management für Cloud-Native Anwendungen
Timoni verspricht, die CUE-Funktionen für Typsicherheit, Codegenerierung und Datenvalidierung in Kubernetes einzubringen, um die Erstellung komplexer Deployments zu einem angenehmen Erlebnis zu machen – das klingt doch gut! Aber was ist CUE?
CUE ist eine Open-Source-Datenvalidierungssprache, die ihre Wurzeln in der Logikprogrammierung hat. Als solche ist sie an der Schnittstelle zwischen Zustandsbeschreibung, Zustandsableitung und Zustandsvalidierung angesiedelt – klingt nach einer perfekten Lösung für ein Deployment-Tool, aber wie funktioniert sie?
Timoni baut auf vier Konzepten auf – Modulen, Instanzen, Bundles und Artefakten, jedes mit seinen eigenen Implikationen und zugehörigen Aktionen in der Timoni CLI:
- Timoni-Module sind eine Sammlung von CUE-Definitionen und -Einschränkungen, die ein CUE-Modul einer meinungsbildenden Struktur bilden.
Diese Module akzeptieren eine Reihe von definierten Eingabewerten von einem Benutzer und generieren eine Reihe von Kubernetes-Manifesten als Ausgabe, die von Timoni in Ihren Kubernetes-Cluster(n) bereitgestellt wird.
Timoni-Module können als Äquivalent zu z.B. Helm Charts betrachtet werden.
- Timoni-Instanzen sind bestehende Installationen von Timoni-Modulen innerhalb Ihres Clusters bzw. Ihrer Cluster.
Mit Timoni kann ein und dasselbe Modul mehrfach in einem Cluster installiert werden, wobei jede Instanz ihren eigenen Satz an bereitgestellten Werten hat.
Timoni-Instanzen können als Äquivalent zu Helm-Releases betrachtet werden.
- Timoni Bundles erlauben es den Autoren, sowohl Modulreferenzen als auch Instanzwerte innerhalb desselben Artefakts auszuliefern und einzusetzen.
Auf diese Weise können Anwendungen zusammen mit ihrer benötigten Infrastruktur ausgeliefert werden.
Timoni Bundles können als Äquivalent zu Umbrella Charts in Helm betrachtet werden.
- Timoni-Artefakte sind der vorgesehene Weg, um Module und Bundles zu verteilen.
Timoni kommt mit seinen eigenen OCI-Mediatypes und setzt zusätzliche Metadaten aus Git-Metadaten, um reproduzierbare Builds zu ermöglichen.
Auf diese Weise können Module und Bundles signiert und miteinander verglichen werden und sicher verteilt werden.
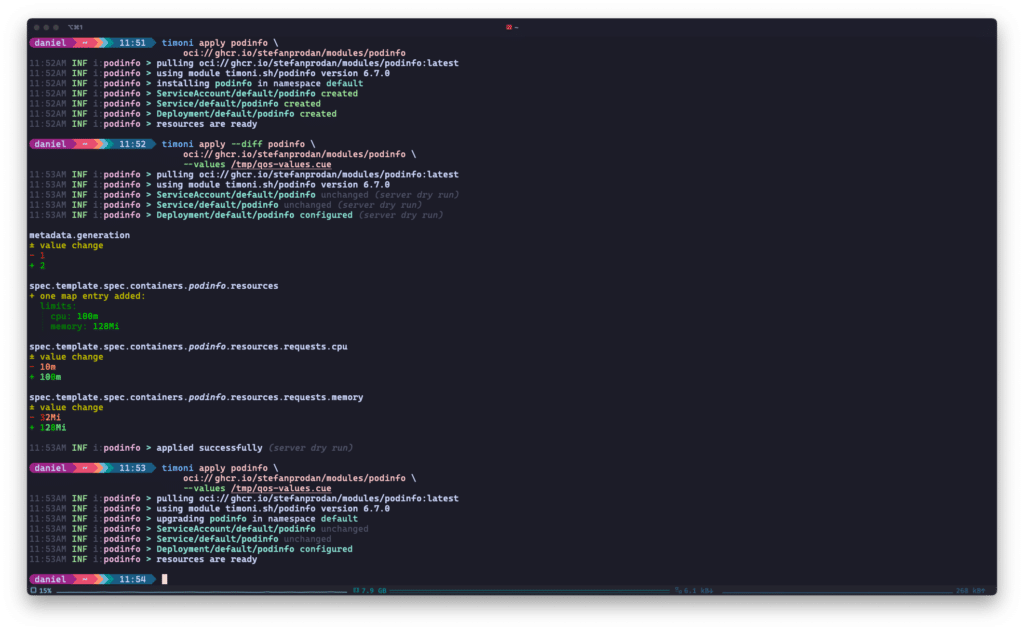
Timoni listet die Änderungen an Ihren Kubernetes Deployments beim Upgrade auf und patcht die Ressourcen nur dort, wo es nötig ist. Das Beispiel stammt aus Timonis Quickstart.
Das Fazit
Beim Vergleich von Timoni mit bestehenden Kubernetes-Deployment-Tools wie Helm oder Kustomize lassen sich einige Vorteile herausstellen:
- Geschwindigkeit: Timoni nutzt Kubernetes‘ server-side apply in Kombination mit der Drift-Erkennung von Flux und patcht nur die Manifeste, die sich zwischen den Upgrades geändert haben.
- Ausführlichkeit: Timoni kann Dir genau sagen, was es ändern wird, bis hin zu den Kubernetes-Ressourcen und ihren Eigenschaften.
- Validierung: Da Module eine Sammlung von CUE-Definitionen und -Einschränkungen sind, kann Timoni korrekte Datentypen oder sogar Werte (z. B. Enums) für Deployments erzwingen.
- Sicherheit und Verteilung: Während Helmcharts seit letztem Jahr als OCI-Artefakte verteilt werden können, mangelt es ihnen noch immer an Reproduzierbarkeit in einigen Bereichen.Kustomize bietet keinerlei Verteilungsmechanismen an.
Timoni hat an diese Dinge von Anfang an gedacht und bietet eine schlanke, unterstützte und sichere Art der Verteilung.
Insgesamt könnte Timoni eine gute Wahl für Dich sein, wenn Du Geschwindigkeit, Sicherheit und Korrektheit in Deinen Kubernetes-Bereitstellungstools suchst. Timoni kann große und komplexe Anwendungen bereitstellen, die aus vielen Manifesten bestehen, und gleichzeitig Konfigurationseinschränkungen für die Betreiber mit CUE definieren.
Die Kehrseite der Medaille ist, dass CUElang selbst eine Lernkurve aufweist und nicht agnostisch „GitOps-ready“ ist: Während es eine dokumentierte Möglichkeit gibt, Timoni mit Flux zu verwenden, gibt es keine Entsprechung für z.B. ArgoCD. Dies wird sich wahrscheinlich ändern, sobald Timonis API ausgereift ist.
Werfen wir als nächstes einen Blick auf kapp und sehen wir uns an, wie es Kubernetes Deployments vereinfachen kann!
kapp – Übernehmen Sie die Kontrolle über Ihre Kubernetes-Ressourcen
kapp ist Teil von Carvel, einer Reihe von zuverlässigen, kompatiblen Einzweck-Tools, die Sie bei der Erstellung, Konfiguration und Bereitstellung von Anwendungen für Kubernetes unterstützen. Laut der Website ist es leichtgewichtig, explizit und dependency-aware. Schauen wir uns das mal an:
- leichtgewichtig: kapp ist eine clientseitige CLI, die nicht auf serverseitige Komponenten angewiesen ist und daher z.B. in Umgebungen mit eingeschränktem RBAC funktionieren kann.
- explizit: kapp berechnet die Erstellung, Löschung und Aktualisierung von Ressourcen im Voraus und meldet sie dem Benutzer. Es liegt an ihm, diese Aktionen zu bestätigen.
kapp loggtt auch den Deploymentvorgang während der Installation in großem Detail.
- dependency-aware: kapp ordnet die Ressourcen, die es installieren soll. Das bedeutet, dass z.B. Namespaces oder CRDs vor anderen Ressourcen angewendet werden, die möglicherweise von ihnen abhängen.
Es ist möglich, benutzerdefinierte Abhängigkeiten hinzuzufügen, z.B. um Housekeeping-Jobs vor oder nach einem Anwendungs-Upgrade auszuführen.
Ähnlich wie Timoni legt kapp sehr ausführlich dar, was es in Deinem Namen tun wird, und führt Dic durch den Prozess der Bereitstellung Ihrer Anwendung(en):
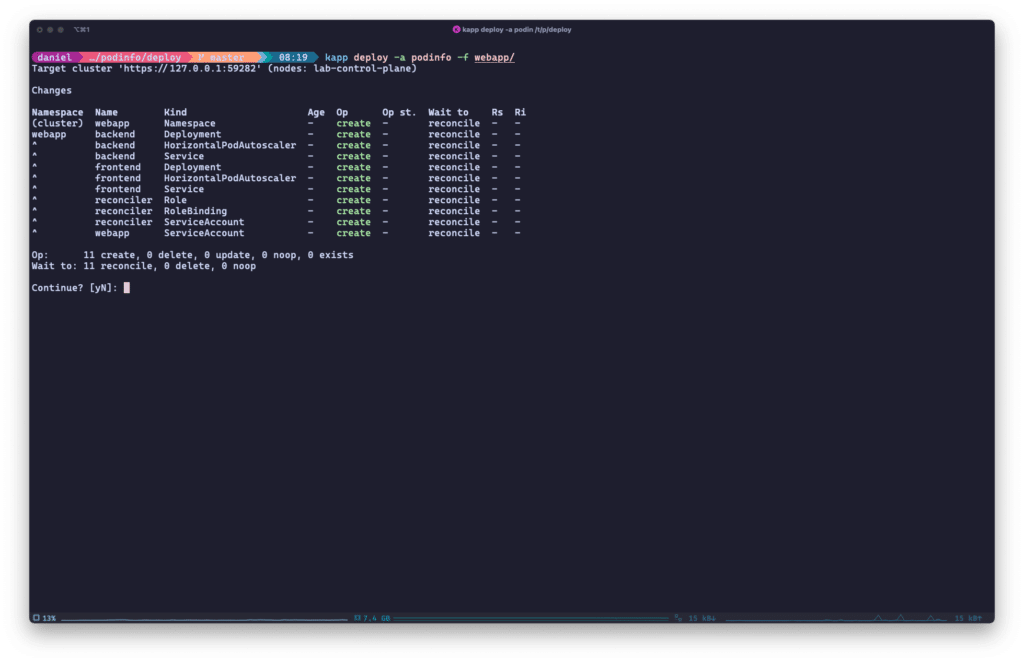
kapp listet alle anstehenden Aktionen auf, die der Benutzer vor dem Einsatz bestätigen muss.
Im Gegensatz zu Timoni musst Du nicht unbedingt selbst eine maßgeschneiderte Anwendungskonfiguration schreiben – kapp kann auf bestehenden Lösungen wie Kustomize, Helm oder ytt, einem weiteren Carvel-Tool zum Templaten und Patchen von YAML, aufbauen. Siehe das folgende Beispiel mit der podinfo Helmchart:
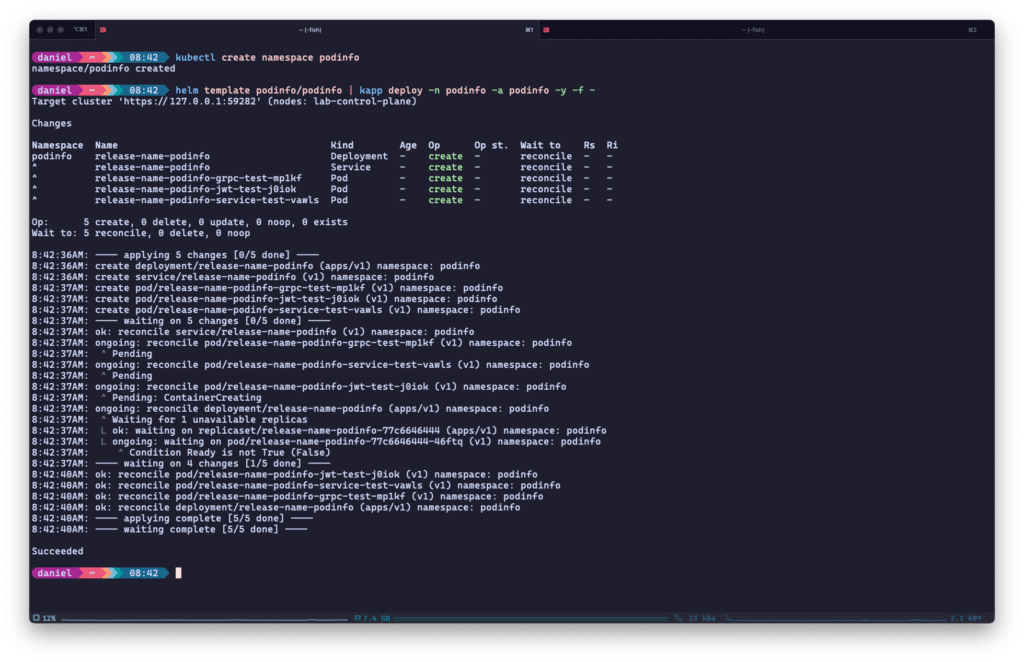
kapp kann die resultierenden Manifeste von vielen anderen Kubernetes-Deployment-Tools wie Helm verdauen und darauf reagieren.
Nach der Bereitstellung kann kapp Einblicke in Ihre Kubernetes-Bereitstellungen geben: Vom Reconciliation-Status über verknüpfte ServiceAccounts oder ConfigMaps bis hin zu den Labels Ihrer Anwendungen – kapp hat alles im Griff.
Wenn Du Dir mehr Gedanken über Day-2-Betrieb und Automatisierung machst, hat kapp ein weiteres Ass im Ärmel: kapp-controller. Kombiniere diese beiden Carvel-Tools und Du erhältst eine GitOps-fähige, vollständig automatisierte Lösung für Kubernetes Deployments. kapp-controller führt eine Reihe von CRDs ein, um Apps zu verwalten und/oder sie als Pakete, PackageRepositories und PackageInstallations zu verteilen. Diese CRDs können wiederum z.B. von Deiner GitOps-Lösung deployed werden.
Das Fazit
Diese Funktionen machen kapp zu einer soliden Wahl, wenn Du beim Vergleich von Kubernetes Deployment Tools nach einer oder mehreren der folgenden Stärken suchst:
- Korrektheit: kapp listet alle anstehenden Änderungen an Deinen Anwendungs-Deployments auf, sei es Erstellung, Löschung oder Patch, und bittet standardmäßig um eine Bestätigung.
kapp hält Dich außerdem während des gesamten Deployments auf dem Laufenden und zeigt den Status Deines Deployments jederzeit an.
- Einfache Einführung: Mit kapp musst Du keine bestehenden Deployment-Konfigurationen umschreiben, weder Manifeste noch Helmcharts oder Kustomize-Strukturen.
Füge kapp einfach zu Deiner Deployment-Pipeline hinzu und nutze den Mehrwert, den es bietet.
- GitOps-fähig: Mit kapp-controller in Kombination mit kapp kannst Du deklarative CRDs verwenden, um Deine Anwendungsbereitstellung zu verwalten.
Darüber hinaus hast Du die Möglichkeit, verschiedene Versionen von Bereitstellungen als Pakete zu verwalten.
Wir haben uns bisher bereits zwei Kubernetes Deployment Tools angesehen, aber Du weißt ja, was man sagt: „Aller guten Dinge sind drei!“
Werfen wir also einen Blick auf das letzte Tool für heute – Glasskube.
Glasskube – der Paketmanager der nächsten Generation für Kubernetes
Die nächste Generation von Paketmanager für Kubernetes zu lesen, weckt sicherlich einige Erwartungen – aber der steile Anstieg von Glasskube auf ~2400 GitHub-Sterne und die kürzliche Aufnahme des Startups in den Y Combinator-Inkubator können als Zeichen dafür gewertet werden, dass Glasskube tatsächlich der nächste (oder erste?) Paketmanager für Kubernetes sein könnte.
Glasskube ist vollständig quelloffen (wie Timoni und kapp), verfügt über eine integrierte Benutzeroberfläche und verspricht, sowohl unternehmenstauglich als auch in Gitops integrierbar zu sein. Das Projekt hostet auch eine öffentliche Registry getesteter und verifizierter Pakete, die jeder reviewen und in seinen Clustern verwenden kann.
Aber kommen wir nun zu den technischen Details. Das Herzstück von Glasskube ist seine CLI, die auch für das Bootstrapping der Glasskube-Komponenten im Cluster benötigt wird. Dabei handelt es sich um den Glasskube-eigenen Controller-Manager, der zwei Controller betreibt, sowie die Helm- und Source-Controller von Flux. Wenn Du bereits Flux innerhalb Deines Clusters einsetzt, kannst Du die Installation der Flux-Komponenten ganz überspringen.
Zusätzlich zu diesen Controllern wird Glasskube auch einige CRDs in Deinem Cluster installieren, die Pakete, Repositories und Paketinstallationen für Dich verwalten.
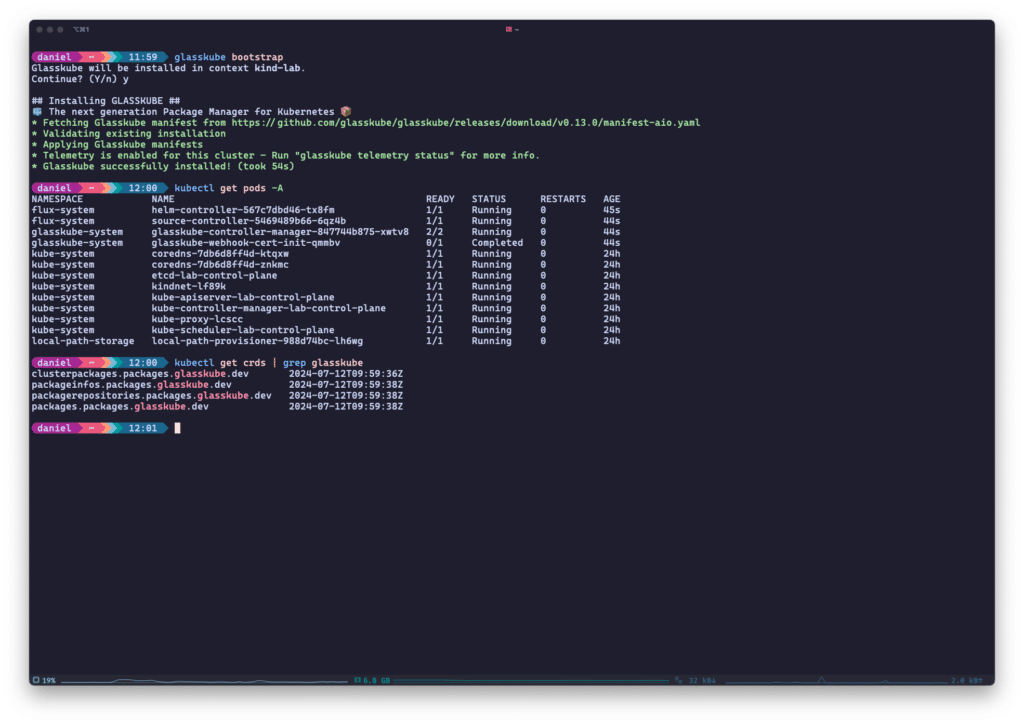
Glasskube installiert ein paar Controller und CRDs in Deinem Cluster, wenn Du es mit der CLI bootstrappst.
Die UI hingegen läuft nicht innerhalb des Clusters; sie wird lokal über die CLI gestartet und bietet eine sehr einfache Möglichkeit, Pakete in Deinem Cluster zu installieren.
Glasskube unterscheidet zwischen ClusterPackages, die in einem clusterweiten Kontext (z.B. Operatoren) installiert werden, und Packages, die in namespacegebundenen Kontexten installiert werden. Innerhalb Deines Clusters werden diese Paketinstallationen als CustomResources persistiert. Das Gleiche gilt für Registries, die Du über die CLI konfigurieren kannst, einschließlich Authentifizierung.
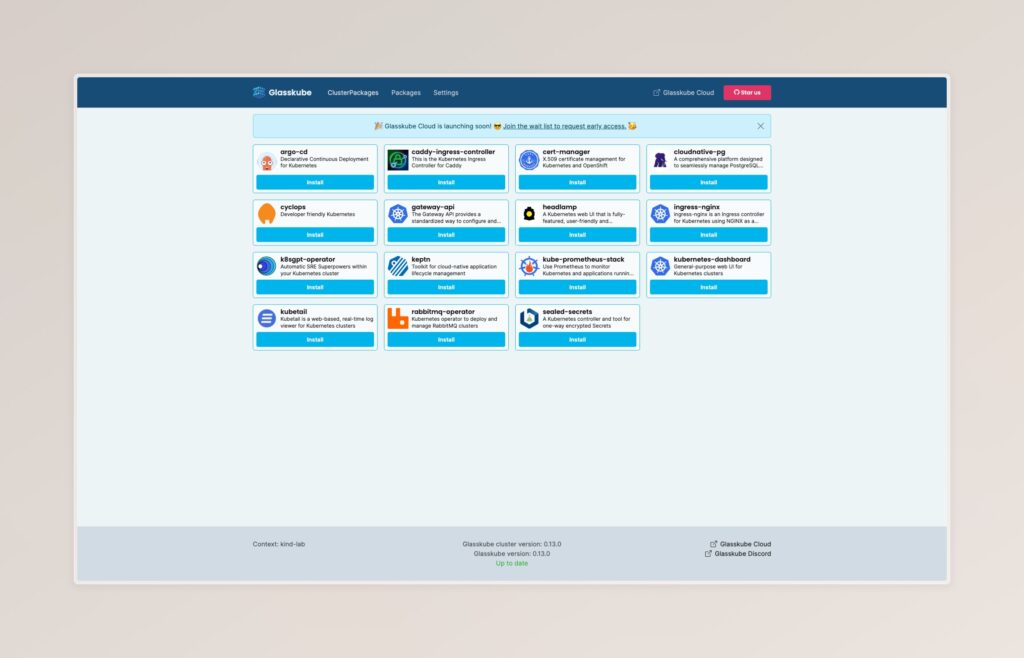
Die Web-UI von Glasskube wird mit der offiziellen Registry vorkonfiguriert installiert und bietet bereits viele (Cluster-)Packages zur Installation an.
Genau wie kapp baut Glasskube auf bestehenden Lösungen auf – Helm oder reine YAML-Manifeste – um Pakete in Kubernetes bereitzustellen. Ein Glasskube-Paket definiert konfigurierbare Werte, einschließlich Beschreibung, Einschränkungen usw., die dem Benutzer bei der Installation in der Benutzeroberfläche oder im Terminal angezeigt werden. Diese Wertedefinitionen unterstützen sowohl Werteliterale als auch Lookups, die von anderen Cluster-Ressourcen stammen.
Glasskube verarbeitet und validiert diese Werte, bevor sie in die zugrunde liegenden Helm-Werte oder YAML-Manifeste eingefügt werden.
Das Fazit
Mit diesen Informationen können wir wie bei den anderen Kubernetes Deployment Tools einige Schlüsselpunkte von Glasskube identifizieren:
- Benutzerfreundlichkeit: Mit seinem automatisierten Bootstrap-Verfahren, seiner clientseitigen Benutzeroberfläche und immer mehr Paketen, die sofort verfügbar sind, eignet sich Glasskube perfekt für die Erstellung von PoCs und das „Ausprobieren“ von Dingen.
- Dependencymanagement: Als Paketmanager verspricht Glasskube ein vollwertiges Dependencymanagement.
Dies ist bereits Realität, z.B. wird bei der Installation des Keptn-Pakets auch das cert-manager-Paket als Abhängigkeit installiert.
- GitOps-ready: wie kapp kann Glasskube dank seiner CRDs verwendet werden, um Anwendungen deklarativ bereitzustellen.
Im weiteren Entwicklungsprozess des Projekts würde ich mir wünschen, dass die UI weitere Funktionen für Multi-Tenancy und Benutzer-Governance enthält. Sollte dies jedoch nicht der Fall sein, wird es dank der zugrunde liegenden CRDs, die den Konfigurations- und Bereitstellungsstatus erfassen, trotzdem möglich sein, eigene maßgeschneiderte Benutzeroberflächen zu erstellen.
Quo Vadis, Kubernetes Deployments?
Helm und Kustomize sind Säulen und Standards des Kubernetes-Ökosystems. Eine neue Generation von Deployment-Tools steht jedoch in gewisser Weise auf den Schultern dieser Giganten und versucht, den Status Quo noch zu verbessern.
Nach dem Vergleich dieser drei Kubernetes Deployment Tools ist klar, dass Korrektheit, Verteilung und Automatisierung der Fokus von Timoni, kapp und Glasskube sind:
- Alle drei Lösungen haben einen Weg gefunden, Benutzereingaben zu validieren und/oder Deployment-Prozesse verständlicher zu machen.
- Alle drei Lösungen arbeiten an besseren Möglichkeiten der Verteilung und des Beziehens von Anwendungen.
Timoni mit seinen Modulen und Bundles, kapp (bzw. kapp-controller) mit seiner Package CRD und Glasskube mit seinen (Cluster-)Package CRDs.
- Alle drei Lösungen heben in ihren Dokumentationen ihre Fähigkeiten zur Integration mit GitOps-Praktiken hervor.
Automatisierung und deklarative Konfiguration von Infrastruktur- und Anwendungsimplementierungen sind zu einem De-facto-Standard in Kubernetes geworden, und die neue Generation von Kubernetes-Implementierungstools weiß das.
kapp und Glasskube bieten sehr klare Migrationspfade, wenn man von Helmcharts oder YAML-Manifesten kommt – baue einfach auf Deinen bestehenden Lösungen auf und erweitere oder refactore sie im Laufe der Zeit.
Timoni hingegen ist mit den anfänglichen Kosten und der Lernkurve von CUE verbunden, verspricht aber eine sehr hohe Performanz und wahrscheinlich die beste Eingabevalidierung der drei verglichenen Tools.
Egal, welchen Weg Du letztendlich einschlagen wirst, ich hoffe, dass dieser Artikel ein wenig Licht auf die Optionen wirft, die es heute gibt. Schaue Dir auf jeden Fall einige unserer anderen Blog-Beiträge zum Thema Kubernetes an und abonniere unseren Newsletter, um von nun an auf dem Laufenden zu bleiben!

von Daniel Bodky | Jun 14, 2024 | Kubernetes
Wir freuen uns, Dir heute unseren brandneuen NWS Kubernetes Playground präsentieren zu können! Die interaktive Plattform hilft Dir dabei, Neues über cloud-native Technologien zu lernen, Dein Wissen und Selbstvertrauen in der Arbeit mit Kubernetes auszubauen, und eine Reihe von NWS-Produkten auszuprobieren. Unser Kubernetes Playground bietet eine einmalige Lernumgebung, in der Du in einer vollständigen, kostenlosen Umgebung aufbauend auf NWS Kubernetes arbeitest. Jeder Playground wird durch Workshop-ähnliche Anweisungen begleitet, die Dich durch die inhaltlich eng gefassten Themen führen. So kannst Du Neues lernen, wann immer Du ein paar Minuten Zeit hast. Die meisten Abschnitte halten interaktive Aufgaben und Quizze für Dich bereit, um dein Wissen zu testen und zu vertiefen.

Vertiefe deine cloud-native Skills mit kurz gehaltenen Labs
Ab Heute Verfügbar
Zum Launch bieten wir Dir auf unserer Plattform drei Playgrounds an, die sich mit den Grundlagen rund um Kubernetes befassen:
- Arbeiten mit Pods: Dieser Playground wird Dir alles beibringen, was du über Pods wissen musst, von der Erstellung bis hin zum Troubleshooting. Du erlangst so erste Erfahrungen im Umgang mit Pods und wie sie in Kubernetesumgebungen funktionieren.
- Arbeiten mit Deployments: Lerne, Deployments zum Management und zur Skalierung deiner Kubernetesworkloads zu nutzen. Dieser Playground deckt die Grundlagen im Umgang mit Deployments auf Kubernetes ab.
- Kubernetes Sandbox: Experimentiere in dieser Umgebung komplett frei mit Kubernetes. Dieser Playground stellt spezifische Features und Eigenheiten von NWS Managed Kubernetes vor (z.B. Storageclasses), und lässt Dich frei mit Kubernetes experimentieren.
Um loszulegen, besuche playground.nws.netways.de und tauche in die Welt von Kubernetes ein. Egal, ob du unsere umfangreichen Tutorials aus unserem Blog praktisch nachvollziehen oder dich in der Kubernetes Sandbox umschauen möchtest, unsere Playgrounds bieten Dir eine praktische und authentische Lernumgebung!
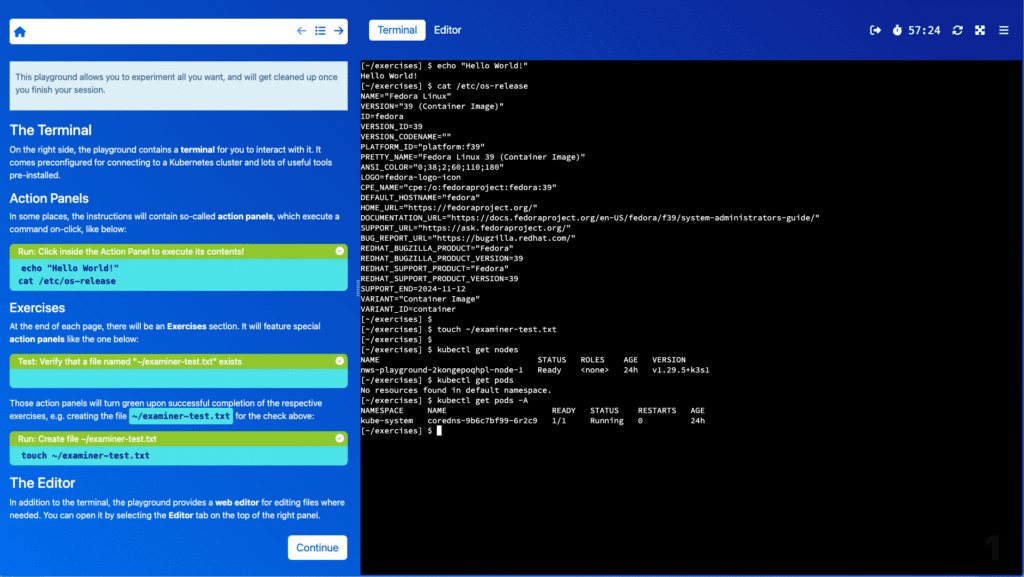
Interaktive Sessions bieten Lerninhalte, Wissensabfragen und interaktive Elemente, um dein Fachwissen zu verbessern
Wie es Weitergeht
Sei gespannt auf die Zukunft! Wir entwickeln kontinuierlich neue Playgrounds und kündigen sie bei Veröffentlichung in unserem Newsletter an. Melde dich an, um up-to-date zu bleiben und die neuesten Änderungen an den NWS Playgrounds mitzubekommen. Mit dem NWS Kubernetes Playground kannst Du nach und nach ein solides Verständnis für Kubernetes entwickeln und Deine Fähigkeiten weiterentwickeln. Für mehr Details und Updates, schaue regelmäßig in unserem Blog und auf playground.nws.netways.de vorbei!

von Daniel Bodky | Apr 30, 2024 | Software as a Service
Letzten Donnerstag haben wir die neueste Erweiterung unserer Managed Services herausgebracht – Prometheus. Als führende Opensource Monitoringlösung bietet es eine ganze Reihe an spannenden Features.
Lass uns einen Blick darauf werfen, was Prometheus ist, wie es dir bei der Überwachung deiner IT-Infrastruktur helfen kann, und wie du es in MyNWS startest.
Was ist Prometheus
Prometheus ist die führende Opensource Monitoringlösung, die es dir erlaubt, Metriken von einer großen Bandbreite an IT-Systemen zu sammeln, zu aggregieren, zu speichern und zu querien.
Hierfür besitzt Prometheus seine eigene Querysprache, PromQL, mit der auch Visualisierung und Alarmierung umgesetzt werden.
Als grundlegende Säule des Cloud-Native Ökosystems integriert Prometheus wunderbar mit Anwendungen wie Kubernetes, Docker, und Microservices allgemein. Zusätzlich ermöglicht es die Überwachung von Services wie Datenbanken oder Messagequeues.
Mit unserem Managed Prometheus kannst du diese Vielseitigkeit innerhalb von Minuten für dich nutzen, ohne dich mit Einrichtung, Konfiguration und Betrieb deiner Umgebung aufhalten zu müssen.
Probiere es direkt aus – der erste Monat ist kostenlos!
Wie funktioniert Prometheus
Prometheus sammelt Daten in einem maschinenlesbaren Format von Webendpoints der zu überwachenden Anwendungen, üblicherweise unter dem Pfad /metrics.
Bietet ein Service keinen solchen Endpoint an, gibt es im Ökosystem vermutlich bereits einen sog. Metrics Exporter, der die Daten lokal auf andere Weise abfrägt und selbst bereitstellt.
Die gesammelten Metriken werden von Prometheus selbst gespeichert, im Laufe der Zeit aggregiert, und nach einiger Zeit gelöscht. Mit PromQL kannst du diese Daten entweder in Prometheus Weboberfläche oder in Grafana visuell aufbereiten.
Nutze Managed Prometheus in MyNWS
Um Managed Prometheus in MyNWS nutzen zu können, musst du lediglich das Produkt aus der Liste auswählen, einen Namen und Plan wählen, und auf Create klicken. Innerhalb von Minuten läuft deine Managed Prometheus App dann auch schon – doch was bietet sie an Features?
Managed Prometheus in MyNWS bietet vom Start weg eine breite Palette an Features, unter Anderem:
- Webzugang zu Prometheus und Grafana – für schnelle Abfragen und ausführliche Visualisierungen
- User Access Management basierend auf MyNWS ID – hol‘ dein Team ins Boot
- Prebuilt Dashboards und Alarmierungen für Kubernetes – Visualisiere deine Daten ab Minute 1
- Custom Domain Support – konfiguriere deine eigene Domain einfach in MyNWS
- Remote Write möglich – aggregiere, sichere und visualisiere Daten von anderen Prometheus-Instanzen in MyNWS
Wenn das Alles für dich gut klingt, probiere Managed Prometheus in MyNWS auf jeden Fall einmal aus – der erste Monat ist kostenlos!
Hast du noch weitere Fragen oder brauchst Unterstützung auf den ersten Metern, melde dich gerne jederzeit bei unseren MyEngineers oder wirf einen Blick auf unsere Opensource Trainings, falls du gerade erst mit Prometheus loslegst.

von Daniel Bodky | Mrz 27, 2024 | Event
Vergangenen Sonntag fuhr ein Teil unseres Teams bis nach Ghent in Belgien, um am ConfigManagementCamp 2024 teilzunehmen.
Hierbei handelt es sich um eine kostenlose Konferenz, direkt im Anschluss an die FOSDEM, was Jahr für Jahr für ein großes Publikum aus Fans von Open Source, guten Gesprächen und neuen Ideen sorgt. Auch dieses Jahr war das nicht anders, und so wollen wir in diesem Artikel noch einmal auf das CfgMgmtCamp 2024 zurückblicken.
Die ollen Zuverlässigen
Configmanagement als Aufgabenbereich ist bereits seit Längerem eine Notwendigkeit im alltäglichen Betrieb von IT-Infrastruktur und Software. So ist es nur natürlich, dass es inzwischen eine Riege etablierter, „oller“ Lösungen gibt, z.B. Puppet, Terraform oder Ansible.
Es war schön zu sehen, dass die Projekte und ihre jeweiligen Ökosysteme weiterhin voller Leben sind: Egal ob event-driven Ansible oder neue ‚Hacks‘ im Umgang mit Puppet, es gab auf jeden Fall noch Neues zu lernen!

Ansible, Terraform und Konsorten sind weiterhin zuverlässige Wegbegleiter im Configmanagement
Terraform und sein brandneuer Fork OpenTofu, der im Januar seinen ersten stabilen Release feiern durfte, waren ebenfalls Thema einiger Talks.
Die Tatsache, dass OpenTofu innerhalb von fünf Monaten von Fork zu Stable Release gelangen konnte, zeigt gut, wie wichtig der Community das Projekt ist.
Es wird spannend zu sehen sein, wie sich die beiden Projekte weiter (auseinander) entwickeln.
Noch erwähnenswert ist, dass sowohl Puppet Labs als auch Ansible als Sponsoren am CfgMgmtCamp 2024 auftraten, sodass man sich direkt ‚an der Quelle‘ mit Maintainern und der Community austauschen konnte.
Neues Jahr, Neue Tools
Natürlich waren wir nicht nur vor Ort, um unser Wissen rund um existierende Tools zu vertiefen, wir wollten auch Neues kennenlernen!
Hierzu gab es so einige Möglichkeiten:
Pkl ist eine Konfigurationssprache, die intern bei Apple genutzt wird. Apple hat sich 3 Tage vor dem CfgMgmtCamp dazu entschlossen, diese zu opensourcen. Einen ersten Eindruck konnten wir beim weltweit ersten Talk zu Pkl erhalten:
Die Konfigurationssprache erlaubt es einem, typisierte und durchweg validierte Konfigurationen zu erstellen, die dann in Formate wie YAML oder JSON exportiert werden können. Genaueres findet man auf der Projektwebsite oder im GitHub-Repository des Projekts
Ein weiteres interessantes Projekt, das am CfgMgmtCamp 2024 vorgestellt wurde, ist winglang. Die zugrundeliegende Idee, eine Programmiersprache für Infrastruktur und Code zu haben, fand viel Anklang.
Winglang fokussiert sich dabei auf die Abstraktion der verschiedenen Bausteine „in er Cloud“, um das Definieren von Workloads und Infrastruktur zu erleichtern.
Uns gefiel vor allem der lokale Simulator, der die definierten Ressourcen und das Verhalten der Workloads in Echtzeit wiederspiegelt.
Die dritte Neuheit, die wir nicht unerwähnt lassen wollen, ist System Initiative, ein ‚collaborative power tool designed to remove the papercuts from DevOps work‘. Du kannst es Dir vorstellen wie DrawIO für Infrastructure, mit Multiplayer-Support: Es ist eine GUI mit einer Vielzahl an Cloud-Komponenten, mit denen Du deine Infrastruktur in den Wolken bauen kannst.
System Initiative gleicht im Hintergrund konstant die Korrektheit und den Zustand Deines Projekts mit der Cloud Deines Vertrauens ab.
Unsere Erkenntnisse vom CfgMgmtCamp 2024
Rückblickend konnten wir zwei grundsätzliche Erkenntnisse mit nach Nürnberg nehmen:
Niemand mag YAML, sogar im ‚YAMLCamp‘ – Ansätze wie CUElang, Pkl und winglang deuten mehr als offensichtlich darauf hin.
Ob Sprachen mit strikteren Regeln hinsichtlich Korrektheit der richtige Weg sind, um am Ende dann doch YAML zu generieren, wird sich noch zeigen müssen.
Ansible, Puppet und Terraform sind nachwievor relevant. Wir konnten auch dieses Jahr wieder Neuerungen, Weiterentwicklungen und lebhafte Diskussionen rund um die Tools und ihre jeweiligen Ökosysteme beobachten. Außerdem hat die Open Source Community im vergangenen Jahr eindrucksvoll gezeigt, dass sie die Dinge auch selbst in die Hand nehmen kann, falls nötig (Hallo, OpenTofu!).
Für uns besonders interessant waren einige der Talks rund um Terraform und Ansible, da wir diese rund um OpenStack ebenfalls nutzen: Sei es im Zusammenspiel von OpenStack mit Terraform oder dem Erzeugen dynamischer Inventare unserer Infrastruktur in der Cloud für Ansible.
Und solltest Du Dich noch nicht bereit fühle, direkt ins tiefe Wasser des Configmanagements zu springen, sind ja auch noch unsere MyEngineers bereit, Dir jederzeit zu helfen.
Recent Comments