
von Achim Ledermüller | Mai 19, 2021 | Tutorial
Du willst automatische Fedora CoresOS Updates für Dein Kubernetes? Und was haben Zincati und libostree damit zu tun? Hier bekommst Du schnell einen Überblick!
Als Betriebssystem vieler Kubernetes Cluster kommt Fedora CoreOS zum Einsatz. Dieses auf Container spezialisierte Betriebssystem punktet vor allem mit einfachen, automatischen Updates. Anders als gewohnt wird hier nicht Paket für Paket aktualisiert. Fedora CoreOS erstellt zuerst ein neues, aktualisiertes Image des Systems und finalisiert das Update mit einem Reboot. Für einen reibungslosen Ablauf sorgt rpm-ostree in Kombination mit Cincinnati und Zincati.
Bevor wir einen genaueren Blick auf die Komponenten werfen, klären wir zuerst wie Du automatische Updates für Dein NWS Kubernetes Cluster aktivieren kannst.
Wie aktivierst Du automatische Updates für Dein NWS Kubernetes Cluster?
Im NWS Portal kannst Du einfach zwischen verschiedenen Update-Mechanismen wählen. Klicke dazu auf “Update Fedora CoreOS” im Kontextmenü Deines Kubernetes Clusters und wähle zwischen immediate, periodic und lock-based.
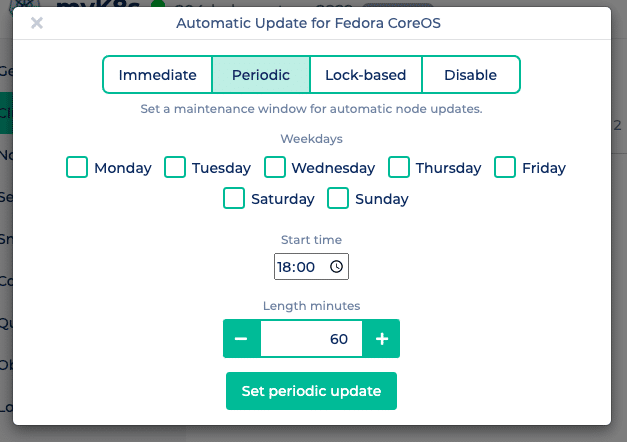 Immediate spielt Updates sofort auf all Deinen Kubernetes Knoten ein und finalisiert das Update mit einem Reboot.
Immediate spielt Updates sofort auf all Deinen Kubernetes Knoten ein und finalisiert das Update mit einem Reboot.
Periodic aktualisiert Deine Nodes nur während eines frei wählbaren Wartungsfensters. Neben der Wochentage kannst Du den Startzeitpunkt und die Länge des Wartungsfensters festlegen.
Lock-based verwendet zur Koordinierung der Updates das FleetLock-Protokoll. Hier wird über einen Lockmanager das Finalisieren der Updates koordiniert. Damit wird sichergestellt, dass Nodes nicht gleichzeitig Updates finalisieren und rebooten. Zudem wird bei Problemen der Update Prozess gestoppt und weitere Nodes führen kein Update durch.
Disable deaktiviert automatische Updates.
So weit, so gut! Aber was ist jetzt rpm-ostree und Zincati?
Updates mal anders!
Durch die Einführung Container-basierter Anwendungen konnte auch eine Vereinheitlichung und Vereinfachung der darunter liegenden Betriebssysteme stattfinden. Zuverlässige, automatische Updates und die Steuerung dieser – durch den Betreiber der Anwendung – verringern zusätzlich den Aufwand für Wartung und Koordination.
rpm-ostree erstellt die Images
rpm-ostree ist ein Hybrid aus libostree und libdnf und somit eine Mischung aus Image- und Paketsystem. libostree bezeichnet sich selbst als git for operating system binaries, wobei jeder Commit einen bootfähigen Dateibaum enthält. Eine neue Version von Fedora CoreOS entspricht somit einem rpm-ostree Commit, gepflegt und bereitgestellt durch das CoreOS-Team. libdnf bietet die bekannten Features zur Paketverwaltung, wodurch die von libostree zur Verfügung gestellte Basis durch die Benutzer erweiterbar ist.
Taints und Tolerations
Nodes, auf denen keine Container gestartet werden können bzw. nicht erreichbar sind, bekommen von Kubernetes einen sogenannten Taint (z.B. not-ready oder unreachable). Als Gegenstück werden Pods auf solchen Nodes mit einer Toleration versehen. Das passiert auch bei einem Fedora CoreOS Update. Pods werden bei einem Reboot automatisch mit
tolerationSeconds=300 markiert, wodurch nach 5 Minuten Deine Pods auf anderen Nodes neu gestartet werden. Mehr zu Taints und Tolerations findest Du natürlich in der
Kubernetes Dokumentation.
Cincinnati und Zincati verteilen die Updates
Zum Verteilen der rpm-ostree Commits kommt Cincinnati und Zincati zum Einsatz. Letzteres ist ein Client, der regelmäßig den Fedora CoreOS Cincinnati Server nach Updates fragt. Sobald ein passendes Update vorliegt, bereitet rpm-ostree einen neuen, bootfähigen Dateibaum vor. Je nach gewählter Strategie finalisiert Zincati das Update durch einen Reboot des Nodes.
Was sind die Vorteile?
Einfacher Rollback
Mit libostree ist es einfach, den alten Zustand wieder herzustellen. Hierfür muss man nur in den vorherigen rpm-ostree Commit booten. Dieser ist auch als Eintrag im Grub Bootloader-Menü zu finden.
Geringer Aufwand
Fedora CoreOS kann sich ohne manuelles Eingreifen aktualisieren. In Kombination mit Kubernetes werden auch die Anwendungen automatisch auf die aktuell verfügbaren Nodes verschoben.
Flexible Konfiguration
Zincati bietet eine einfache und flexible Konfiguration, mit der hoffentlich jeder Anwender eine passende Update Strategie findet.
Bessere Qualität
Durch den schlanken Image-basierten Ansatz kann jede Version als Ganzes leichter und genauer getestet werden.
Ob sich dieser Hybrid aus Image- und Paket-basiertem Betriebssystem durchsetzt, wird die Zukunft zeigen. Fedora CoreOS – als Basis für unser NMS Managed Kubernetes – vereinfacht den Update-Prozess erheblich und ermöglicht unseren Kunden trotzdem eine einfache Steuerung.

von Achim Ledermüller | Okt 14, 2020 | Kubernetes, Tutorial
Du willst wissen wie Du in Deinem Kubernetes Cluster an die IP-Adressen Deiner Clients kommst? In fünf Minuten hast Du den Überblick!
Vom HTTP-Client zur Anwendung
Im Tutorial zum nginx-Ingress-Controller zeigen wir wie man eine Anwendung öffentlich erreichbar macht. Im Fall der NETWAYS Cloud bedient sich dein Kubernetes Cluster an einem Openstack-Loadbalancer, welcher die Client-Anfragen an einen nginx-Ingress-Controller im Kubernetes Cluster weitersendet. Dieser verteilt dann alle Anfragen an die entsprechenden Pods. Bei all dem Herumschieben und Weiterleiten der Anfragen gehen ohne weitere Konfiguration die Verbindungsdetails der Clients verloren. Da das Problem nicht erst seit Kubernetes auftritt, wird auf die alt bewährten Lösungen X-Forwarded-For oder Proxy-Protocol zurückgegriffen. Um im Buzzword-Bingo zwischen Service, Loadbalancer, Ingress, Proxy, Client und Anwendung nicht die Übersicht zu verlieren, kannst Du Dir im folgenden Beispiel den Weg einer HTTP-Anfrage vom Client bis zur Anwendung durch die Komponenten eines Kubernetes Clusters ansehen. 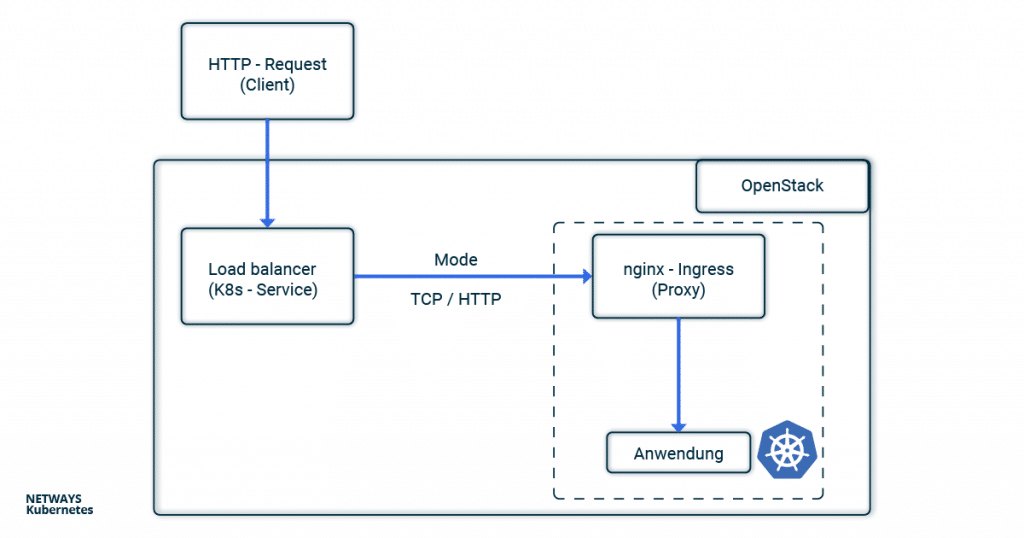
Client IP-Adressen mit X-Forwarded-For
Verwendest Du HTTP, kann die Client IP-Adresse im X-Forwarded-For (XFF) gespeichert und weiter transportiert werden. XFF ist ein Eintrag im HTTP-Header und wird von den meisten Proxy-Servern unterstützt. Im Beispiel setzt der Loadbalancer dazu die Client-IP-Adresse in den XFF-Eintrag und schickt die Anfrage weiter. Alle weiteren Proxy-Server und die Anwendungen können dadurch im XFF-Eintrag erkennen, von welcher Adresse die Anfrage ursprünglich gesendet wurde. In Kubernetes konfiguriert man den Loadbalancer über Annotations im Service Objekt. Setzt man dort loadbalancer.openstack.org/x-forwarded-for: true wird der Loadbalancer entsprechend konfiguriert. Wichtig ist jetzt natürlich auch noch, dass der nächste Proxy den X-Forwarded-For Header nicht wieder überschreibt. Im Fall eines nginx kann man dazu die Option use-forwarded-headers in dessen ConfigMap setzen.
---
# Service
kind: Service
apiVersion: v1
metadata:
name: loadbalanced-service
annotations:
loadbalancer.openstack.org/x-forwarded-for: "true"
spec:
selector:
app: echoserver
type: LoadBalancer
ports:
- port: 80
targetPort: 8080
protocol: TCP
---
# ConfigMap
apiVersion: v1
kind: ConfigMap
metadata:
name: nginx
data:
use-forwarded-headers: "true"
Da der HTTP-Header verwendet wird, ist es nicht möglich HTTPS-Verbindungen mit der Client-IP-Adresse anzureichern. Hier muss man entweder das TLS/SSL-Protokoll am Loadbalancer terminieren oder auf das Proxy-Protocol zurückgreifen.
Client-Informationen mit Proxy-Protocol
Verwendet man X-Forwarded-For ist man offensichtlich auf HTTP beschränkt. Um auch HTTPS und anderen Anwendungen hinter Loadbalancern und Proxys den Zugriff auf die Verbindungsoption der Clients zu ermöglichen, wurde das sogenannte Proxy-Protocol erfunden. Technisch wird dazu vom Loadbalancer ein kleiner Header mit den Verbindungsinformationen des Clients hinzugefügt. Der nächste Hop (hier nginx) muss natürlich ebenfalls das Protokoll verstehen und entsprechend behandeln. Neben klassischen Proxys unterstützten auch andere Anwendungen wie MariaDB oder postfix das Proxy-Protocol. Um das Proxy-Protocol zu aktivieren, musst Du das Service Objekt mit der Annotation loadbalancer.openstack.org/proxy-protocol versehen. Für den annehmenden Proxy muss das Protocol ebenfalls aktiviert werden.
---
# Service Loadbalancer
kind: Service
apiVersion: v1
metadata:
name: loadbalanced-service
annotations:
loadbalancer.openstack.org/proxy-protocol: "true"
spec:
selector:
app: echoserver
type: LoadBalancer
ports:
- port: 80
targetPort: 8080
protocol: TCP
---
# NGINX ConfigMap
apiVersion: v1
kind: ConfigMap
metadata:
name: nginx
data:
use-proxy-protocol: "true"
In den meisten Fällen wirst Du aber auf das Helm-Chart des nginx-Ingress-Controller zurückgreifen. Dort ist eine entsprechende Konfiguration sogar noch einfacher.
nginx-Ingress-Controller und Helm
Benutzt man Helm, um den nginx-ingress-controller zu installieren, ist die Konfiguration sehr übersichtlich. Das Proxy-Protocol wird über die eine Helm-Values-Datei sowohl für den nginx als auch für den Loadbalancer aktiviert: nginx-ingress.values:
---
controller:
config:
use-proxy-protocol: "true"
service:
annotations:
loadbalancer.openstack.org/proxy-protocol: true
type: LoadBalancer
$ helm install my-ingress stable/nginx-ingress -f nginx-ingress.values
Ob alles so funktioniert wie erwartet, kannst Du am einfachsten mit Hilfe des Google Echoserver testen. Dabei handelt sich um eine kleine Anwendung, die den HTTP-Request einfach an den Client zurück gibt. Wie im Tutorial zum nginx-Ingress-Controller beschrieben, benötigen wir dazu ein Deployment mit Service und Ingress. Ersteres startet den Echoserver, der Service macht diesen im Cluster erreichbar und der Ingress konfiguriert den nginx so, dass die Requests an das Deployment weitergeleitet werden.
---
# Deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: echoserver
spec:
selector:
matchLabels:
app: echoserver
replicas: 1
template:
metadata:
labels:
app: echoserver
spec:
containers:
- name: echoserver
image: gcr.io/google-containers/echoserver:1.8
ports:
- containerPort: 8080
---
# Service
apiVersion: v1
kind: Service
metadata:
name: echoserver-svc
spec:
ports:
- port: 80
targetPort: 8080
protocol: TCP
name: http
selector:
app: echoserver
---
# Ingress
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
name: echoserver-ingress
spec:
rules:
- host: echoserver.nws.netways.de
http:
paths:
- backend:
serviceName: echoserver-svc
servicePort: 80
Zum Testen fakest Du am besten noch deine /etc/hosts damit echoserver.nws.netways.de auf die öffentlichen IP-Adresse deines nginx-Ingress-Controller deutet. curl echoserver.nws.netways.de zeigt dir dann alles an, was der Echoserver von Deinem Client weiß, inklusive der IP-Adresse im X-Forwarded-For Header.
Fazit
Im Kubernetes Cluster ist das Proxy-Protocol für die meisten Anwendungsfälle wohl die bessere Wahl. Die bekannten Ingress-Controller unterstützen das Proxy-Protocol und TLS/SSL-Verbindungen können im K8s-Cluster konfiguriert und terminiert werden. Welche Informationen bei Deiner Anwendung ankommen, findest Du am schnellsten mit Googles Echoserver raus.

von Achim Ledermüller | Aug 19, 2020 | Kubernetes, Tutorial
Die wichtigsten Bausteine zum Starten deiner Anwendung kennst du bereits aus unserer Tutorial-Serie. Für den Betrieb fehlen dir noch Metriken und Logs deiner Anwendungen? Nach diesem Blogpost kannst du letzteres abhaken.
Logging mit Loki und Grafana in Kubernetes – ein Überblick
Zum Sammeln und Verwalten deiner Logs bieten sich auch für Kubernetes eine der wohl bekanntesten, schwergewichtigen Lösungen an. Diese bestehen in der Regel aus Logstash oder Fluentd zum Sammeln, gepaart mit Elasticsearch zum Speichern und Kibana bzw. Graylog zur Visualisierung deiner Logs. Neben dieser klassischen Kombination gibt es seit wenigen Jahren mit Loki und Grafana einen neuen, leichtgewichtigeren Stack! Die grundlegende Architektur unterscheidet sich kaum zu den bekannten Setups. Promtail sammelt auf jedem Kubernetes Node die Logs aller Container und sendet diese an eine zentrale Loki-Instanz. Diese aggregiert alle Logs und schreibt diese in ein Storage-Backend. Zur Visualisierung wird Grafana verwendet, welches sich die Logs direkt von der Loki-Instanz holt. 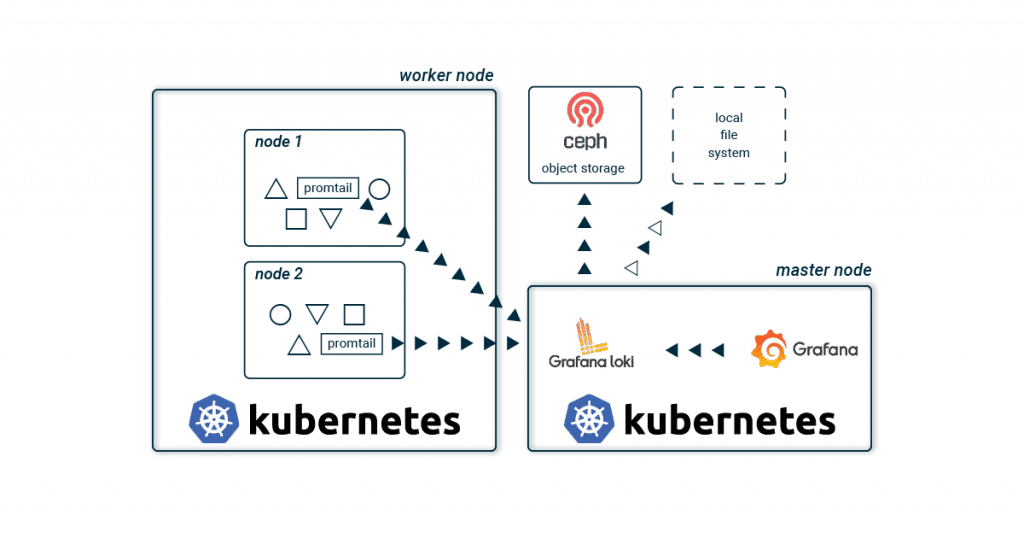 Der größte Unterschied zu den bekannten Stacks liegt wohl im Verzicht auf Elasticsearch. Dies spart Ressourcen und Aufwand, da somit auch kein dreifach replizierter Volltext-Index gespeichert und administriert werden muss. Und gerade wenn man beginnt, seine Anwendung aufzubauen, hört sich ein schlanker und einfacher Stack vielsprechend an. Wächst die Anwendungslandschaft, werden einzelne Komponenten von Loki in die Breite skaliert, um die Last auf mehrere Schultern zu verteilen.
Der größte Unterschied zu den bekannten Stacks liegt wohl im Verzicht auf Elasticsearch. Dies spart Ressourcen und Aufwand, da somit auch kein dreifach replizierter Volltext-Index gespeichert und administriert werden muss. Und gerade wenn man beginnt, seine Anwendung aufzubauen, hört sich ein schlanker und einfacher Stack vielsprechend an. Wächst die Anwendungslandschaft, werden einzelne Komponenten von Loki in die Breite skaliert, um die Last auf mehrere Schultern zu verteilen.
Kein Volltextindex? Wie funktioniert das?
Zur schnellen Suche verzichtet Loki natürlich nicht auf einen Index, aber es werden nur noch Metadaten (ähnlich wie bei Prometheus) indexiert. Der Aufwand, den Index zu betreiben, wird dadurch sehr verkleinert. Für dein Kubernetes-Cluster werden somit hauptsächlich Labels im Index gespeichert und deine Logs werden automatisch anhand derselben Metadaten organisiert wie auch deine Anwendungen in deinem Kubernetes-Cluster. Anhand eines Zeitfensters und den Labels findet Loki schnell und einfach deine gesuchten Logs. Zum Speichern des Index kann aus verschiedenen Datenbanken gewählt werden. Neben den beiden Cloud-Datenbanken BigTable und DynamoDB kann Loki seinen Index auch lokal in Cassandra oder BoltDB ablegen. Letztere unterstützt keine Replikation und ist vor allem für Entwicklungsumgebungen geeignet. Loki bietet mit boltdb-shipper eine weitere Datenbank an, welche aktuell noch in Entwicklung ist. Diese soll vor allem Abhängigkeiten zu einer replizierten Datenbank entfernen und regelmäßig Snapshots des Index im Chunk-Storage speichern (siehe unten). Ein kleines Beispiel
Ein pod produziert mit stdout und stderr zwei Log-Streams. Diese Log-Streams werden in sogenannte Chunks zerlegt und komprimiert, sobald eine gewisse Größe erreicht wurde oder ein Zeitfenster abgelaufen ist. Ein Chunk enthält somit komprimierte Logs eines Streams und wird auf eine maximale Größe und Zeiteinheit beschränkt. Diese komprimierten Datensätze werden dann im Chunk-Storage gespeichert.
Label vs. Stream
Eine Kombination aus exakt gleichen Labels (inkl. deren Werte) definiert einen Stream. Ändert man ein Label oder dessen Wert, entsteht ein neuer Stream. Die Logs aus stdout eines nginx-Pods befinden sich z.B. in einem Stream mit den Labels: pod-template-hash=bcf574bc8, app=nginx und stream=stdout.
Im Index von Loki werden diese Chunks mit den Labels des Streams und einem Zeitfenster verknüpft. Bei einer Suche muss im Index somit nur nach Labels und Zeitfenster gefiltert werden. Entspricht eine dieser Verknüpfungen den Suchkriterien, wird der Chunk aus dem Storage geladen und enthaltene Logs werden entsprechend der Suchanfrage gefiltert.
Chunk Storage
Im Chunk Storage werden die komprimierten und zerstückelten Log-Streams gespeichert. Wie beim Index kann auch hier zwischen verschiedenen Storage-Backends gewählt werden. Aufgrund der Größe der Chunks wird ein Object Store wie GCS, S3, Swift oder unser Ceph Object Store empfohlen. Die Replikation ist damit automatisch mit inbegriffen und die Chunks werden anhand eines Ablaufdatums auch selbständig vom Storage entfernt. In kleineren Projekten oder Entwicklungsumgebungen kann man aber natürlich auch mit einem lokalen Dateisystem beginnen.
Visualisierung mit Grafana
Zur Darstellung wird Grafana verwendet. Vorkonfigurierte Dashboards können leicht importiert werden. Als Query Language wird LogQL verwendet. Diese Eigenkreation von Grafana Labs lehnt sich stark an PromQL von Prometheus an und ist genauso schnell gelernt. Eine Abfrage besteht hierbei aus zwei Teilen: Zuerst filtert man mithilfe von Labels und dem Log Stream Selector nach den entsprechenden Chunks. Mit = macht man hier immer einen exakten Vergleich und =~ erlaubt die Verwendungen von Regex. Wie üblich wird mit ! die Selektion negiert. Nachdem man seine Suche auf bestimmte Chunks eingeschränkt hat, kann man diese mit einer Search Expression erweitern. Auch hier kann man mit verschiedenen Operatoren wie |= und |~ das Ergebnis weiter einschränken. Ein paar Beispiele zeigen wohl am schnellsten die Möglichkeiten:
Log Stream Selector:
{app = "nginx"}
{app != "nginx"}
{app =~ "ngin.*"}
{app !~ "nginx$"}
{app = "nginx", stream != "stdout"}
Search Expression:
{app = "nginx"} |= "192.168.0.1"
{app = "nginx"} != "192.168.0.1"
{app = "nginx"} |~ "192.*"
{app = "nginx"} !~ "192$"
Weitere Möglichkeiten wie Aggregationen werden ausführlich in der offiziellen Dokumentation von LogQL erklärt. Nach dieser kurzen Einführung in die Architektur und Funktionsweise von Grafana Loki legen wir natürlich gleich mit der Installation los. Viele weitere Informationen und Möglichkeiten zu Grafana Loki gibt es natürlich in der offiziellen Dokumentation.
Get it running!
Du willst Loki einfach ausprobieren?
Mit dem NWS Managed Kubernetes Cluster kannst du auf die Details verzichten! Mit einem Klick startest du deinen Loki Stack und hast dein Kubernetes Cluster immer voll im Blick!
Wie üblich mit Kubernetes ist ein laufendes Beispiel schneller deployed als die Erklärung gelesen. Mithilfe von Helm und einigen wenigen Variablen ist dein schlanker Logging Stack schnell installiert. Zuerst initialisieren wir zwei Helm-Repositories. Neben Grafana fügen wir auch noch das offizielle Helm stable Charts-Repository hinzu. Nach zwei kurzen helm repo add Befehlen haben wir Zugang zu den benötigten Loki und Grafana Charts.
Helm installieren
brew install helm
apt install helm
choco install kubernetes-helm
Dir fehlen die passenden Quellen? Auf helm.sh findest du eine kurze Anleitung für dein Betriebssystem.
helm repo add loki https://grafana.github.io/loki/charts
helm repo add stable https://kubernetes-charts.storage.googleapis.com/
Loki und Grafana installieren
Für deinen ersten Loki-Stack benötigst du keine weitere Konfiguration. Die Default-Werte passen sehr gut und helm install erledigt den Rest. Vor der Installation von Grafana setzen wir zuerst noch dessen Konfiguration mithilfe der bekannten Helm-Values-Dateien. Speichere diese mit dem Namen grafana.values ab. Neben dem Passwort für den Administrator wird auch das eben installierte Loki als Datenquelle gesetzt. Zur Visualisierung importieren wir gleich noch ein Dashboard und die dafür benötigten Plugins. Somit installiert du gleich ein für Loki konfiguriertes Grafana und kannst direkt nach dem Deploy loslegen.
grafana.values:
---
adminPassword: supersecret
datasources:
datasources.yaml:
apiVersion: 1
datasources:
- name: Loki
type: loki
url: http://loki-headless:3100
jsonData:
maxLines: 1000
plugins:
- grafana-piechart-panel
dashboardProviders:
dashboardproviders.yaml:
apiVersion: 1
providers:
- name: default
orgId: 1
folder:
type: file
disableDeletion: true
editable: false
options:
path: /var/lib/grafana/dashboards/default
dashboards:
default:
Logging:
gnetId: 12611
revison: 1
datasource: Loki
Die eigentliche Installation erfolgt mithilfe von helm install. Der erste Parameter ist ein frei wählbarer Name. Mit dessen Hilfe kannst du dir auch schnell einen Überblick verschaffen:
helm install loki loki/loki-stack
helm install loki-grafana stable/grafana -f grafana.values
kubectl get all -n kube-system -l release=loki
Nach dem Deployment kannst du dich als admin mit dem Passwort supersecret einloggen. Damit du direkt auf das Grafana Webinterface zugreifen kannst, fehlt dir noch noch ein port-forward:
kubectl --namespace kube-system port-forward service/loki-grafana 3001:80
Die Logs deiner laufenden Pods sollten sofort im Grafana sichtbar sein. Probier doch die Queries unter Explore aus und erkunde das Dashboard!
Logging mit Loki und Grafana in Kubernetes – das Fazit
Grafana Labs bietet mit Loki einen neuen Ansatz für ein zentrales Logmanagement. Durch die Verwendung von kostengünstigen und leicht verfügbaren Object Stores wird eine aufwändige Administration eines Elasticsearch-Clusters überflüssig. Das einfache und schnelle Deployment ist auch ideal für Entwicklungsumgebungen geeignet. Zwar bieten die beiden Alternativen Kibana und Graylog ein mächtiges Featureset, aber für manche Administratoren ist Loki mit seinem schlanken und einfachen Stack vielleicht verlockender.

von Achim Ledermüller | Jun 24, 2020 | Kubernetes, Tutorial
Du willst ein persistentes Volume in Kubernetes erstellen? Hier erfährst du wie das mit Openstack Cinder im NWS Managed Kubernetes funktioniert. Pods und Container sind per Definition mehr oder weniger flüchtige Komponenten in einem Kubernetes Cluster und werden je nach Notwendigkeit erstellt und zerstört. Viele Anwendungen wie Datenbanken können aber ohne langlebigen Storage nur selten sinnvoll betrieben werden. Mit dem Industriestandard Container Storage Interface (CSI) bietet Kubernetes eine einheitliche Integration für verschiedene Storage Backends zur Einbindung persistenter Volumes. Für unsere Managed Kubernetes Lösung verwenden wir die Openstack Komponente Cinder um persistente Volumes für Pods zur Verfügung zu stellen. Der CSI Cinder Controller ist für NWS Kubernetes ab Version 1.18.2 bereits aktiv und Du kannst mit nur einigen wenigen K8s Objekten persistente Volumes nutzen.
Persistente Volumes mit CSI Cinder Controller erstellen
Bevor Du ein Volume anlegen kannst, muss eine StorageClass mit Cinder als provisioner erstellt werden. Wie gewohnt werden die K8s-Objekte im YAML-Format und kubectl apply an dein Cluster gesendet:
storageclass.yaml:
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: cinderstorage
provisioner: cinder.csi.openstack.org
allowVolumeExpansion: true
Mit get und describe kannst Du überprüfen, ob das Anlegen funktioniert hat:
kubectl apply -f storageclass.yaml
kubectl get storageclass
kubectl describe storageclass cinderstorage
Auf Basis dieser Storage Klasse kannst Du nun beliebig viele Volumes erstellen.
Persistent Volume (PV) und Persistent Volume Claim (PVC)
Ein neues Volume kannst Du mit Hilfe eines peristentVolumeClaim erstellen. Der PVC beansprucht eine Ressource persistentVolume für Dich. Steht keine passende PV Ressource bereit, wird diese dynamisch durch den CSI Cinder Controller erstellt. PVC und PV werden aneinander gebunden und stehen exklusiv für Dich bereit. Ohne weitere Konfiguration wird ein dynamisch erstelltes PV mit dem Löschen des dazugehörigen PVC sofort gelöscht. Dieses Verhalten kann man in der oben definierten StorageClass mit Hilfe der reclaimPolicy überschreiben. pvc.yaml:
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: nginx-documentroot
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
storageClassName: cinderstorage
Neben dem Namen werden im PVC-Objekt weitere Eigenschaften wie Größe und accessMode definiert. Nachdem Du das PVC mit kubectl apply im Cluster angelegt hast, wird im Hintergrund ein neues Volume im Storage Backend erstellt. Im Falle unseres NETWAYS Managed Kubernetes erstellt Cinder ein Volume als RBD im Ceph Cluster. Im nächsten Schritt wird Dein neues Volume in das document root eines Nginx Pods gemountet.
kubectl describe pvc nginx-documentroot
Pods und persistente Volumes
Für gewöhnlich werden Volumes im Kontext eines Pods definiert und haben somit auch den gleichen Lebenszyklus wie diese. Willst Du aber ein Volume verwenden, das unabhängig vom Pod und Container ist, kannst Du den eben erstellten PVC im volumes Bereich referenzieren und dann im Container unter volumeMounts einbinden. Im Beispiel wird das document root eines Nginx ersetzt.
deployment.yaml:
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
labels:
app: nginx
spec:
selector:
matchLabels:
app: nginx
strategy:
type: Recreate
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx
name: nginx
ports:
- containerPort: 80
protocol: TCP
volumeMounts:
- mountPath: /usr/share/nginx/html
name: documentroot
volumes:
- name: documentroot
persistentVolumeClaim:
claimName: nginx-documentroot
readOnly: false
service.yaml:
---
apiVersion: v1
kind: Service
metadata:
name: nginx-svc
spec:
ports:
- port: 80
targetPort: 80
protocol: TCP
name: http
selector:
app: nginx
Kubernetes und der CSI Cinder Controller sorgen natürlich dafür, dass Dein neues Volume und die dazugehörigen Pods immer am gleichen Worker Node gestartet werden. Mit kubectl kannst Du auch schnell die index.html anpassen und den K8s Proxy starten und schon kannst Du auf Deine neue index.html im persistenten Volume zugreifen:
kubectl exec -it deployment/nginx — bash -c ‘echo “CSI FTW” > /usr/share/nginx/html/index.html’
kubectl port-forward service/nginx-svc 8080:80
Fazit
Mit dem CSI Cinder Contoller kannst Du schnell und einfach persistente Volumes anlegen und verwalten. Weitere Features zum Erstellen von Snapshots oder dem Vergrößern der Volumes sind bereits enthalten. Und auch Möglichkeiten wie z.B. Multinode Attachment sind bereits in Planung. Deinem Datenbankcluster im Kubernetes steht also nichts mehr im Weg und auch das nächste spannende Thema in unsere Kubernetes Blogserie steht damit wohl fest!

von Achim Ledermüller | Mai 20, 2020 | Kubernetes, Tutorial
Mit den ersten Schritten mit Kubernetes weißt Du bereits, wie Du Anwendungen in Deinem Kubernetes Cluster startest. Nun exponieren wir Deine Anwendung online. Wie das Ganze funktioniert und wie Du mit einem Kubernetes Nginx Ingress Controller am besten selbst direkt loslegen kannst, erläutere ich Dir im Folgenden an einem Beispiel. Um in einem Kubernetes Cluster Anwendungen von außen erreichbar zu machen, kann man einen Service vom Typ Loadbalancer verwenden. In der NETWAYS Cloud starten wir hier im Hintergrund ein Openstack Octavia LB mit öffentlicher IP und leiten den eingehenden Traffic an die Pods weiter (Bingo). Somit benötigen wir für jede Anwendung einen eigenen Loadbalancer mit öffentlicher IP. Um in einem Fall wie diesem etwas ressourcen- und somit kosteneffizienter arbeiten zu können, hat man vor Langem named-based virtual hosts und server name indication (sni) erfunden. Der altbekannte NGINX-Webserver unterstützt beides und als Kubernetes Ingress Controller kann dieser, mit nur einer öffentlichen IP-Adresse, all unsere http/s-Anwendungen schnell und einfach erreichbar machen. Die Installation und die Aktualisierung des Ningx Ingress Controllers ist dank eines Helm Charts sehr vereinfacht. Mit K8s Ingress Objekten konfiguriert man die Zuordnung von vHosts, URI-Pfaden und TLS-Zertifikaten zu K8s Services und somit zu unseren Anwendungen. Damit die Buzzwords Dir nicht den Blick aufs Wesentliche verhindern, hier ein kleiner Überblick, wie die HTTP-Anfragen an unsere Anwendungen weitergeleitet werden: 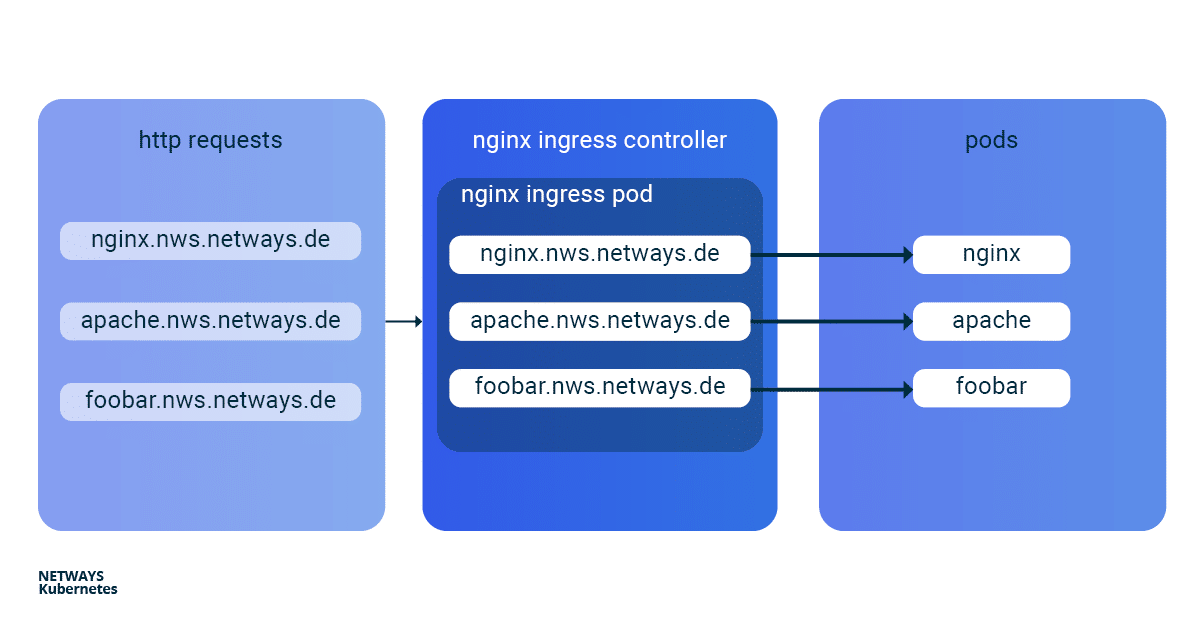
Installation Kubernetes Nginx Ingress Controller

Zur einfachen Installation des Kubernetes Nginx Ingress Controllers solltest Du Helm verwenden. Helm bezeichnet sich selbst als Paketmanager für Kubernetes-Anwendungen. Neben der Installation bietet Helm auch einfache Updates seiner Anwendungen. Wie auch bei kubectl brauchst Du nur die K8s-Config, um direkt loszulegen:
helm install my-ingress stable/nginx-ingress
Mit diesen Befehlen startet Helm alle nötigen Komponenten im default Namespace und gibt diesen das Label my-ingress. Für den Nginx Ingress Controller wird ein deployment, ein replicaset und ein pod erstellt. Alle http/s-Anfragen müssen an diesen pod weitergeleitet werden, damit dieser anhand von vHosts und URI-Pfaden die Anfragen sortieren kann. Dafür wurde ein service vom Typ loadbalancer erstellt, welcher auf eine öffentliche IP lauscht und den ankommenden Traffic auf den Ports 443 und 80 an unseren pod weiterleitet. Ein ähnliches Konstrukt wird auch für das default-backend angelegt, auf welche ich hier aber nicht näher eingehe. Damit Du den Überblick nicht verlierst, kannst Du Dir alle beteiligten Komponenten mit kubectl anzeigen lassen:
kubectl get all -l release=my-ingress #with default-backend
kubectl get all -l release=my-ingress -l component=controller #without default-backend
NAME READY STATUS RESTARTS
pod/my-ingress-nginx-ingress-controller-5b649cbcd8-6hgz6 1/1 Running 0
NAME READY UP-TO-DATE AVAILABLE
deployment.apps/my-ingress-nginx-ingress-controller 1/1 1 1
NAME DESIRED CURRENT READY
replicaset.apps/my-ingress-nginx-ingress-controller-5b649cbcd8 1 1 1
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S)
service/my-ingress-nginx-ingress-controller LoadBalancer 10.254.252.54 185.233.188.56 80:32110/TCP,443:31428/TCP
Beispielanwendungen: Apache und Nginx
Als nächstes starten wir zwei einfache Beispielanwendungen. Im Beispiel verwende ich Apache und Nginx. Ziel ist es, beide Anwendungen unter eigenen name-based virtual hosts verfügbar zu machen: nginx.nws.netways.de und apache.nws.netways.de. Damit die beiden Deployments innerhalb des K8s Clusters erreichbar sind, müssen wir diese noch jeweils mit einem Service verbinden.
K8s Deployments
Nginx Deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
Apache Deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: apache-deployment
labels:
app: apache
spec:
replicas: 3
selector:
matchLabels:
app: apache
template:
metadata:
labels:
app: apache
spec:
containers:
- name: apache
image: httpd:2.4
ports:
- containerPort: 80
K8s Service
Nginx Service
apiVersion: v1
kind: Service
metadata:
name: nginx-svc
spec:
ports:
- port: 80
targetPort: 80
protocol: TCP
name: http
selector:
app: nginx
Apache Service
apiVersion: v1
kind: Service
metadata:
name: apache-svc
spec:
ports:
- port: 80
targetPort: 80
protocol: TCP
name: http
selector:
app: apache
Virtual Hosts ohne TLS
Um nun die Anfragen vom Nginx Controller zu unseren Anwendungen weiterzureichen, müssen wir ein passendes Kubernetes Ingress Objekt ausrollen. Im spec Bereich des Ingress Objekts können wir unterschiedliche Pfade und virtuell Hosts definieren. Im Beispiel sehen wir vHosts für nginx.nws.netways.de und apache.nws.netways.de. Für jeden der beiden vHosts ist im Bereich backend natürlich der entsprechende service eingetragen. Die öffentliche IP findet man im service des Nginx Ingress Controllers und kubectl describe zeigt alle wichtigen Details zum Service (siehe unten). Zum Testen manipulierst Du am besten seine /etc/hosts Datei und trägst dort die IP von LoadBalancer Ingress ein.
K8s Ingress
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
name: my-ingress
spec:
rules:
- host: apache.nws.netways.de
http:
paths:
- backend:
serviceName: apache-svc
servicePort: 80
- host: nginx.nws.netways.de
http:
paths:
- backend:
serviceName: nginx-svc
servicePort: 80
kubectl describe service/my-ingress-nginx-ingress-controller
kubectl get service/my-ingress-nginx-ingress-controller -o jsonpath='{.status.loadBalancer.ingress[].ip}’
Virtual Hosts mit TLS
Natürlich bietet man selten Anwendungen ohne Verschlüsselung öffentlich erreichbar an. Speziell für TLS-Zertifikate hat Kubernetes einen eigenen Typ
tls innerhalb des
secret Objekts. Alles was man benötigt ist ein TLS-Zertifikat und den dazugehörigen Schlüssel. Mit
kubectl kannst Du das Pärchen in Kubernetes speichern:
kubectl create secret tls my-secret –key cert.key –cert cert.crt
Das angelegte secret kann dann durch den angegebenen Namen my-secret in spec des Ingress Objekts referenziert werden. Dazu gibst Du im Array hosts innerhalb von tls unser virtual host und das dazugehörige TLS-Zertifikat an. Ein automatischer Redirect von http auf https ist von Anfang an aktiviert.
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
name: my-ingress
spec:
tls:
- hosts:
- apache.nws.netways.de
- nginx.nws.netways.de
secretName: my-secret
rules:
- host: apache.nws.netways.de
http:
paths:
- backend:
serviceName: apache-svc
servicePort: 80
- host: nginx.nws.netways.de
http:
paths:
- backend:
serviceName: nginx-svc
servicePort: 80
Fazit
Mit dem Nginx Ingress Controller ist es eine Leichtigkeit, Deine webbasierten Anwendungen öffentlich erreichbar zu machen. Die angebotenen Features und Konfigurationsmöglichkeiten sollten die Anforderungen aller Anwendungen abdecken und sind im offiziellen User Guide zu finden. Neben der eigenen Anwendung benötigst Du nur ein Helm Chart und ein K8s Ingress-Objekt. Kubernetes schafft es auch hier, mit nur wenigen abstrakten Objekten wie deployment und ingress viele komplexe Ebenen und Technologien zu verstecken. Mit einer NETWAYS Managed Kubernetes Lösung kannst Du die Vorteile dieser Abstraktion voll ausnutzen und Dich auf die eigene Anwendung konzentrieren. Na also: Leg los!
Recent Comments