
Viele von Euch sind vermutlich bereits mit der Verwendung von Terraform in Kombination mit Azure oder AWS vertraut. Und obwohl dies die am häufigsten verwendeten Plattformen sind, gibt es – oftmals im Bezug auf Datenschutz (DSGVO) – Unwägbarkeiten und somit weiterhin einen Bedarf an zuverlässigen Alternativen. Da all unsere Systeme auf Open-Source basieren, beschäftigen wir uns an dieser Stelle mit der Verwendung von Terraform in Kombination mit OpenStack. Wir versuchen stets, all unsere Dienste in OpenStack zu integrieren und erstellen anschließend Tutorials, um auch der Community zu helfen. Durch die Verwendung von Terraform mit OpenStack kann man nach Belieben sofort mit dem Deployment von Servern beginnen. Dieses Tutorial führt Euch durch die ersten Schritte.
Terraform und OpenStack verstehen
Terraform ist ein fantastisches Tool für die Bereitstellung von Infrastrukturen. In den richtigen Händen kann es die Art und Weise wie Ressourcen bereitgestellt werden, verändern. Der Einstieg in Terraform ist relativ einfach und bereits innerhalb weniger Minuten können Server in unserem OpenStack-Projekt deployed werden. Terraform ist deklarativ, was bedeutet, dass Du das Endergebnis definierst und Terraform den Rest für Dich erledigen lässt. OpenStack hingegen ist ein großartiger Open-Source-Cloud-Anbieter mit vielen Funktionen, die für eine Vielzahl von Anwendungen zugänglich sind. Beide Tools sind kostenlos und bedingen keine Anschaffung. Du musst – wie bei NETWAYS Web Services üblich – nur für die tatsächlich entstandenen Serverkosten aufkommen. Und diese sind geringer als Du denkst!
Terraform installieren
Wir gehen an dieser Stelle davon aus, dass Du Dich bereits eingehend mit OpenStack-Projekten beschäftigt hast und werden uns mehr auf die Einrichtung von Terraform konzentrieren. Falls Terraform bisher nicht installiert wurde, haben wir hier eine kurze Anleitung für Dich: Wenn Du mit macOS arbeitest, hast Du Glück. Man benötigt nur die folgenden zwei Befehle um loszulegen:
brew tap hashicorp/tap brew install hashicorp/tap/terraform
Somit wird das Repository und alles, was sonst benötigt wird, installiert. Anschließend stellen wir sicher, dass das Setup funktionsfähig ist. Indem man „terraform“ in die Konsole eingibt, kann man prüfen, ob man eine Antwort erhält. 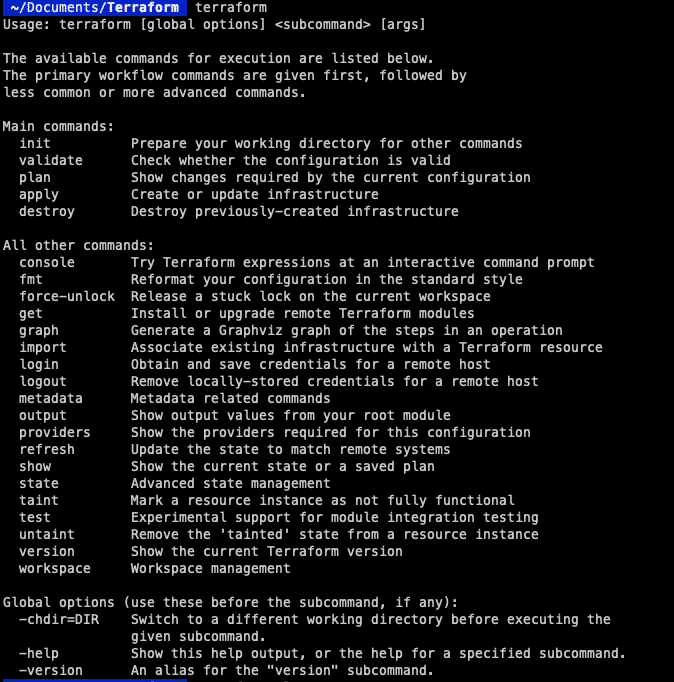 Unter Linux benötigt man jedoch ein paar weitere Befehle, um das System zum Laufen zu bringen. Zunächst muss der GPG-Schlüssel zum System hinzugefügt werden:
Unter Linux benötigt man jedoch ein paar weitere Befehle, um das System zum Laufen zu bringen. Zunächst muss der GPG-Schlüssel zum System hinzugefügt werden:
wget -O- https://apt.releases.hashicorp.com/gpg | gpg --dearmor | sudo tee /usr/share/keyrings/hashicorp-archive-keyring.gpg
Nun können wir das offizielle Repository der HashiCorp hinzufügen:
echo "deb [signed-by=/usr/share/keyrings/hashicorp-archive-keyring.gpg] https://apt.releases.hashicorp.com $(lsb_release -cs) main" | sudo tee /etc/apt/sources.list.d/hashicorp.list
Anschließend kann der Server geupdated und Terraform installiert werden.
sudo apt update sudo apt install terraform
Auch hier können wir mit dem „terraform“-Befehl überprüfen, ob alles korrekt installiert ist. Ist dies der Fall, kümmern wir uns im nächsten Schritt um die Authentifizierung, damit wir mit OpenStack kommunizieren können.
Terraform konfigurieren
Für alle Terraform-Umgebungen wird eine Datei namens „main.tf“ benötigt. Darin wird der gewünschte Cloud-Anbieter, einschließlich aufzusetzender Server und einzubindender Module, konfiguriert. Ggf. möchtest Du zunächst ein eigenes Verzeichnis für Terraform erstellen, aber das bleibt letztendlich Dir überlassen.
mkdir terraform cd terraform vim main.tf
Untenstehend findest Du meine “main.tf” File. So kann die Konfiguration im Einzelnen aussehen:
terraform {
required_version = ">= 0.14.0"
required_providers {
openstack = {
source = "terraform-provider-openstack/openstack"
version = "~> 1.48.0"
}
}
}
provider "openstack" {
auth_url = "https://cloud.netways.de:5000/v3/"
user_name = "1234-openstack-56789"
password = "supersecretpassword"
region = "HetznerNBG4"
user_domain_name = "Default"
tenant_name = "1234-openstack-56789"
}
Dies ist die grundlegende Einstellung, dieDu benötigst, um mit Deinem OpenStack-Provider zu kommunizieren. Zu Beginn definieren wir die Versionen, die wir für Terraform und OpenStack verwenden wollen. Der Abschnitt „Provider“ ist der Authentifizierung gewidmet, die man für die Kommunikation benötigt. Viele dieser Informationen können auch im Projekt unter API Access und clouds.yaml eingesehen werden, u.a.:
terraform init
Dies ist erforderlich, da Terraform – obwohl wir es bereits installiert haben – nicht den Code für alle Provider sammelt. Das übernehmen wir an der Stelle, um alle Informationen zu bekommen, die wir für OpenStack benötigen. Anschließend sind wir in der Lage, mit unserem Projekt zu kommunizieren. Jetzt können wir damit beginnen, eine Infrastruktur aufzubauen und unsere Ressourcen zum Laufen zu bringen! Für dieses Beispiel werden wir einen Server mit einem Standard-Flavour und einem SSH-Schlüssel starten. Hier ist meine Konfiguration für beide Ressourcen:
resource "openstack_compute_instance_v2" “example-server" {
name = "terraform-test"
flavor_name = "s1.small"
image_name = "Ubuntu Jammy 22.04 LTS"
security_groups = [
"HTTP",
"SSH"
]
network {
name = "6801-openstack-ca070"
}
key_pair = "ssh"
}
Dies ist ein sehr einfaches Setup für den Anfang. Weitere Notwendigkeiten findest Du im folgenden Absatz.
Weiteres Vorgehen
Zunächst kümmern wir uns um die Ressource oder den Server, den wir erstellen wollen. Achte darauf, dass die eingegebenen Werte mit den Werten im Projekt übereinstimmen, sonst wird die Instanz nicht korrekt erstellt. Die von mir verwendeten Sicherheitsgruppen waren bereits in meinem Projekt vorhanden, da ich sie für ein früheres Projekt konfiguriert hatte. Darunter befindet sich mein SSH-Schlüssel, damit ich mich auch später noch mit dem Server verbinden kann. Dies muss zwangsläufig bei der Erstellung des Servers geschehen. Hier siehst Du die vollständige Konfiguration für die Einrichtung des Cloud-Providers und des Servers, den ich einsetzen möchte:
terraform {
required_version = ">= 0.14.0"
required_providers {
openstack = {
source = "terraform-provider-openstack/openstack"
version = "~> 1.48.0"
}
}
}
provider "openstack" {
auth_url = "https://cloud.netways.de:5000/v3/"
user_name = "1234-openstack-56789"
password = "supersecretpassword"
region = "HetznerNBG4"
user_domain_name = "Default"
tenant_name = "1234-openstack-56789"
}
resource "openstack_compute_instance_v2" “example-server" {
name = "terraform-test"
flavor_name = "s1.small"
image_name = "Ubuntu Jammy 22.04 LTS"
security_groups = [
"jitsi",
"SSH"
]
network {
name = "6801-openstack-ca070"
}
key_pair = "ssh"
}
Da unsere Konfiguration eingerichtet ist, können wir jetzt einen Probelauf machen, um zu sehen, welche Änderungen vorgenommen werden. Bevor die Änderungen tatsächlich angewendet werden, ist es immer ratsam, die Konfiguration vorab auszuprobieren. So kann man den Code nochmals überprüfen, bevor er deployed wird. Der Graph, der sich aus dem Befehl ergibt, ist dem von git sehr ähnlich. Er zeigt Dir mit „+“ und „-“ an, welche Änderungen sich ergeben. Auf diese Weise erhält man einen besseren Überblick.
terraform plan
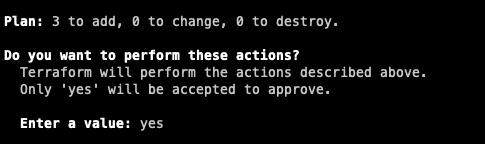
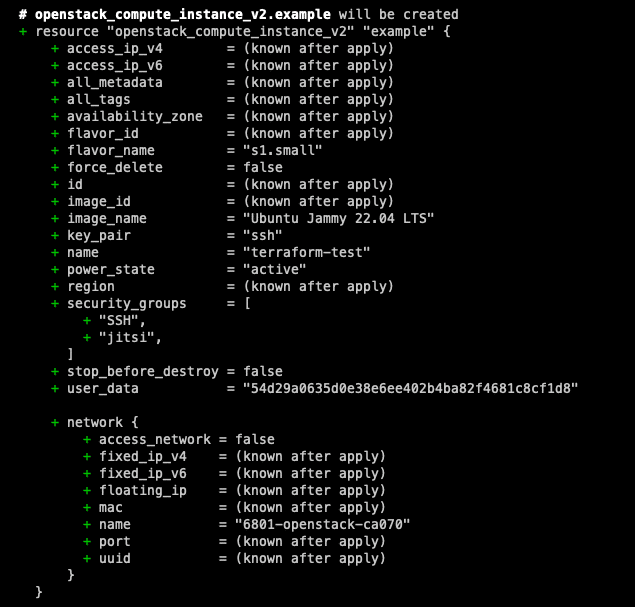 Wenn Du mit den angezeigten Änderungen zufrieden bist und es keine Fehler gibt, kannst Du den nächsten Befehl ausführen, um die Änderungen tatsächlich anzuwenden. Du hast anschließend der Möglichkeit, die Änderungen zu bestätigen oder abzubrechen.
Wenn Du mit den angezeigten Änderungen zufrieden bist und es keine Fehler gibt, kannst Du den nächsten Befehl ausführen, um die Änderungen tatsächlich anzuwenden. Du hast anschließend der Möglichkeit, die Änderungen zu bestätigen oder abzubrechen.
terraform app
 Wenn man mit dem Setup fertig ist und dieses nicht länger benötigt, können die Ressourcen anschließend mit untenstehenden Befehl wieder freigegeben werden. Sei jedoch vorsichtig, denn dadurch wird die gesamte Konfiguration entfernt. Falls weitere Personen an der Machine arbeiten, kann es sein, dass diese fortan nicht mehr darauf zugreifen können!
Wenn man mit dem Setup fertig ist und dieses nicht länger benötigt, können die Ressourcen anschließend mit untenstehenden Befehl wieder freigegeben werden. Sei jedoch vorsichtig, denn dadurch wird die gesamte Konfiguration entfernt. Falls weitere Personen an der Machine arbeiten, kann es sein, dass diese fortan nicht mehr darauf zugreifen können!
terraform destroy
Zusammenfassung
Presto! Deine ersten Schritte in der Welt des Provisioning mit OpenStack sind getan. Was wir in diesem Tutorial im kleinen Rahmen beschrieben haben, verändert an sich nicht die Welt. Aber es eröffnet Dir viele weitere Möglichkeiten für Deine künftigen Projekte. Mit dem deklarativen Ansatz von Terraform und der Flexibilität von OpenStack wird die Bereitstellung und Verwaltung von Infrastrukturressourcen effizient und zugänglich. Aber das ist noch nicht alles: in den kommenden Terraform Tutorials beschäftigen wir uns mit spezifischen Konfigurationen in Verwendung mit OpenStack. Starte Dein eigenes Projekt mithilfe unserer OpenStack Cloudlösung und probier es selbst aus! Und falls Du Hilfestellung benötigst, sind unsere MyEngineers jederzeit für Dich da.









