

With our managed AI models, we at NETWAYS Web Services offer you various AI models for privacy-compliant use. Depending on your use case, you can use general models, embedding or reranking models in your applications via standardized APIs.
The use of AI models via the API entails variable resource consumption – depending on how and for what the models are used. To give you more planning and financial security and control, we have introduced new options for controlling token throughput in MyNWS.
Rate limits: Global or per API key
API rate limits can now be configured flexibly – either globally for your entire project or granularly at the level of individual API keys. This makes it possible to control different use cases or teams in a targeted manner and limit unexpected load peaks.
The limits take effect in a rolling 60-second interval and can be set independently of each other for input tokens and output tokens. This separation allows for much more precise control, particularly in applications with a very different ratio of request to response length – such as summaries or structured data extraction.
Consumption at a glance: Model usage in MyNWS
You can view the actual token consumption per billing month at any time in MyNWS under the Usage tab in the overview of your project.
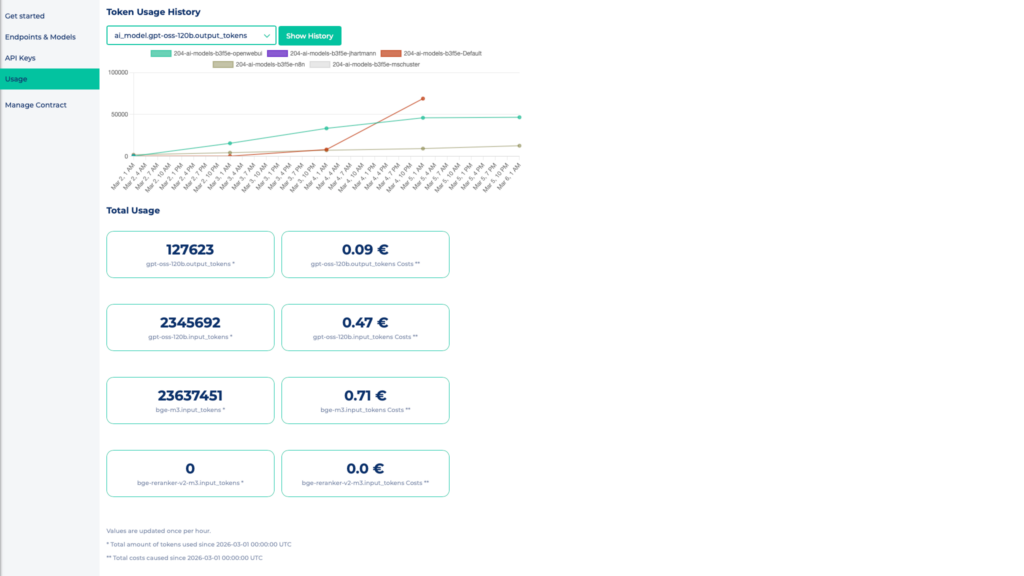
The usage and costs incurred are displayed here for each available model, broken down into input and output tokens. In addition, the token usage per model is visualized over time in a diagram.
This allows you to track consumption in the current month and compare it with the set limits.
Capacity planning and empirical values
The actual token consumption varies depending on the intended use. As a rough estimate, we have observed a distribution of around 80 % input tokens to 20 % output tokens.
You can use this guideline as a starting point for the initial configuration of your rate limits. After some time, however, you should validate the set limits based on your actual usage profile.
If you have any questions about the configuration or dimensioning of your limits, our MyEngineer® is of course also at your disposal.




0 Comments