

Mit unseren gemanagten KI-Modellen bieten wir dir bei NETWAYS Web Services verschiedene KI-Modelle zur datenschutzkonformen Nutzung an. Je nach Anwendungsfall kannst du in deine Anwendungen allgemeine Modelle, Embedding- oder Reranking-Modelle über standardisierte APIs nutzen.
Der Einsatz von KI-Modellen über die API bringt einen variablen Ressourcenverbrauch mit sich – abhängig davon, wie und wofür die Modelle genutzt werden. Um dir mehr Planungssicherheit und Kontrolle zu geben, haben wir in MyNWS neue Optionen zur Steuerung des Tokendurchsatzes eingeführt.
Rate-Limits: Global oder pro API-Key
API Rate-Limits lassen sich ab sofort flexibel konfigurieren – entweder global für dein gesamtes Projekt oder granular auf Ebene einzelner API-Keys. Das ermöglicht es, verschiedene Anwendungsfälle oder Teams gezielt zu steuern und unerwartete Lastspitzen zu begrenzen.
Die Limits greifen in einem rollierenden 60-Sekunden-Intervall und können unabhängig voneinander für Input-Token und Output-Token gesetzt werden. Gerade bei Anwendungen mit stark unterschiedlichem Verhältnis von Anfrage- zu Antwortlänge – etwa Zusammenfassungen oder strukturierte Datenextraktion – erlaubt diese Trennung eine deutlich präzisere Steuerung.
Verbrauch im Blick: Modelusage in MyNWS
Den tatsächlichen Tokenverbrauch pro Abrechnungsmonat kannst du jederzeit in MyNWS unter dem Reiter Usage in der Übersicht deines Projekts einsehen.
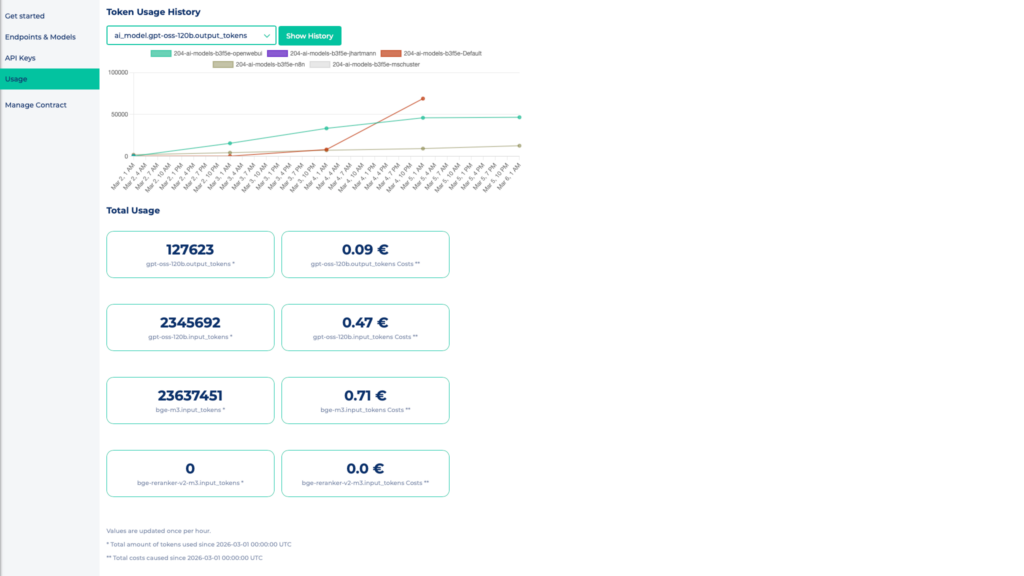
Die Nutzung und entstandene Kosten werden hier für jedes verfügbare Modell nach Input- und Output-Token aufgeschlüsselt angezeigt. Zusätzlich wird die Tokennutzung pro Modell über Zeit in einem Diagramm visualisiert.
So lässt sich der Verbrauch im laufenden Monat nachverfolgen und mit den gesetzten Limits abgleichen.
Kapazitätsplanung und Erfahrungswerte
Der konkrete Tokenverbrauch variiert je nach Einsatzzweck. Als grober Anhaltspunkt kann eine von uns beobachtete Verteilung von rund 80 % Input-Token zu 20 % Output-Token dienen.
Diesen Richtwert kannst du als Ausgangspunkt für die initiale Konfiguration deiner Rate-Limits verwenden. Nach einiger Zeit solltest du aber anhand deines tatsächlichen Nutzungsprofils die gesetzten Limits validieren.
Bei Fragen zur Konfiguration oder zur Dimensionierung deines Limits steht dir natürlich auch unser MyEngineer® zur Verfügung.




0 Kommentare