

Retrieval-Augmented Generation
Willkommen zu diesem Tutorial über Retrieval-Augmented Generation (RAG).
Wenn du dich fragst, was RAG ist, warum diese Technik so nützlich sein kann und wie du es in deinem Open-WebUI konfigurierst , bist du hier genau richtig.
Was genau ist RAG und wie funktioniert es?
Retrieval-Augmented Generation (RAG) ist eine der wichtigsten Techniken der letzten Jahre, um große Sprachmodelle (Large Language Models, LLMs) deutlich zuverlässiger zu machen, ohne dass, das Modell ständig neu trainiert oder feinjustiert werden muss.
Der grundlegende Ablauf von RAG sieht folgendermaßen aus:
Zunächst werden vorhandene Texte, zum Beispiel PDFs oder andere Dokumente, mithilfe einer Content-Extraction-Engine wie Apache Tika, die Inhalte aus Formaten wie PDF, Word oder HTML extrahiert und für die Weiterverarbeitung als Text aufbereitet, in kleinere Abschnitte (sogenannte Chunks) aufgeteilt.
Diese Textabschnitte werden anschließend mithilfe eines Embedding-Modells in numerische Vektoren umgewandelt, die die semantische Bedeutung des Inhalts repräsentieren.
Die erzeugten Embeddings werden dann in einer Vektordatenbank gespeichert.
Stellt ein Nutzer nun eine Frage, wird auch diese Anfrage in ein Embedding umgewandelt. Ein Retrieval-Mechanismus durchsucht daraufhin die Vektordatenbank nach den inhaltlich ähnlichsten Einträgen und wählt die relevantesten Textabschnitte aus (oft als *Top-K Chunks* bezeichnet).
Diese gefundenen Informationen werden anschließend zusammen mit der ursprünglichen Nutzerfrage an das Sprachmodell (LLM) übergeben. Das Modell nutzt sowohl sein internes Wissen als auch die externen, abgerufenen Inhalte, um eine möglichst präzise und kontextreiche Antwort zu generieren.
Man kann sich RAG wie einen Assistenten vorstellen, der zuerst gezielt in einem Buch nachschlägt, bevor er eine Erklärung gibt, statt ausschließlich aus dem Gedächtnis zu antworten.
Welchen Mehrwert bietet RAG?
Der Einsatz von RAG bringt mehrere entscheidende Vorteile mit sich:
– Genauere Antworten:
Das Sprachmodell halluziniert deutlich weniger, da es auf konkreten, externen Quellen basiert.
– Aktuelles Wissen:
Neue oder aktualisierte Dokumente können jederzeit hinzugefügt werden, ohne das Modell neu zu trainieren.
– Individuelle Anpassung:
RAG eignet sich besonders gut für den Einsatz mit eigenen Daten, etwa im Kundenservice, bei internen Wissensdatenbanken, in der Recherche oder im Bildungsbereich.
Kurz gesagt:
RAG macht KI-Systeme zuverlässiger, transparenter und praxisnäher, insbesondere dann, wenn sie mit spezifischen oder aktuellen Informationen arbeiten sollen.
Was macht ein Reranker?
Ein Reranker ist ein **eigenständiges Modell** und eine zusätzliche Komponente in einer RAG-Pipeline, die nach dem eigentlichen Retrieval zum Einsatz kommt.
Während der Retrieval-Schritt meist auf Vektorähnlichkeit basiert, bewertet der Reranker die gefundenen Textabschnitte noch einmal deutlich genauer.
Konkret erhält das Reranker-Modell die Nutzeranfrage sowie die zuvor abgerufenen *Top-K Chunks* und berechnet für jeden Abschnitt, wie gut er inhaltlich zur Anfrage passt. Dabei kommen häufig leistungsfähigere, aber auch rechenintensivere Modellarchitekturen zum Einsatz, zum Beispiel sogenannte Cross-Encoder.
Auf Basis dieser Bewertung sortiert der Reranker die Textabschnitte neu und wählt die relevantesten Inhalte aus. Nur die besten Treffer werden anschließend an das Sprachmodell (LLM) weitergegeben.
Der Vorteil eines Rerankers liegt in einer höheren Antwortqualität:
Irrelevante oder nur oberflächlich passende Textstellen werden herausgefiltert, während wirklich relevante Informationen priorisiert werden. Dadurch verbessert sich sowohl die Genauigkeit als auch die Konsistenz der generierten Antworten.
RAG mit OpenWebUI umsetzen
OpenWebUI bietet eine der benutzerfreundlichsten Möglichkeiten, RAG lokal oder mit externen APIs zu betreiben. Es unterstützt OpenAI-kompatible Endpoints, sodass Modelle von Anbietern wie uns, aber auch von Mistral etc., sehr einfach genutzt werden können.
Im Admin-Bereich unter Einstellungen -> Verbindungen -> OpenAI-API kannst du die Verbidnung zur OpenAI-kompatiblen API festlegen.
– API Base URL: `https://api.ai.nws.netways.de/v1`
– API-KEY hinterlegen
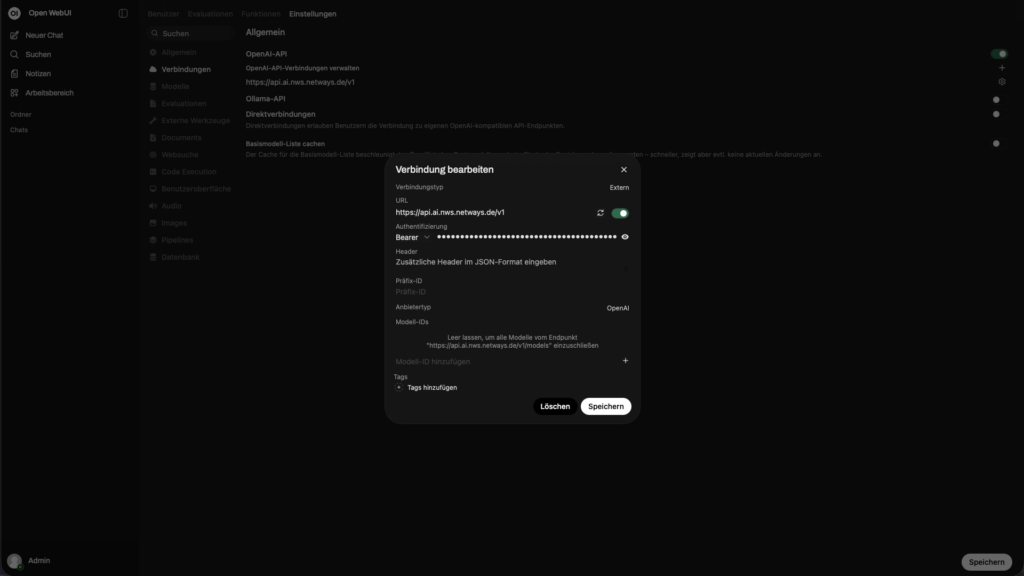
Das wars auch schon, somit ist das Textmodell eingerichtet.
Jetzt können wir mit den RAG-Einstellungen weitermachen. Wechsle dazu in den Tab Dokumente.
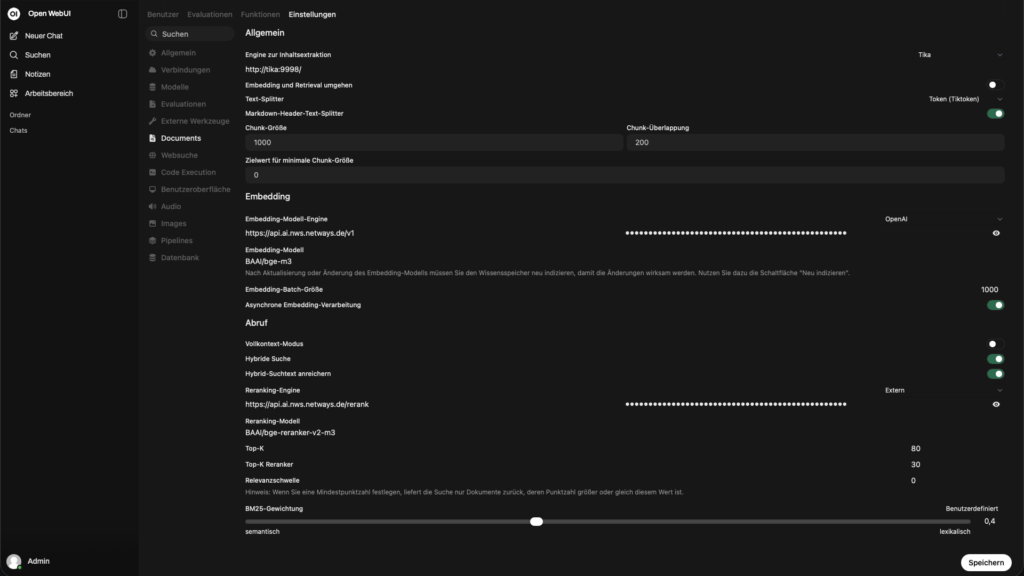
Empfohlene Einstellungen
– Content Extraction Engine: Setze die Option auf Tika falls du ein Apache Tika lokal betreibst, ansonsten sollte standard stehen bleiben.
Apache Tika eignet sich super zum Parsen von nahezu allen Dateiformate (PDF, DOCX, PPTX, EPUB, HTML, E-Mails, Bilder mit OCR usw.) und extrahiert diese als reinen Text und Metadaten. Ohne Tika werden viele Dokumente nur unvollständig oder gar nicht indexiert.
– Embedding und Retrieval umgehen: Aus
– Text-Splitter: Tiktoken
Tiktoken ist der offizielle Tokenizer von OpenAI (cl100k_base, o200k_base etc.). Er teilt den Text so auf, wie es das verwendete LLM später auch sehen würde, deutlich präziser als naive Whitespace- oder Sentence-Splitter.
– Chunk Size und Chunk Overlap:
Typisch: 500–800 Tokens mit 100–200 Overlap.
Zu kleine Chunks führen zu Kontextverlust.
Zu große Chunks führen zu schlechterer Retrieval-Qualität & höheren Kosten.
– Markdown-Header-Text-Splitter: An
– Embedding-Modell-Engine: Im Dropdown OpenAI auswählen, dann die URLhttps://api.ai.nws.netways.de/v1 setzen und den API-Key hinterlegen
– Embedding-Modell: BAAI/bge-m3
Sehr gutes multilinguales Embedding-Modell State-of-the-Art in vielen Benchmarks
– Embedding-Batch-Größe: 1000
– Asynchrone Embedding-Verarbeitung: An
Abruf
– Vollkontext-Modus: Aus
– Hybride Suche: An
– Hybrid-Suchtext anreichern: An
– Reranking-Engine: Im Dropdown Extern auswählen, dann die URL https://api.ai.nws.netways.de/rerank setzen und den API-Key hinterlegen
– Reranking-Modell: BAAI/bge-reranker-v2-m3
Cross-Encoder, der die initialen Top-50 Ergebnisse deutlich besser sortiert als reines Cosine-Ranking
– Top K (initial): 20–50
Top Ergebnisse
– Top K Reranker: 5–10
Viele Top Ergebnisse holen, dann aggressiv mit Reranker filtern.
– Relevance Threshold: meist 0.0–0.18
Verhindert, dass sehr irrelevante Chunks trotzdem mitgegeben werden.
– BM25 Weight: ~0.4–0.6 (Custom)
Gewichtung zwischen lexikalischer (BM25) und semantischer Suche. 0.5 ist oft ein sehr guter Kompromiss.
Fazit
Retrieval-Augmented Generation ist ein wirkungsvolles Konzept, um große Sprachmodelle praxisnah und zuverlässig einzusetzen. Durch die Kombination aus Dokumenten-Extraktion, Vektorsuche, optionalem Reranking und der eigentlichen Textgenerierung lassen sich auch umfangreiche oder spezifische Wissensbestände effizient nutzbar machen.
Gerade in Verbindung mit eigenen Daten bietet RAG einen klaren Mehrwert: aktuellere Informationen, weniger Halluzinationen und besser nachvollziehbare Antworten. Werkzeuge wie Open-WebUI machen den Einstieg dabei vergleichsweise einfach und ermöglichen es, leistungsfähige RAG-Pipelines ohne tiefgreifende Modellanpassungen umzusetzen.
Kurz gesagt: RAG ist kein Zukunftsthema mehr, sondern ein praxisbewährter Ansatz für produktive KI-Anwendungen.
Du möchtest RAG nicht nur verstehen, sondern direkt produktiv einsetzen?
Ob Beratung, Konzeption oder die vollständige Umsetzung einer individuellen RAG-Pipeline, wir unterstützen dich.
Wir helfen dir dabei, eine maßgeschneiderte Lösung aufzusetzen, von der ersten Idee bis zum laufenden System.
Nimm einfach Kontakt mit uns auf und lass uns gemeinsam dein KI-Projekt umsetzen.




0 Kommentare