
You have a brand new Kubernetes cluster and want to get started now? But regardless of whether you have a local minikube or a Managed Kubernetes with all the bells and whistles, the first Kubernetes objects in the super simple YAML format will make almost everyone frown at first. What are deployments, services and so on? And what are all the labels for? Let’s try to shed some light onto this.
The most important Kubernetes Objects
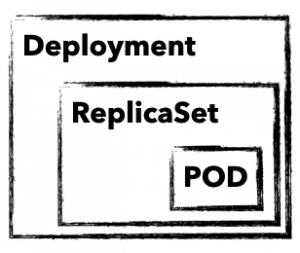 To manage and control a Kubernetes cluster, you need to use Kubernetes-API-Objects, in which you describe the desired state of the cluster. These are sent to the cluster in simple YAML format with the help of kubectl. In addition to an API version, metadata and the object type, there is usually a spec section in which you describe the desired state of your application. spec can be defined differently for each object and is nested in many cases. For example, an object deployment contains attributes for an object replicaSet, which in turn has attributes for a pod object in its own spec section. But before it gets too complicated, here is a brief explanation of these three important objects:
To manage and control a Kubernetes cluster, you need to use Kubernetes-API-Objects, in which you describe the desired state of the cluster. These are sent to the cluster in simple YAML format with the help of kubectl. In addition to an API version, metadata and the object type, there is usually a spec section in which you describe the desired state of your application. spec can be defined differently for each object and is nested in many cases. For example, an object deployment contains attributes for an object replicaSet, which in turn has attributes for a pod object in its own spec section. But before it gets too complicated, here is a brief explanation of these three important objects:
deployment
A deployment describes a desired state of an application and attempts to constantly create it. Deployments can be used to start, scale, update, roll back and delete applications. Deployment objects are usually used to manage applications.
replicaSet
A replicaSet ensures the availability of a defined number of identical pods. If necessary, new pods are started and also stopped. replicaSet is normally only used indirectly through a deployment.
pod
A pod defines a group of containers (often only one) that share a common namespace on a host. The shared namespaces (e.g. shared file system or network) facilitate easy communication between the containers. A pod is always accessible through a unique IP in the cluster. Normally, pods are only used indirectly through a deployment.
With these three objects, we can start our first MariaDB deployment and establish an initial connection with it.
The first K8s-Deployment
As a first simple application, we will start a non-replicated MariaDB as a deployment. But before we take a closer look at the definition, send the object to your cluster with kubectl apply:
But before we take a closer look at the definition, send the object to your cluster with apply:
kubectl apply -f mariadb.yaml deployment.apps/mariadb-deploy created
For changes to your deployment, you can simply adapt the yaml file and send it to your cluster with the same command. If you want to delete your deployment simply replace the apply with a delete.
apiVersion: apps/v1
kind: Deployment
metadata:
name: mariadb-deploy
labels:
app: mariadb
spec:
replicas: 1
selector:
matchLabels:
app: mariadb
template:
metadata:
labels:
app: mariadb
spec:
containers:
- name: mariadb
image: mariadb
ports:
- containerPort: 3306
name: db-port
env:
- name: MYSQL_ROOT_PASSWORD
value: "123456"
Taking a closer look, we find parameters for all three Kubernetes objects in the example.
Lines 1-6: We define API version, kind, name and a freely selectable label for our deployment object.
Lines 8-11: Are part of the replicaset (RS). Here we define matchLabels as well as the number of replicas and include pods with the label mariadb in the RS.
Lines 13-25: Define your pod. In addition to a label, parameters for the MariaDB container are passed. We use the official MariaDB image, define port 3306 and set the root password for the database via an environment variable.
A better overview with describe and get
With describe and get you can get a quick overview and all the necessary details of your applications. A simple kubectl describe deployment/mariadb-deploy provides all details about the MariaDB deployment from the example.
get all on the other hand, lists all objects, but the output can quickly become confusing even with just a few applications in the cluster. That’s why there are different ways to filter the output, e.g. using the label app. With the following examples, however, you will quickly have the output under control.
Example for get with different filters
kubectl get pods kubectl get deployment kubectl get replicaset -l app=mariadb -o json kubectl get po –field-selector=status.phase=Running
The quickest way to display the components of your MariaDB is to use the label filter:
kubectl get all -l app=mariadb
NAME READY STATUS RESTARTS AGE pod/mariadb-deploy-64bfc599f7-j9twt 1/1 Running 0 64s NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/mariadb-deploy 1/1 1 1 64s NAME DESIRED CURRENT READY AGE replicaset.apps/mariadb-deploy-64bfc599f7 1 1 1 64s
Now that you know how to check the current and desired state of your application, let’s take a closer look at pods and containers.
Integrate with pods
Without further configuration, applications are only accessible within the Kubernetes cluster. In addition, you rarely want to make a database accessible via a public IP. kubectl therefore offers two options with proxy and port-forward to guarantee access to internal pods and services. For MariaDB we use port-forward and send all traffic that arrives locally on port 3306 through kubectl to our MariaDB pod. By the way, you can use the name of the deployment directly. The names of pod and replicaSet lead to the same result. The quickest way to check whether the connection is working is to use telnet or a MySQL client:
kubectl port-forward deployment.apps/mariadb-deploy 3306:3306 mysql -h 127.0.0.1 -P 3306 -u root -p123456 telnet 127.0.0.1 3306
kubectl offers further possibilities for interacting with its container with log and exec. The former, of course, shows you the stdout of your pod. exec , on the other hand, is probably mostly used to start an interactive shell. Similar to docker, you need the parameters interactive and tty (-ti), to get a functional bash:
kubectl exec -it mariadb-deploy-64bfc599f7-j9twt — /bin/bash
With these few commands you can reach and debug your pods shielded in the K8s cluster. Applications that are only accessible within the cluster do not always make sense, of course. In order for others to access them, you need a Kubernetes service with a public IP. But there is much more behind a service.
Connect your pods with a service
A service binds a fixed internal IP address (ClusterIP) to a set of pods, which are identified by labels. Compared to a service pods pods are very short-lived. In this example, as soon as we trigger an upgrade of MariaDB, our deployment discards the existing pod and starts a new one. Since each pod has its own IP address, the IP address at which your MariaDB is accessible also changes. Thanks to the labels, the service finds the new pod and the traffic is forwarded correctly.
A service therefore ensures the internal accessibility of your deployments through the ClusterIP. In addition, a service can also have the type Loadbalancer. This binds a public IP and forwards all traffic to the ClusterIP. In the following example, you can see a service for your MariaDB.
apiVersion: v1
kind: Service
metadata:
name: mariadb-service
spec:
ports:
- port: 3306
targetPort: 3306
protocol: TCP
name: mariadb
selector:
app: mariadb
type: LoadBalancer
In this example, exactly one container is defined for a pod and our selector in the server also only applies to one pod. But what happens when replicas are increased in the deployment? First, of course, several pods are started and thus also several MariaDB containers. The selector in the MariaDB service naturally finds them by means of the label and the connections are forwarded to the pods in a round-robin process. Technically, this works without problems in the example, but as long as MariaDB itself is not installed as a replicating cluster, this makes little sense.
What comes next?
With the examples shown here, you can roll out and debug your first applications. But you can already guess that we’ve only scratched the surface on Kubernetes and of course there are still many questions! What happens to my data in MariaDB and how can I connect the short-lived pods to a persistent volume? Do I need a separate public IP for each application? How do I get metrics and logs of my cluster and my applications? We will of course answer these and other questions in the following blogposts. Well then, see you next week!









