
Back in 2010 a solution was created to solve the massive MySQL scalability challenges at YouTube – and then Vitess was born. Later in 2018, the project became part of the Cloud Native Computing Foundation and since 2019 it has been listed as one of the graduated projects. Now it is in good company with other prominent CNCF projects like Kubernetes, Prometheus and some more.
Vitess is an open source MySQL-compatible database clustering system for horizontal scaling – you could also say it is a sharding middleware for MySQL. It combines and extends many important SQL features with the scalability of a NoSQL database, and solves multiple challenges of operating ordinary MySQL setups. With Vitess, MySQL becomes massively scalable and highly available. Its nature is cloud native, but it can also be run on bare metal environments.
Architecture
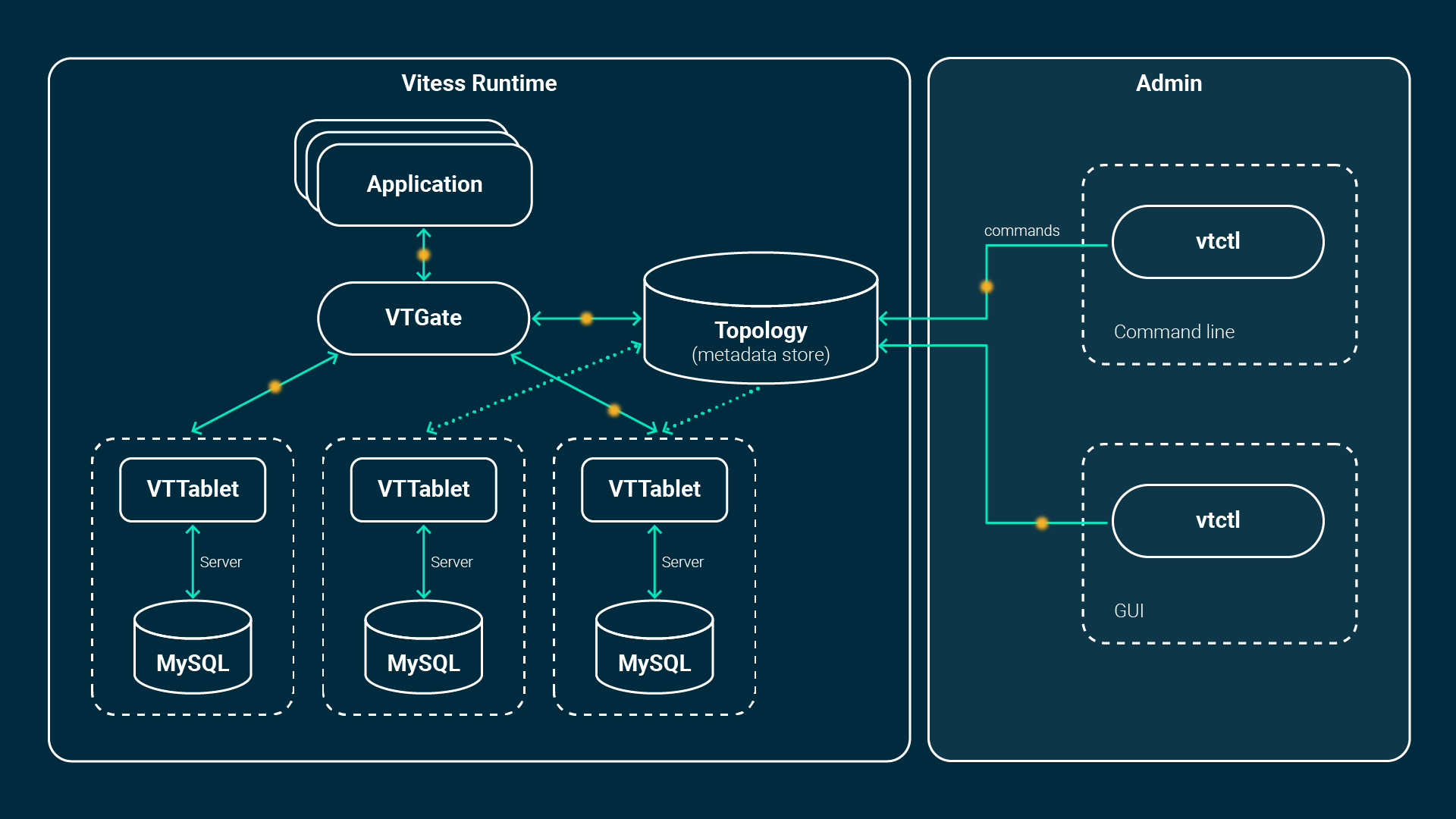
It consists of multiple additional components such as the VTGate, VTTablet, VTctld and a topology service backed by etcd or zookeeper. The application connects either by Vitess’ native database drivers or by using the MySQL protocol, which means any MySQL clients and libraries are compatible.
The application connects to the so called VTGate, a kind of lightweight proxy which knows the state of the MySQL instances (VTTablets) and where what kind of data is stored, in case of sharded databases. This information is stored within the Topology Service. The VTGate routes the queries accordingly to the belonging VTTablets.
A tablet, on the other hand, is the combination of a VTTablet process and the MySQL instance itself. It runs either in primary, replica or read-only mode, if healthy. There is a replication between one primary and multiple replicas per database. If a primary fails, a replica will be promoted and Vitess helps in the process of reparenting. This can all be fully automated. New, additional or failed replicas get instantiated from scratch. They will get the data of the latest backup available and hooked up to the replication. As soon as it catches up, it is part of the cluster and VTGate will forward queries to it. Here’s an image to visualize this whole process:
Scalability Philosophy
Vitess attempts to run small instances not greater than 250GB of data. If your database becomes bigger, it needs to be split into multiple instances. There are multiple good operational benefits of this approach. In case of failures of an instance, it can be recovered much faster with less data. The time to recover is decreased due to faster backup transfers. Also, the replication tends to be happier with less delay. Moving instances and placing them on different nodes for improved resource usage more easily is some plus, too.
Data durability is achieved due to replication. Outages and failures of specific failure domains are quite normal. In cloud native environments it is even more normal that nodes and pods are drained or newly created and you try to be as flexible as possible to such events. Vitess is designed for exactly this and fits perfectly with its fully automatic recovery and reparenting capabilities to a cloud native environment such as Kubernetes.
Further, Vitess is meant to be run across data centres, regions or availability zones. Each domain has its own VTGate and pool of Tablets. This concept is called “Cells” in Vitess. We at NETWAYS Web Services are distributing replicas evenly across our availability zones to survive a complete outage of one zone. It would also be possible to run replicas in geographic regions for better latency and better experience for customers abroad.
Additional Features
Besides its cloud native nature and possibilities of endless scalability, there are even more handy and clever features, such as:
- Connection pooling and Deduplication
Usually MySQL needs to allocate some (~256KB – 3MB) memory for each connection. This memory is for the connections only and not for accelerating queries. Vitess instead creates very lightweight connections leveraging Go’s concurrency support. Those frontend connections then are pooled on less connections to the MySQL-Instances, so that it’s possible to handle thousands of connections smoothly and efficiently. Additionally, it registers identical requests in-flight and holds them back, so that only one query will hit your database. - Query and transaction protection
Have you ever had the need to kill long running queries, which took down your database? Vitess limits the number of concurrent transactions and sets proper timeouts to each. Queries that will take too long will be terminated. Also, poorly written queries without LIMITS will be rewritten and limited, before potentially hurting the system. - Sharding
Its built-in sharding features enable the growth of the database in form of sharding – without the need of adding additional application logic. - Performance Monitoring
Performance analysis tools let you monitor, diagnose, and analyze your database performance. - VReplication and workflows
VReplication is a key mechanism of Vitess. With VReplication, Events of the binlog are streamed from the sender to a receiver. Workflows are – as the name would suggest – flows to complete certain tasks. For instance, it can move a running production table to different database instance with close to no downtime (“MoveTable“). Also streaming a subset of data into another instance can be done by this concept. A “materialized view” comes in handy, if you have to join data, but the tables are sharded on different instances.
Conclusion
Vitess is a very powerful and clever piece of software! To be precise, it is a software used by hyperscalers brought to the masses and now available for everyone. If you want to know more, we will post more tutorials, which will cover more advanced topics, soon on regular basis. The documentation of vitess.io is also a good source to find out more. If you want to try it yourself there are multiple ways of doing so – the most convenient way is to use our Managed Database product and trust on our experience.









