
Sooner or later, everyone who has a server running will reach the point where the VM (or parts of it) irreversibly ” breaks” – by whatever means.
Those who have dedicated themselves to backing up their data in advance are now clearly at an advantage and can expect significantly lower adrenaline levels – especially if the last backup was less than 24 hours ago. In our NWS backups and snapshots are easily configured for your vms to take nightly backups automatically.
In case of vms with SSD system volume there is just the menu feature backup.
We set the retention period to a week for example and confirm:

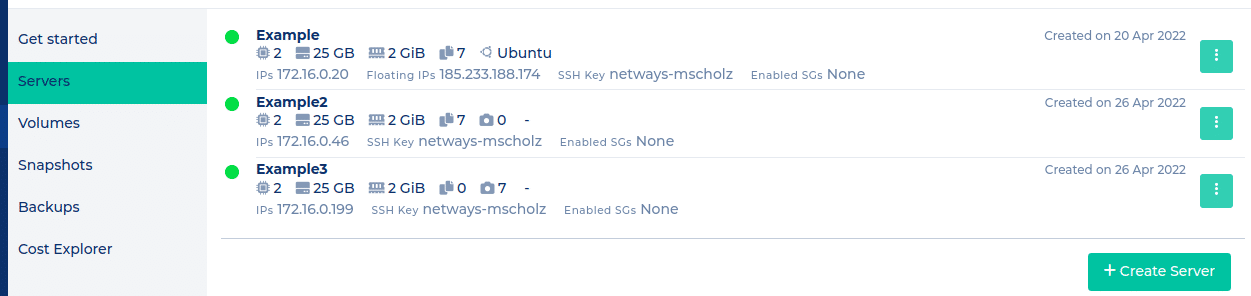
The NWS server list will offer an summary like this for these three cases:
Vm Example: SSD: backup
Vm Example2: Ceph volume: backup
Vm Example3: Ceph volume: snapshot
After their automatical production each night by us, they will become visible under their
particular menu item.
To be able to use a taken backup, we’ll have to switch to Horizon (OpenStack web UI) .
Five days after configuring the backups, you would find something like that for our three servers for example:
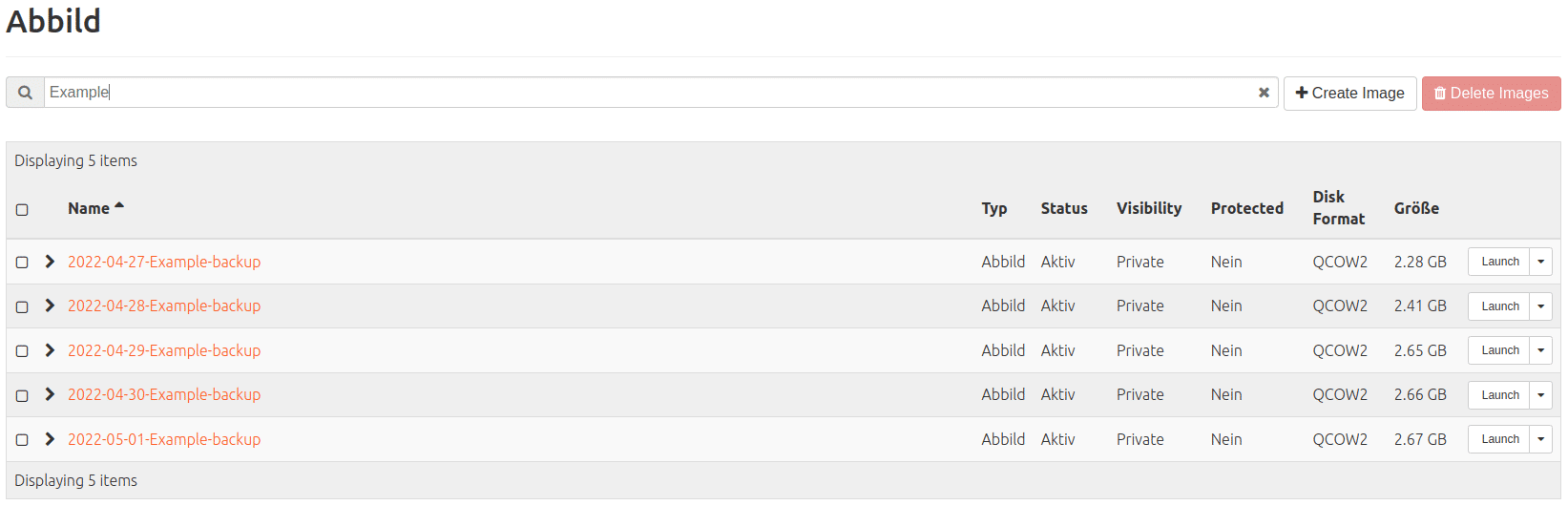
Backup (of SSD; findable under: Compute > Images
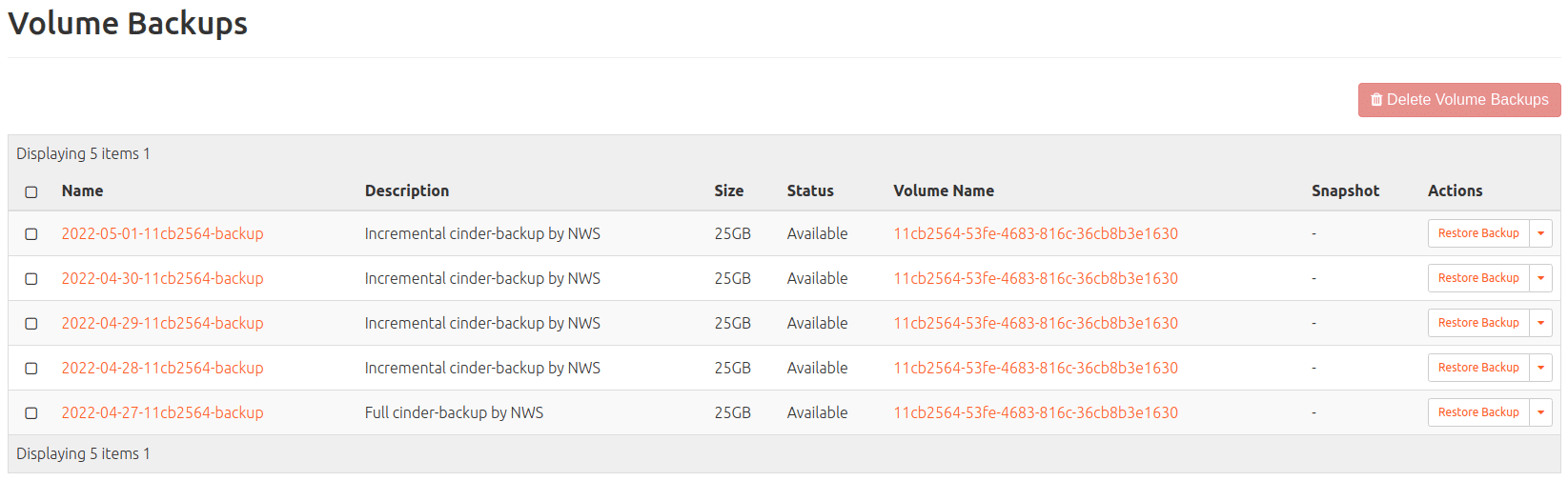
Volume Backup (of Ceph volume; findable under: Volumes > Backups)
Volume Snapshot (of Ceph volume; findable under: Volumes > Snapshots)
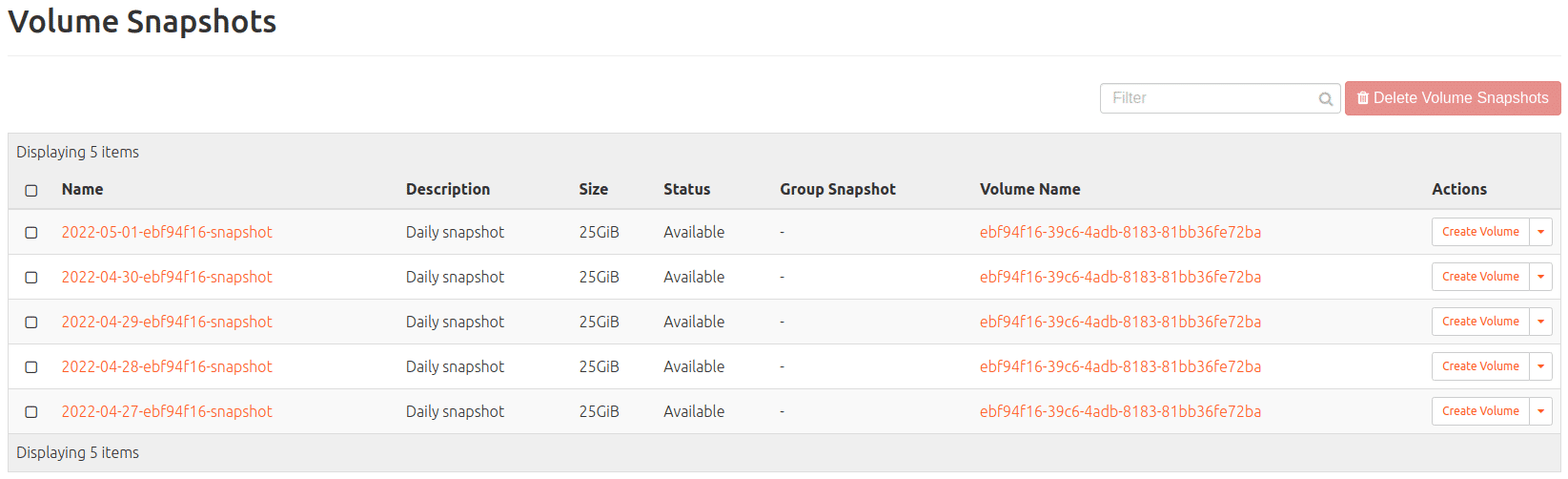
The last-mentioned Snapshots are increments of its underlying volume and are cheaper in comparison to backups; more shortly.
For those who wish to enter these backup settings manually via metadata:
|
what to modify: |
||||
|
Vm on SSD
|
Backup
|
Vm
|
nws_backup=true
|
rotation=7
|
|
Vm with
|
Backup
|
Volume
|
cinder-backup=true
|
cinder-backup-rotation=7
|
|
Vm with |
Snapshot |
Volume |
nws_snapshot=true |
rotation=7 |
Those who want to make their backups/snapshots available again, can e. g.
- create a volume from them and attach it to an existing vm
- (delete the crashed vm and) launch an new vm from it (vms with Ceph volume) or
- rebuild the machine with a particular image/backup (vms on SSD)
Snapshot vs. Backup?
During the production of a volume snapshot it is created in the central OpenStack storage. It is quickly available if needed. This snapshot is replicated threefold at two locations. Due to this replication your data is secured against everyday incidents like hardware failure. Snapshots also save you from bigger desasters like fire or flood at one of the sites. Why is a backup reasonable anyway?
Protection against human error: Is a wrong volume deleted accidentially, all of its data and snapshots are being deleted accordingly. An available backup won’t be affected from that and the volume can be recovered.
Protection against bugs: Albeit current storage systems hold in high quality and run reliably for years due to experience, mistakes in software can lead to data loss. A second independent storage for your backup lessens this hazard considerably.
You got lost replicating/copying? In case of any questions we’d gladly like to help.









