
Die wichtigsten Bausteine zum Starten deiner Anwendung kennst du bereits aus unserer Tutorial-Serie. Für den Betrieb fehlen dir noch Metriken und Logs deiner Anwendungen? Nach diesem Blogpost kannst du letzteres abhaken.
Logging mit Loki und Grafana in Kubernetes – ein Überblick
Zum Sammeln und Verwalten deiner Logs bieten sich auch für Kubernetes eine der wohl bekanntesten, schwergewichtigen Lösungen an. Diese bestehen in der Regel aus Logstash oder Fluentd zum Sammeln, gepaart mit Elasticsearch zum Speichern und Kibana bzw. Graylog zur Visualisierung deiner Logs. Neben dieser klassischen Kombination gibt es seit wenigen Jahren mit Loki und Grafana einen neuen, leichtgewichtigeren Stack! Die grundlegende Architektur unterscheidet sich kaum zu den bekannten Setups. Promtail sammelt auf jedem Kubernetes Node die Logs aller Container und sendet diese an eine zentrale Loki-Instanz. Diese aggregiert alle Logs und schreibt diese in ein Storage-Backend. Zur Visualisierung wird Grafana verwendet, welches sich die Logs direkt von der Loki-Instanz holt. 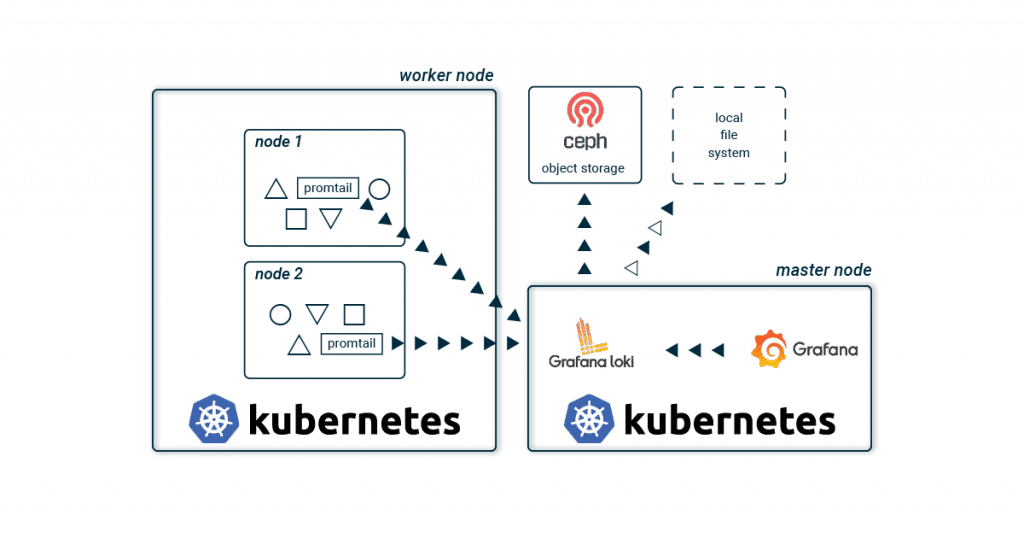 Der größte Unterschied zu den bekannten Stacks liegt wohl im Verzicht auf Elasticsearch. Dies spart Ressourcen und Aufwand, da somit auch kein dreifach replizierter Volltext-Index gespeichert und administriert werden muss. Und gerade wenn man beginnt, seine Anwendung aufzubauen, hört sich ein schlanker und einfacher Stack vielsprechend an. Wächst die Anwendungslandschaft, werden einzelne Komponenten von Loki in die Breite skaliert, um die Last auf mehrere Schultern zu verteilen.
Der größte Unterschied zu den bekannten Stacks liegt wohl im Verzicht auf Elasticsearch. Dies spart Ressourcen und Aufwand, da somit auch kein dreifach replizierter Volltext-Index gespeichert und administriert werden muss. Und gerade wenn man beginnt, seine Anwendung aufzubauen, hört sich ein schlanker und einfacher Stack vielsprechend an. Wächst die Anwendungslandschaft, werden einzelne Komponenten von Loki in die Breite skaliert, um die Last auf mehrere Schultern zu verteilen.
Kein Volltextindex? Wie funktioniert das?
Zur schnellen Suche verzichtet Loki natürlich nicht auf einen Index, aber es werden nur noch Metadaten (ähnlich wie bei Prometheus) indexiert. Der Aufwand, den Index zu betreiben, wird dadurch sehr verkleinert. Für dein Kubernetes-Cluster werden somit hauptsächlich Labels im Index gespeichert und deine Logs werden automatisch anhand derselben Metadaten organisiert wie auch deine Anwendungen in deinem Kubernetes-Cluster. Anhand eines Zeitfensters und den Labels findet Loki schnell und einfach deine gesuchten Logs. Zum Speichern des Index kann aus verschiedenen Datenbanken gewählt werden. Neben den beiden Cloud-Datenbanken BigTable und DynamoDB kann Loki seinen Index auch lokal in Cassandra oder BoltDB ablegen. Letztere unterstützt keine Replikation und ist vor allem für Entwicklungsumgebungen geeignet. Loki bietet mit boltdb-shipper eine weitere Datenbank an, welche aktuell noch in Entwicklung ist. Diese soll vor allem Abhängigkeiten zu einer replizierten Datenbank entfernen und regelmäßig Snapshots des Index im Chunk-Storage speichern (siehe unten). Ein kleines Beispiel
Label vs. Stream
Eine Kombination aus exakt gleichen Labels (inkl. deren Werte) definiert einen Stream. Ändert man ein Label oder dessen Wert, entsteht ein neuer Stream. Die Logs aus stdout eines nginx-Pods befinden sich z.B. in einem Stream mit den Labels: pod-template-hash=bcf574bc8, app=nginx und stream=stdout.
Chunk Storage
Im Chunk Storage werden die komprimierten und zerstückelten Log-Streams gespeichert. Wie beim Index kann auch hier zwischen verschiedenen Storage-Backends gewählt werden. Aufgrund der Größe der Chunks wird ein Object Store wie GCS, S3, Swift oder unser Ceph Object Store empfohlen. Die Replikation ist damit automatisch mit inbegriffen und die Chunks werden anhand eines Ablaufdatums auch selbständig vom Storage entfernt. In kleineren Projekten oder Entwicklungsumgebungen kann man aber natürlich auch mit einem lokalen Dateisystem beginnen.
Visualisierung mit Grafana
Zur Darstellung wird Grafana verwendet. Vorkonfigurierte Dashboards können leicht importiert werden. Als Query Language wird LogQL verwendet. Diese Eigenkreation von Grafana Labs lehnt sich stark an PromQL von Prometheus an und ist genauso schnell gelernt. Eine Abfrage besteht hierbei aus zwei Teilen: Zuerst filtert man mithilfe von Labels und dem Log Stream Selector nach den entsprechenden Chunks. Mit = macht man hier immer einen exakten Vergleich und =~ erlaubt die Verwendungen von Regex. Wie üblich wird mit ! die Selektion negiert. Nachdem man seine Suche auf bestimmte Chunks eingeschränkt hat, kann man diese mit einer Search Expression erweitern. Auch hier kann man mit verschiedenen Operatoren wie |= und |~ das Ergebnis weiter einschränken. Ein paar Beispiele zeigen wohl am schnellsten die Möglichkeiten:
{app = "nginx"}
{app != "nginx"}
{app =~ "ngin.*"}
{app !~ "nginx$"}
{app = "nginx", stream != "stdout"}
{app = "nginx"} |= "192.168.0.1"
{app = "nginx"} != "192.168.0.1"
{app = "nginx"} |~ "192.*"
{app = "nginx"} !~ "192$"
Get it running!
Du willst Loki einfach ausprobieren?
Mit dem NWS Managed Kubernetes Cluster kannst du auf die Details verzichten! Mit einem Klick startest du deinen Loki Stack und hast dein Kubernetes Cluster immer voll im Blick!
Helm installieren
brew install helm apt install helm choco install kubernetes-helm
Dir fehlen die passenden Quellen? Auf helm.sh findest du eine kurze Anleitung für dein Betriebssystem.
helm repo add loki https://grafana.github.io/loki/charts helm repo add stable https://kubernetes-charts.storage.googleapis.com/
Loki und Grafana installieren
---
adminPassword: supersecret
datasources:
datasources.yaml:
apiVersion: 1
datasources:
- name: Loki
type: loki
url: http://loki-headless:3100
jsonData:
maxLines: 1000
plugins:
- grafana-piechart-panel
dashboardProviders:
dashboardproviders.yaml:
apiVersion: 1
providers:
- name: default
orgId: 1
folder:
type: file
disableDeletion: true
editable: false
options:
path: /var/lib/grafana/dashboards/default
dashboards:
default:
Logging:
gnetId: 12611
revison: 1
datasource: Loki
helm install loki loki/loki-stack helm install loki-grafana stable/grafana -f grafana.values kubectl get all -n kube-system -l release=loki
Nach dem Deployment kannst du dich als admin mit dem Passwort supersecret einloggen. Damit du direkt auf das Grafana Webinterface zugreifen kannst, fehlt dir noch noch ein port-forward:
kubectl --namespace kube-system port-forward service/loki-grafana 3001:80
Die Logs deiner laufenden Pods sollten sofort im Grafana sichtbar sein. Probier doch die Queries unter Explore aus und erkunde das Dashboard!
Logging mit Loki und Grafana in Kubernetes – das Fazit
Grafana Labs bietet mit Loki einen neuen Ansatz für ein zentrales Logmanagement. Durch die Verwendung von kostengünstigen und leicht verfügbaren Object Stores wird eine aufwändige Administration eines Elasticsearch-Clusters überflüssig. Das einfache und schnelle Deployment ist auch ideal für Entwicklungsumgebungen geeignet. Zwar bieten die beiden Alternativen Kibana und Graylog ein mächtiges Featureset, aber für manche Administratoren ist Loki mit seinem schlanken und einfachen Stack vielleicht verlockender.









