
In einem vorangegangenen Post erläuterte Sebastian, wie man mit dem Prometheus Operator sein Kubernetes Cluster monitoren kann. Dieser Beitrag baut darauf auf und zeigt, wie man Benachrichtigungen per E-Mail und als Push Notifications mit dem Alertmanager einrichten kann.
Mit Helm den Monitoring Stack installieren
Neben der von Sebastian gezeigten Methode zum deployen des Prometheus Operators gibt es noch eine weitere Variante, mit der sich ein kompletter Prometheus-Stack im Kubernetes Cluster aufsetzen lässt. Und zwar mit Hilfe des Package Managers Helm. Die Sourcen des Helm Charts für den Prometheus Stack kann man sich auf Github ansehen. Dort findet man auch eine Datei die alle Konfigurationsoptionen und Standardwerte des Monitoring-Stacks enthält. Zu den Bestandteilen zählt neben dem Prometheus-Operator und Grafana auch der Prometheus Node Exporter, Kube State Metrics und der Alertmanager. Neu ist an dieser Stelle Kube State Metrics und der Alertmanager. Kube State Metrics bindet sich an die Kubernetes API und kann somit Metriken über sämtliche Ressourcen im Cluster abgrasen. Der Alertmanager kann anhand eines Regelwerks für ausgewählte Metriken alarmieren. Bei dem Setup per Helm kann jede Komponente über die Optionen in der Values Datei konfiguriert werden. Es macht Sinn für Prometheus und Alertmanager jeweils ein PVC zu verwenden um somit die Metriken und History von Alarmen, sowie die Alarmunterdrückungen persistent zu haben. Mit folgenden Values wird in meinem Fall für beides ein Persistent Volume Claim (PVC) angelegt. Der Name der Storage-Class kann natürlich variieren.
alertmanager:
alertmanagerSpec:
storage:
volumeClaimTemplate:
spec:
storageClassName: nws-storage
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 10Gi
prometheus:
prometheusSpec:
storageSpec:
volumeClaimTemplate:
spec:
storageClassName: nws-storage
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 10Gi
Ich speichere mir die Konfiguration im Verzeichnis „prom-config“ als Datei „stack.values“ ab. Nun kann man auch schon den Stack deployen. Zuerst muss man die passenden Repos einbinden:
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts helm repo update
Anschließend wird der Stack erstellt:
helm install nws-prometheus-stack prometheus-community/kube-prometheus-stack -f prom-config/stack.values
Mittels Port-Forwarding kann man per Browser das Grafana Webinterface aufrufen und sich mit den Credentials admin/prom-operator anmelden.
kubectl port-forward service/nws-prometheus-stack-grafana 3002:80
Im Browser anschließend http://localhost:3002/ aufrufen.
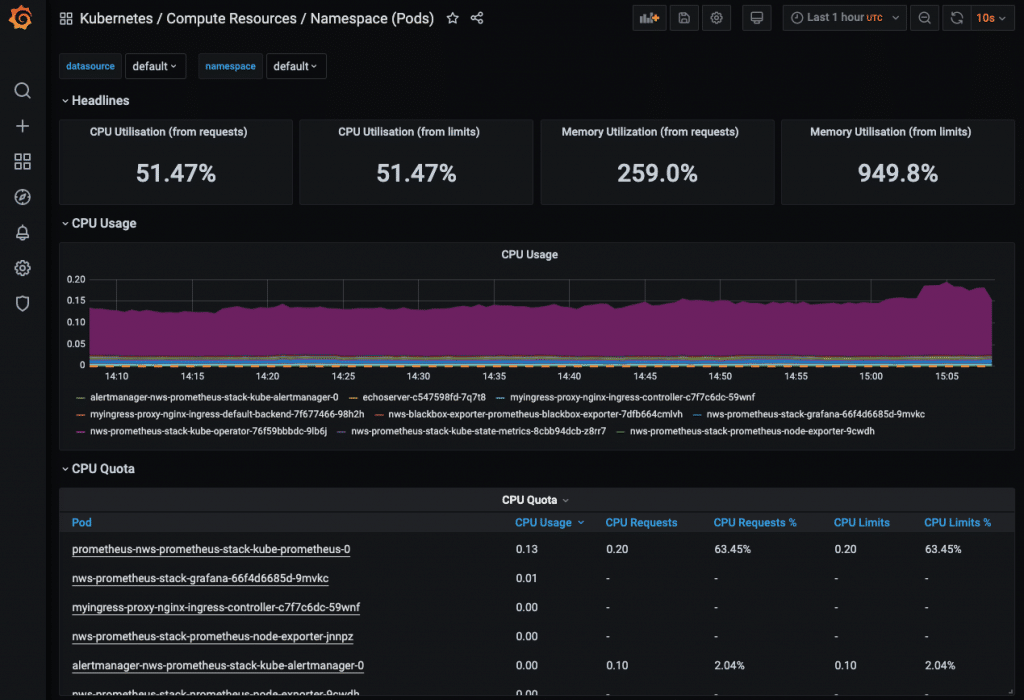
Es sind bereits einige vordefinierte Dashboards mit dabei. Um für alle Dashboards (Scheduler, Etcd, etc.) auch Metriken angezeigt zu bekommen, sind allerdings weitere Optionen in den Values von Prometheus zu setzen. In diesem Post werde ich allerdings nicht darauf eingehen, wie sich diese konfigurieren lassen. Stattdessen möchte ich wie Eingangs erwähnt das Einrichten von Alarmen demonstrieren. Hier kommt der Alertmanager ins Spiel. In Grafana sucht man jedoch vergebens danach. Ein Blick ins Prometheus Web UI macht da mehr Sinn. Also erstmal wieder einen Port-Forward dafür einrichten:
kubectl port-forward service/nws-prometheus-stack-kube-prometheus 3003:9090
Dann im Browser http://localhost:3003/ aufrufen.
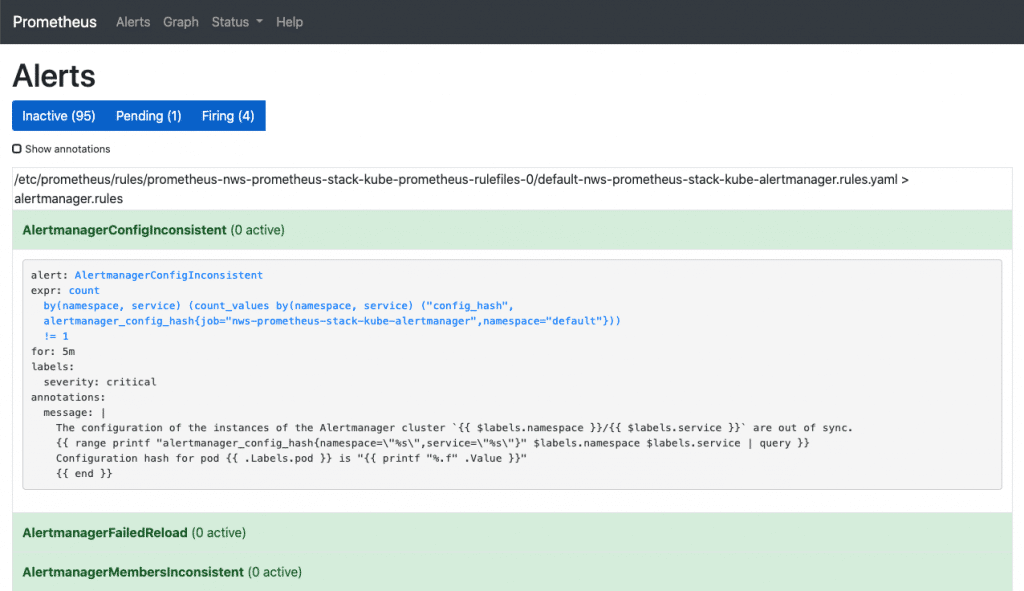
Unter Alerts sieht man sämtliche Alarmregeln, die bei dem Stack bereits vorkonfiguriert dabei sind. Per Klick auf eine beliebige Regel kann man deren Definition sehen. Konfigurieren lässt sich jedoch auch hier nichts. Über die Buttons „Inactive“, „Pending“ und „Firing“ können die Regeln mit dem jeweiligen Status ein-, bzw. ausgeblendet werden. Wir gehen zur nächsten Weboberfläche – Alertmanager. Auch hierfür benötigen wir einen Port-Forward.
kubectl port-forward service/nws-prometheus-stack-kube-alertmanager 3004:9093
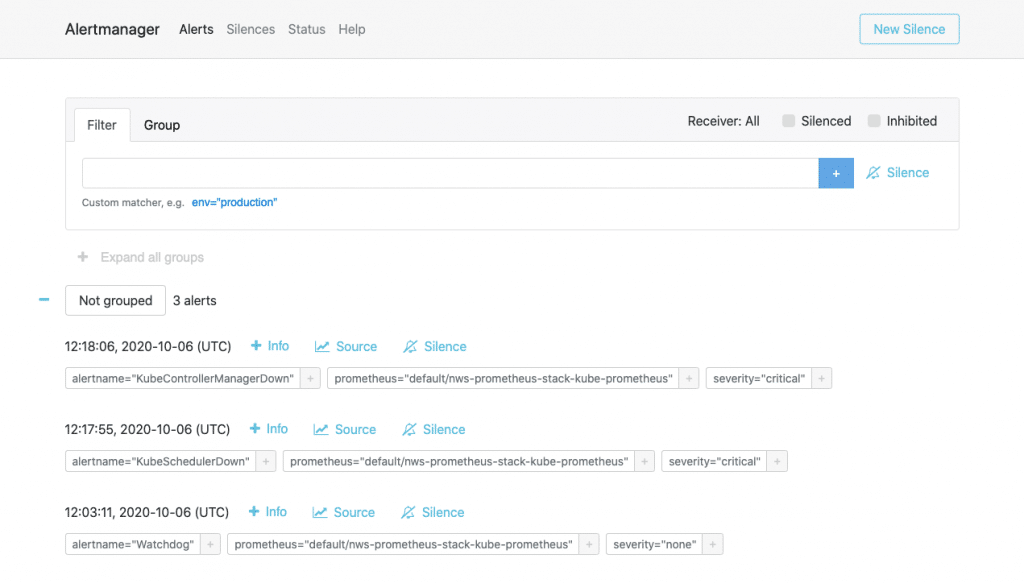
Das Webinterface (unter http://localhost:3004/ erreichbar) ähnelt dem von Prometheus. Unter Alerts hat man hingegen eine History der bereits abgefeuerten Alarme. Silences zeigt eine Übersicht der unterdrückten Alerts und Status enthält neben Versionsinfos und dem Betriebsstatus auch die aktuelle Config des Alertmanagers. Leider lässt sich diese Config hier jedoch auch nicht ändern. Wie konfigurieren wir nun also den Alertmanager?
Den Alertmanager konfigurieren
Manche werden es schon erahnt haben: indem man die Values des Helm-Charts anpasst. Wir schreiben also eine neue Values-Datei, die ausschließlich die Alertmanager-Config enthält. Die Doku zeigt uns welche Optionen es gibt und nach welchem Schema sich diese setzen lassen. Wir fangen mit einem grundlegenden Beispiel an und fügen erstmal globale SMTP-Settings hinzu: alertmanager-v1.values
alertmanager:
config:
global:
resolve_timeout: 5m
smtp_from: k8s-alertmanager@example.com
smtp_smarthost: mail.example.com:587
smtp_require_tls: true
smtp_auth_username: k8s-alertmanager@example.com
smtp_auth_password: xxxxxxxxx
route:
receiver: 'k8s-admin'
routes: []
receivers:
- name: 'k8s-admin'
email_configs:
- to: k8s-admin@example.com
Dadurch kann der Alertmanager dann schon mal E-Mails herausschicken. Zudem ist es natürlich auch notwendig mindestens einen Empfänger zu definieren. Unter „receivers“ kann man wie in meinem Beispiel einfach Namen und E-Mailadresse hinterlegen. Bitte darauf achten, dass die Texteinrückung stimmt, ansonsten kann es beim Ausrollen der Config zu Startproblemen des Alertmanagers kommen. Damit nun die Zustellung der Alerts auch wirklich stattfindet muss man unter „route“ die Routen festlegen. Wenn man erstmal alle feuernden Alarme an einen Kontakt rausschicken möchte, dann kann man das wie in meinem Beispiel machen. Was man noch so alles mit Routen anstellen kann, das sehen wir uns in einem späteren Beispiel genauer an. Mit einem Helm Upgrade können wir unsere neue Konfiguration für den Alertmanager deployen. Wir übernehmen dabei alle bereits gesetzten Werte mittels „–reuse-values“:
helm upgrade --reuse-values -f prom-config/alertmanager-v1.values nws-prometheus-stack prometheus-community/kube-prometheus-stack
Und wie testen wir das jetzt?
Alerts testen
Wer nicht gleich einen Node abschießen möchte kann einfach mal den Alertmanager neu starten. Beim Start feuert nämlich die Alert-Rule „Watchdog“. Diese ist nur dazu da, um die ordnungsgemäße Funktion der Alertingpipeline zu testen. So kannst du den Neustart durchführen:
kubectl rollout restart statefulset.apps/alertmanager-nws-prometheus-stack-kube-alertmanager
Kurz nach dem Neustart sollte auch schon die E-Mail ankommen. Falls nicht, dann erst einmal prüfen ob der Alertmanager noch startet. Wenn er in einem Crash-Loop hängt, dann kann man über die Logs des Pods herausfinden, was hier schief läuft. Ist eine Konfig-Option falsch gesetzt, kannst du diese in den Values nochmal anpassen und erneut mit einem Helm Upgrade deployen. Wer sich bei einem Optionskey vertippt hat, kann per Helm Rollback auch auf einen vorherigen Stand zurück rollen:
helm rollback nws-prometheus-stack 1
Damit haben wir schon mal ein rudimentäres Monitoring für den Kubernetes Cluster selbst. Natürlich kann man noch weitere Receiver hinterlegen und somit auch mehrere Kontakte benachrichtigen.
Eigene Metriken und Alert Rules hinzufügen
Jetzt sehen wir uns noch an, für was die Routen nützlich sein können. Allerdings werden wir uns dazu erst noch ein paar Pods zum Testen hochfahren und verschiedene Namespaces anlegen. Zudem sehen wir uns auch noch kurz den Prometheus Blackbox Exporter an. Szenario: In einem K8s-Cluster werden verschiedene Environments per Namespaces betrieben – z.B. development und production.Wenn die sample-app des Namespaces development ausfällt, dann soll nicht die Bereitschaft alarmiert werden.Die Bereitschaft ist nur für Ausfälle der sample-app des Production-Namespaces zuständig und bekommt neben E-Mails auch Benachrichtigungen aufs Mobiltelefon. Die Entwickler werden gesondert per Mail über Probleme bei der sample-app aus dem development Namespace informiert. Wir definieren die beiden Namespaces nws-production und nws-development in namespaces-nws.yaml:
apiVersion: v1
kind: Namespace
metadata:
name: nws-development
labels:
name: nws-development
---
apiVersion: v1
kind: Namespace
metadata:
name: nws-production
labels:
name: nws-production
kubectl apply -f ./prom-config/namespaces-nws.yaml
Nun starten wir uns zwei sample-apps, die uns abwechselnd in einem 60 Sekunden Intervall HTTP 200 und HTTP 500 zurück liefern. Ich verwendet hier ein einfaches Image, das ich mir für diesen Zweck erstellt habe (Sourcen auf GitHub). sample-app.yaml:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nws-sample-app
spec:
replicas: 1
selector:
matchLabels:
app: nws-sample-app
template:
metadata:
labels:
app: nws-sample-app
spec:
containers:
- name: nws-sample-app
image: gagaha/alternating-http-response
ports:
- containerPort: 80
kubectl apply -f prom-config/sample-app.yaml -n nws-production kubectl apply -f prom-config/sample-app.yaml -n nws-development
Anschließend exposen wir die App im Cluster:
kubectl expose deployment nws-sample-app -n nws-production kubectl expose deployment nws-sample-app -n nws-development
Nun brauchen wir allerdings noch einen Komponente, die die Verfügbarkeit dieser Apps per HTTP Request abfragen kann und als Metriken für Prometheus bereitstellt. Es bietet sich hierfür der Prometheus Blackbox Exporter an. Damit kann man neben HTTP/HTTPS Anfragen auch Verbindungen mit den Protokollen DNS, TCP und ICMP prüfen. Zuerst müssen wir den Blackbox Exporter im Cluster deployen. Ich bediene mich auch hier wieder dem offiziellen Helm Chart.
helm install nws-blackbox-exporter prometheus-community/prometheus-blackbox-exporter
Nun müssen wir Prometheus noch mitteilen, wie er an den Blackbox Exporter kommt. Interessant sind hier die Targets. Hier tragen wir die HTTP Endpoints ein, die vom Blackbox Exporter abgefragt werden sollen. Wir schreiben die zusätzliche Konfiguration in eine Datei und deployen sie per Helm Upgrade: prom-blackbox-scrape.yaml
prometheus:
prometheusSpec:
additionalScrapeConfigs:
- job_name: 'nws-blackbox-exporter'
metrics_path: /probe
params:
module: [http_2xx]
static_configs:
- targets:
- http://nws-sample-app.nws-production.svc
- http://nws-sample-app.nws-development.svc
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: nws-blackbox-exporter-prometheus-blackbox-exporter:9115
helm upgrade --reuse-values -f prom-config/prom-blackbox-scrape.yaml nws-prometheus-stack prometheus-community/kube-prometheus-stack
Wenn wir dann nochmal den Port-Forward für prometheus starten, können wir unter http://localhost:3003/targets die beiden neuen Targets des nws-blackbox-exporters sehen. Somit kommen schon mal Metriken zu Prometheus rein. Wir müssen allerdings auch neue Alert Rules definieren, damit für diese Metriken alarmiert werden kann. Wir editieren die Rules direkt per Kubectl:
kubectl edit prometheusrules nws-prometheus-stack-kube-k8s.rules
Vor den k8s.rules fügen wir unsere neue Regel hinzu:
...
spec:
groups:
- name: blackbox-exporter
rules:
- alert: HttpStatusCode
annotations:
description: |-
HTTP status code is not 200-399
VALUE = {{ $value }}
LABELS: {{ $labels }}
summary: HTTP Status Code (instance {{ $labels.instance }})
expr: probe_http_status_code <= 199 OR probe_http_status_code >= 400
for: 30s
labels:
severity: error
- name: k8s.rules
rules:
...
Jetzt müssen wir nur noch die Kontaktdaten der verschiedenen Empfänger und Routen definieren. Unter route kann man in routes verschiedene Empfänger angeben. Diese Empfänger müssen natürlich weiter unten auch vorhanden sein. Es kann dann für eine Route auch Bedingungen definiert werden. Nur wenn die Bedingungen auch zutreffen, wird die Benachrichtigung an den angegebenen Empfänger verschickt. Hier nun die Config für das Szenario: alertmanager-v2.values
alertmanager:
config:
global:
resolve_timeout: 5m
smtp_from: k8s-alertmanager@example.com
smtp_smarthost: mail.example.com:587
smtp_require_tls: true
smtp_auth_username: k8s-alertmanager@example.com
smtp_auth_password: xxxxxxxxx
route:
receiver: 'k8s-admin'
repeat_interval: 5m
routes:
- receiver: 'dev_mail'
match:
instance: http://nws-sample-app.nws-development.svc
- receiver: 'bereitschaft'
match:
instance: http://nws-sample-app.nws-production.svc
receivers:
- name: 'k8s-admin'
email_configs:
- to: k8s-admin@example.com
- name: 'dev_mail'
email_configs:
- to: devs@example.com
- name: 'bereitschaft'
email_configs:
- to: bereitschaft@example.com
pushover_configs:
- user_key: xxxxxxxxxxxxxxxxxxxxxxxxxxx
token: xxxxxxxxxxxxxxxxxxxxxxxxxxxxx
helm upgrade --reuse-values -f prom-config/alertmanager-v2.values nws-prometheus-stack prometheus-community/kube-prometheus-stack
Am besten man löst danach wieder einen Neustart des Alertmanagers aus:
kubectl rollout restart statefulset.apps/alertmanager-nws-prometheus-stack-kube-alertmanager
Sofern die Konfiguration passt, sollten dann schon bald Alerts ankommen.
Fazit
Das Einrichten des Alertmanagers kann aufwändig sein. Man hat jedoch auch viele Konfigurationsmöglichkeiten und kann sich seine Benachrichtigungen über Regeln so zurechtlegen wie man es benötigt. Wer möchte kann auch noch die Templates der Nachrichten bearbeiten und somit das Format und die enthalten Informationen anpassen.









