
Monitoring – für viele eine gewisse Hass-Liebe. Die einen mögen es, die anderen verteufeln es. Ich gehöre zu denen, die es meist eher verteufeln, dann aber meckern, wenn man gewisse Metriken und Informationen nicht einsehen kann. Unabhängig der persönlichen Neigungen zu diesem Thema ist der Konsens aller jedoch sicher: Monitoring ist wichtig und ein Setup ist auch nur so gut wie sein dazugehöriges Monitoring. Wer seine Anwendungen auf Basis von Kubernetes entwickeln und betreiben will, stellt sich zwangsläufig früher oder später die Frage, wie man diese Anwendungen und den Kubernetes Cluster überwachen kann. Eine Variante ist der Einsatz der Monitoringlösung Prometheus; genauer gesagt durch die Verwendung des Kubernetes Prometheus Operators. Eine beispielhafte und funktionale Lösung wird in diesem Blogpost gezeigt.
Kubernetes Operator
Kubernetes Operators sind kurz erklärt Erweiterungen, mit denen sich eigene Ressourcentypen erstellen lassen. Neben den Standard-Kubernetes-Ressourcen wie Pods, DaemonSets, Services usw. kann man mit Hilfe eines Operators auch eigene Ressourcen nutzen. In unserem Beispiel kommen neu hinzu: Prometheus, ServiceMonitor und weitere. Operators sind dann von großem Nutzen, wenn man für seine Anwendung spezielle manuelle Tasks ausführen muss, um sie ordentlich betreiben zu können. Das könnten beispielsweise Datenbank-Schema-Updates bei Versionsupdates sein, spezielle Backupjobs oder das Steuern von Ereignissen in verteilten Systemen. In der Regel laufen Operators – wie gewöhnliche Anwendungen auch – als Container innerhalb des Clusters.
Wie funktioniert es?
Die Grundidee ist, dass mit dem Prometheus Operator ein oder viele Prometheus-Instanzen gestartet werden, die wiederum durch den ServiceMonitor dynamisch konfiguriert werden. Das heißt, es kann an einem gewöhnlichen Kubernetes Service mit einem ServiceMonitor angedockt werden, der wiederum ebenfalls die Endpoints auslesen kann und die zugehörige Prometheus-Instanz entsprechend konfiguriert. Verändern sich der Service respektive die Endpoints, zum Beispiel in der Anzahl oder die Endpoints haben neue IPs, erkennt das der ServiceMonitor und konfiguriert die Prometheus-Instanz jedes Mal neu. Zusätzlich kann über Configmaps auch eine manuelle Konfiguration vorgenommen werden.
Voraussetzungen
Voraussetzung ist ein funktionierendes Kubernetes Cluster. Für das folgende Beispiel verwende ich einen NWS Managed Kubernetes Cluster in der Version 1.16.2.
Installation Prometheus Operator
Zuerst wird der Prometheus-Operator bereitgestellt. Es werden ein Deployment, eine benötigte ClusterRole mit zugehörigem ClusterRoleBinding und einem ServiceAccount definiert.
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
app.kubernetes.io/component: controller
app.kubernetes.io/name: prometheus-operator
app.kubernetes.io/version: v0.38.0
name: prometheus-operator
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus-operator
subjects:
- kind: ServiceAccount
name: prometheus-operator
namespace: default
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
app.kubernetes.io/component: controller
app.kubernetes.io/name: prometheus-operator
app.kubernetes.io/version: v0.38.0
name: prometheus-operator
rules:
- apiGroups:
- apiextensions.k8s.io
resources:
- customresourcedefinitions
verbs:
- create
- apiGroups:
- apiextensions.k8s.io
resourceNames:
- alertmanagers.monitoring.coreos.com
- podmonitors.monitoring.coreos.com
- prometheuses.monitoring.coreos.com
- prometheusrules.monitoring.coreos.com
- servicemonitors.monitoring.coreos.com
- thanosrulers.monitoring.coreos.com
resources:
- customresourcedefinitions
verbs:
- get
- update
- apiGroups:
- monitoring.coreos.com
resources:
- alertmanagers
- alertmanagers/finalizers
- prometheuses
- prometheuses/finalizers
- thanosrulers
- thanosrulers/finalizers
- servicemonitors
- podmonitors
- prometheusrules
verbs:
- '*'
- apiGroups:
- apps
resources:
- statefulsets
verbs:
- '*'
- apiGroups:
- ""
resources:
- configmaps
- secrets
verbs:
- '*'
- apiGroups:
- ""
resources:
- pods
verbs:
- list
- delete
- apiGroups:
- ""
resources:
- services
- services/finalizers
- endpoints
verbs:
- get
- create
- update
- delete
- apiGroups:
- ""
resources:
- nodes
verbs:
- list
- watch
- apiGroups:
- ""
resources:
- namespaces
verbs:
- get
- list
- watch
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app.kubernetes.io/component: controller
app.kubernetes.io/name: prometheus-operator
app.kubernetes.io/version: v0.38.0
name: prometheus-operator
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/component: controller
app.kubernetes.io/name: prometheus-operator
template:
metadata:
labels:
app.kubernetes.io/component: controller
app.kubernetes.io/name: prometheus-operator
app.kubernetes.io/version: v0.38.0
spec:
containers:
- args:
- --kubelet-service=kube-system/kubelet
- --logtostderr=true
- --config-reloader-image=jimmidyson/configmap-reload:v0.3.0
- --prometheus-config-reloader=quay.io/coreos/prometheus-config-reloader:v0.38.0
image: quay.io/coreos/prometheus-operator:v0.38.0
name: prometheus-operator
ports:
- containerPort: 8080
name: http
resources:
limits:
cpu: 200m
memory: 200Mi
requests:
cpu: 100m
memory: 100Mi
securityContext:
allowPrivilegeEscalation: false
nodeSelector:
beta.kubernetes.io/os: linux
securityContext:
runAsNonRoot: true
runAsUser: 65534
serviceAccountName: prometheus-operator
---
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
app.kubernetes.io/component: controller
app.kubernetes.io/name: prometheus-operator
app.kubernetes.io/version: v0.38.0
name: prometheus-operator
namespace: default
---
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/component: controller
app.kubernetes.io/name: prometheus-operator
app.kubernetes.io/version: v0.38.0
name: prometheus-operator
namespace: default
spec:
clusterIP: None
ports:
- name: http
port: 8080
targetPort: http
selector:
app.kubernetes.io/component: controller
app.kubernetes.io/name: prometheus-operator
kubectl apply -f 00-prometheus-operator.yaml clusterrolebinding.rbac.authorization.k8s.io/prometheus-operator created clusterrole.rbac.authorization.k8s.io/prometheus-operator created deployment.apps/prometheus-operator created serviceaccount/prometheus-operator created service/prometheus-operator created
Role Based Access Control
Zusätzlich werden entsprechende Role Based Access Control (RBAC) Policies benötigt. Die Prometheus-Instanzen (StatefulSets), gestartet durch den Prometheus-Operator, starten Container unter dem gleichnamigen ServiceAccount „Prometheus“. Dieser Account benötigt lesenden Zugriff auf die Kubernetes API, um später die Informationen über Services und Endpoints auslesen zu können.
Clusterrole
apiVersion: rbac.authorization.k8s.io/v1beta1 kind: ClusterRole metadata: name: prometheus rules: - apiGroups: [""] resources: - nodes - services - endpoints - pods verbs: ["get", "list", "watch"] - apiGroups: [""] resources: - configmaps verbs: ["get"] - nonResourceURLs: ["/metrics"] verbs: ["get"]
kubectl apply -f 01-clusterrole.yaml clusterrole.rbac.authorization.k8s.io/prometheus created
ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1 kind: ClusterRoleBinding metadata: name: prometheus roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: prometheus subjects: - kind: ServiceAccount name: prometheus namespace: default
kubectl apply -f 01-clusterrolebinding.yaml clusterrolebinding.rbac.authorization.k8s.io/prometheus created
ServiceAccount
apiVersion: v1 kind: ServiceAccount metadata: name: prometheus
kubectl apply -f 01-serviceaccount.yaml serviceaccount/prometheus created
Monitoring von Kubernetes Cluster Nodes
Es gibt diverse Metriken, die aus einem Kubernetes Cluster ausgelesen werden können. In diesem Beispiel wird zunächst nur auf die Systemwerte der Kubernetes Nodes eingegangen. Für die Überwachung der Kubernetes Cluster Nodes bietet sich die ebenfalls vom Prometheus-Projekt bereitgestellte Software „Node Exporter“ an. Diese liest sämtliche Metriken über CPU, Memory sowie I/O aus und stellt diese Werte unter /metrics zum Abruf bereit. Prometheus selbst „crawlet“ diese Metriken später in regelmäßigen Abständen. Ein DaemonSet steuert, dass jeweils ein Container/Pod auf einem Kubernetes Node gestartet wird. Mit Hilfe des Services werden alle Endpoints unter einer Cluster IP zusammengefasst.
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-exporter
spec:
selector:
matchLabels:
app: node-exporter
template:
metadata:
labels:
app: node-exporter
name: node-exporter
spec:
hostNetwork: true
hostPID: true
containers:
- image: quay.io/prometheus/node-exporter:v0.18.1
name: node-exporter
ports:
- containerPort: 9100
hostPort: 9100
name: scrape
resources:
requests:
memory: 30Mi
cpu: 100m
limits:
memory: 50Mi
cpu: 200m
volumeMounts:
- name: proc
readOnly: true
mountPath: /host/proc
- name: sys
readOnly: true
mountPath: /host/sys
volumes:
- name: proc
hostPath:
path: /proc
- name: sys
hostPath:
path: /sys
---
apiVersion: v1
kind: Service
metadata:
labels:
app: node-exporter
annotations:
prometheus.io/scrape: 'true'
name: node-exporter
spec:
ports:
- name: metrics
port: 9100
protocol: TCP
selector:
app: node-exporter
kubectl apply -f 02-exporters.yaml daemonset.apps/node-exporter created service/node-exporter created
Service Monitor
Mit der sogenannten Third Party Ressource „ServiceMonitor“, bereitgestellt durch den Prometheus Operator, ist es möglich, den zuvor gestarteten Service, in unserem Fall node-exporter, für die zukünftige Überwachung aufzunehmen. Die TPR selbst erhält ein Label team: frontend, das wiederum später als Selector für die Prometheus-Instanz genutzt wird.
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: node-exporter
labels:
team: frontend
spec:
selector:
matchLabels:
app: node-exporter
endpoints:
- port: metrics
kubectl apply -f 03-service-monitor-node-exporter.yaml servicemonitor.monitoring.coreos.com/node-exporter created
Prometheus-Instanz
Es wird eine Prometheus-Instanz definiert, die nun alle Services anhand der Labels sammelt und von deren Endpoints die Metriken bezieht.
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
name: prometheus
spec:
serviceAccountName: prometheus
serviceMonitorSelector:
matchLabels:
team: frontend
resources:
requests:
memory: 400Mi
enableAdminAPI: false
kubectl apply -f 04-prometheus-service-monitor-selector.yaml prometheus.monitoring.coreos.com/prometheus created
Prometheus Service
Die gestartete Prometheus-Instanz wird mit einem Service-Objekt exponiert. Nach einer kurzen Wartezeit ist ein Cloud-Loadbalancer gestartet, der aus dem Internet erreichbar ist und Anfragen zu unserer Prometheus-Instanz durchreicht.
apiVersion: v1
kind: Service
metadata:
name: prometheus
spec:
type: LoadBalancer
ports:
- name: web
port: 9090
protocol: TCP
targetPort: web
selector:
prometheus: prometheus
kubectl apply -f 05-prometheus-service.yaml service/prometheus created kubectl get services NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE prometheus LoadBalancer 10.254.146.112 pending 9090:30214/TCP 58s
Sobald die externe IP-Adresse verfügbar ist, kann diese über http://x.x.x.x:9090/targets aufgerufen werden und man sieht alle seine Kubernetes Nodes, deren Metriken ab sofort regelmäßig abgerufen werden. Kommen später weitere Nodes hinzu, so werden diese automatisch mit aufgenommen bzw. wieder entfernt. 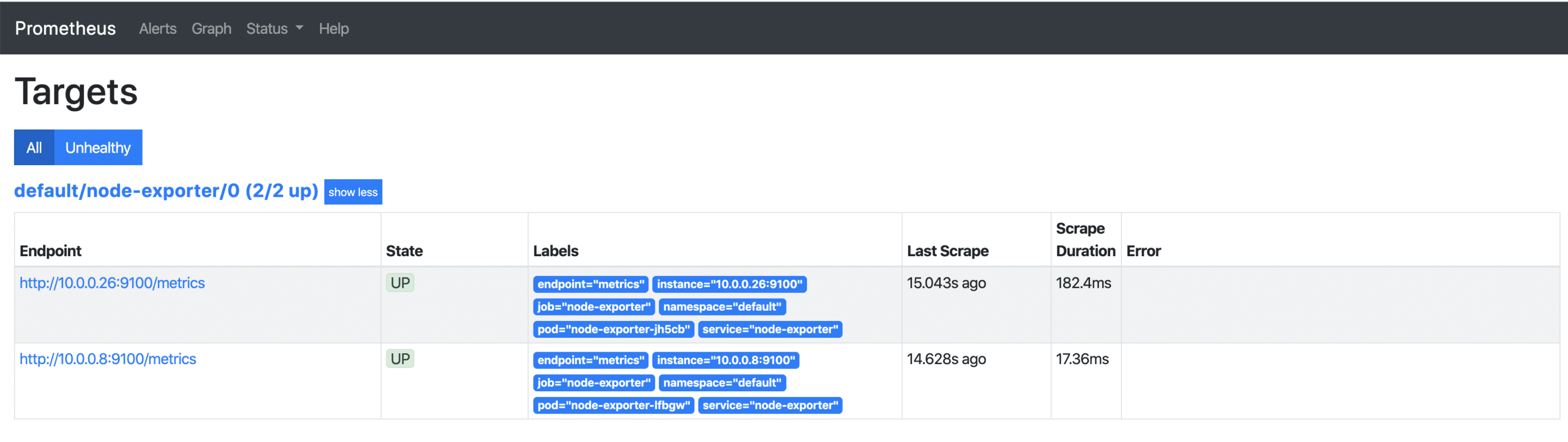
Visualisierung mit Grafana
Die gesammelten Metriken, lassen sich leicht und ansprechend mit Grafana visualisieren. Grafana ist ein Analyse-Tool, das diverse Datenbackends unterstützt.
apiVersion: v1
kind: Service
metadata:
name: grafana
spec:
# type: LoadBalancer
ports:
- port: 3000
targetPort: 3000
selector:
app: grafana
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: grafana
name: grafana
spec:
selector:
matchLabels:
app: grafana
replicas: 1
revisionHistoryLimit: 2
template:
metadata:
labels:
app: grafana
spec:
containers:
- image: grafana/grafana:latest
name: grafana
imagePullPolicy: Always
ports:
- containerPort: 3000
env:
- name: GF_AUTH_BASIC_ENABLED
value: "false"
- name: GF_AUTH_ANONYMOUS_ENABLED
value: "true"
- name: GF_AUTH_ANONYMOUS_ORG_ROLE
value: Admin
- name: GF_SERVER_ROOT_URL
value: /api/v1/namespaces/default/services/grafana/proxy/
kubectl apply -f grafana.yaml service/grafana created deployment.apps/grafana created kubectl proxy Starting to serve on 127.0.0.1:8001
Sobald die Proxy-Verbindung durch kubectl verfügbar ist, kann die gestartete Grafana-Instanz via http://localhost:8001/api/v1/namespaces/default/services/grafana/proxy/ im Browser aufgerufen werden. Damit die in Prometheus vorliegenden Metriken jetzt auch visuell ansprechend dargestellt werden können, sind nur noch wenige weitere Schritte notwendig. Zuerst wird eine neue Data-Source vom Typ Prometheus angelegt. Dank des kuberneteseigenen und -internen DNS lautet die URL http://prometheus.default.svc:9090. Das Schema ist servicename.namespace.svc. Alternativ kann natürlich auch die Cluster-IP verwendet werden. 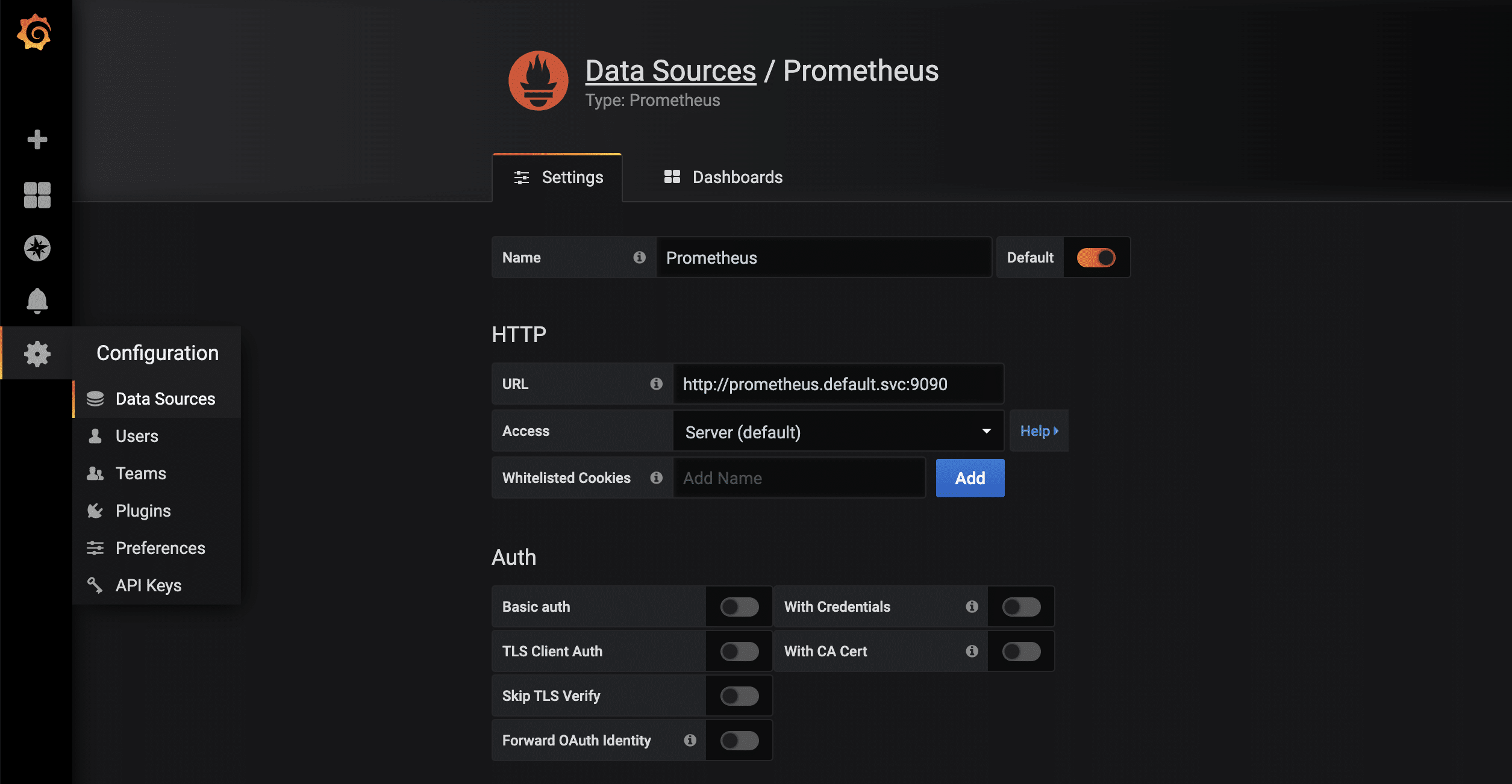 Für die gesammelten Metriken des node-exporters gibt es bereits ein sehr vollständiges Grafana-Dashboard, das sich über die Import-Funktion importieren lässt. Die ID des Dashboards ist 1860.
Für die gesammelten Metriken des node-exporters gibt es bereits ein sehr vollständiges Grafana-Dashboard, das sich über die Import-Funktion importieren lässt. Die ID des Dashboards ist 1860. 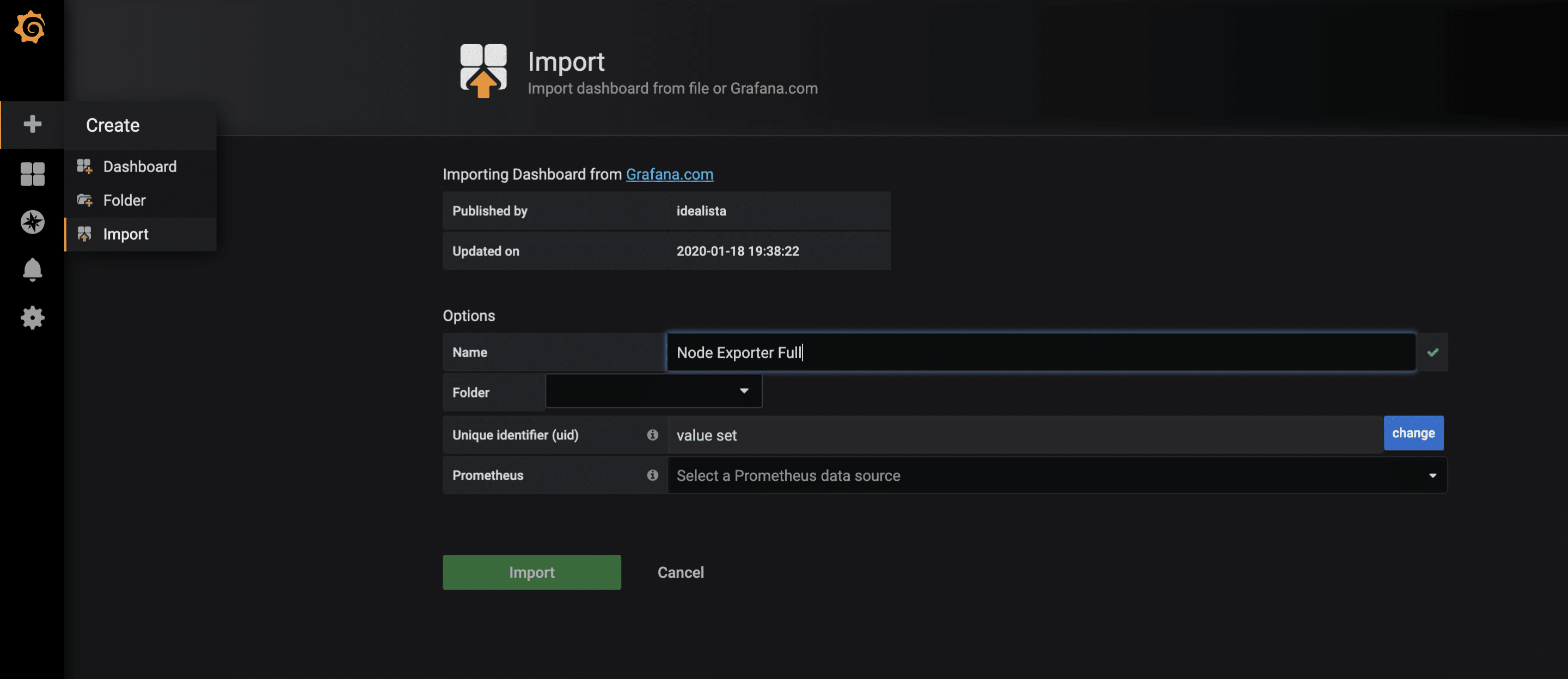 Nach dem erfolgreichem Import des Dashboards können jetzt die Metriken begutachtet werden.
Nach dem erfolgreichem Import des Dashboards können jetzt die Metriken begutachtet werden. 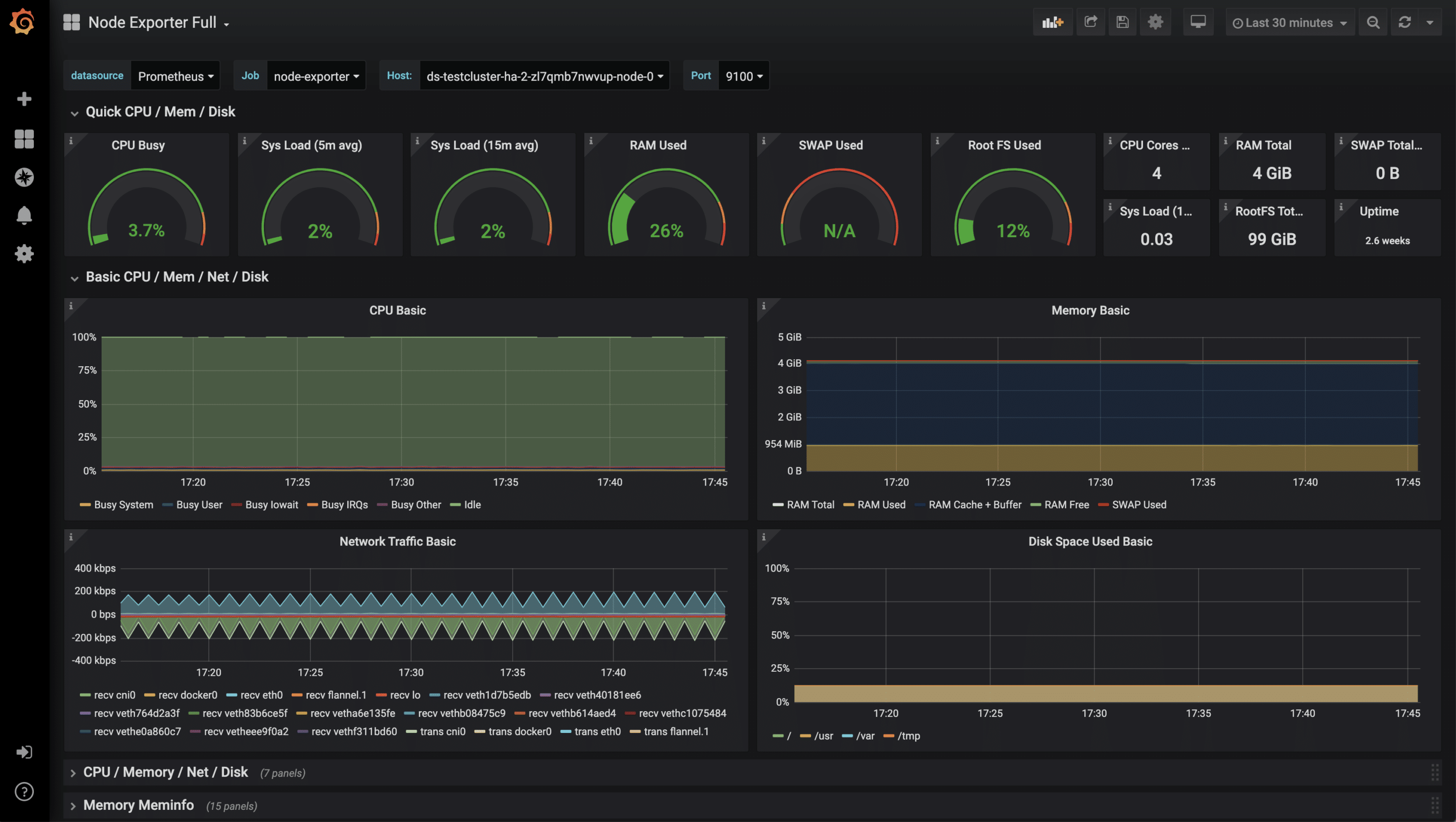
Monitoring weiterer Anwendungen
Neben diesen eher technischen Statistiken sind auch weitere Metriken der eigenen Anwendungen möglich, beispielsweise HTTP Requests, SQL Queries, Business-Logik und vieles mehr. Hier werden einem durch das sehr flexible Datenformat kaum Grenzen gesetzt. Um seine eigenen Metriken zu sammeln, gibt es wie immer mehrere Lösungsansätze. Einer davon ist, seine Anwendung mit einem /metrics Endpunkt auszustatten. Manche Frameworks wie z.B. Ruby on Rails haben bereits brauchbare Erweiterungen. Ein weiterer Ansatz sind sogenannte Sidecars. Ein Sidecar ist ein zusätzlicher Container, der neben dem eigentlichen Anwendungscontainer mitläuft. Beide zusammen ergeben einen Pod, der sich Namespace, Netzwerk etc. teilt. In dem Sidecar läuft dann Code, der die Anwendung prüft und die Ergebnisse als parsebare Werte für Prometheus zur Verfügung stellt. Im Wesentlichen können beide Ansätze, wie im oben gezeigten Beispiel, mit dem Prometheus Operator verknüpft werden.









